
技术摘要:
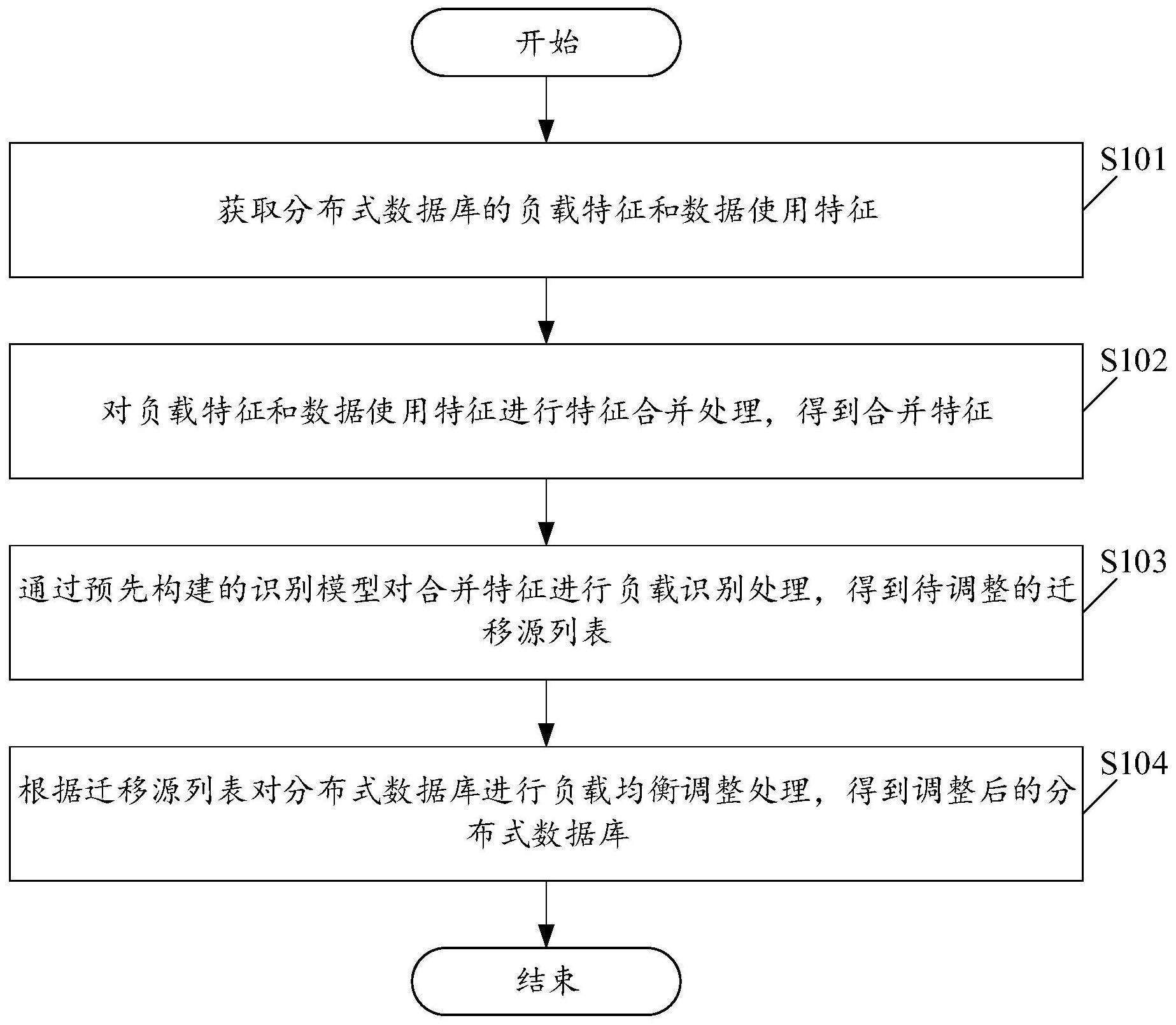
本申请实施例提供一种基于分布式数据库的负载均衡调整方法及装置,涉及计算机技术领域,该方法包括:获取分布式数据库的负载特征和数据使用特征;对负载特征和数据使用特征进行特征合并处理,得到合并特征;通过预先构建的识别模型对合并特征进行负载识别处理,得到待 全部
背景技术:
分布式数据库是基于单节点数据库的基础上发展起来的,是计算机技术、数据存 储技术和网络技术结合的产物。在实际应用中发现,由于数据的使用热度不同,通常会导致 某些存储节点的访问压力过大,造成机器损坏,引发数据库集群的短板问题。
技术实现要素:
本申请实施例的目的在于提供一种基于分布式数据库的负载均衡调整方法及装 置,用以解决由于数据的使用热度不同导致存储节点访问压力过大的问题,达到分布式数 据库负载均衡的效果,进而提升集群的读写性能。 本申请实施例第一方面提供了一种基于分布式数据库的负载均衡调整方法,其特 征在于,包括: 获取所述分布式数据库的负载特征和数据使用特征; 对所述负载特征和所述数据使用特征进行特征合并处理,得到合并特征; 通过预先构建的识别模型对所述合并特征进行负载识别处理,得到待调整的迁移 源列表; 根据所述迁移源列表对所述分布式数据库进行负载均衡调整处理,得到调整后的 分布式数据库。 在上述实现过程中,该方法可以优先获取分布式数据库的负载特征和数据使用特 征;然后再对负载特征和数据使用特征进行特征合并处理,得到合并特征;在获取到合并特 征之后,通过预先构建的识别模型对合并特征进行负载识别处理,得到待调整的迁移源列 表;最后,根据迁移源列表对分布式数据库进行负载均衡调整处理,得到调整后的分布式数 据库。可见,实施这种实施方式,能够将分布式数据库中的集群节点负载信息作为负载特 征,将分布式数据库中节点高热度数据的数据量信息作为数据使用特征,然后合并上述两 种特征得到合并特征,以使识别模型可以根据该合并特征进行负载识别,得到相应的迁移 源列表,然后再进一步根据该迁移源列表对分布式数据库进行负载均衡处理,得到调整后 的分布式数据库,从而能够实现对分布式数据库的负载均衡,进而能够解决由于数据的使 用热度不同导致存储节点访问压力过大的问题,达到分布式数据库负载均衡的效果,提升 数据集群的读写性能。 进一步地,在所述获取所述分布式数据库的负载特征和数据使用特征之前,所述 方法还包括: 构建原始识别模型; 获取用于训练所述原始识别模型的训练特征数据; 4 CN 111611228 A 说 明 书 2/11 页 对所述训练特征数据进行特征归一化处理,得到归一化特征数据; 通过所述归一化特征数据对所述原始识别模型进行模型训练,得到识别模型。 在上述实现过程中,该方法还以可以在获取分布式数据库的负载特征和数据使用 特征之前,优先构建原始识别模型;然后获取用于训练原始识别模型的训练特征数据;进而 对训练特征数据进行特征归一化处理,得到归一化特征数据;最后通过归一化特征数据对 原始识别模型进行模型训练,得到识别模型。可见,实施这种实施方式,该方法可以在特征 获取之前预先建立用于进行负载识别处理的识别模型,从而使得识别模型可以根据实际情 况实时建立,并且实时使用,进而提高该基于分布式数据库的负载均衡调整方法的应用实 时性,提高分布式数据库的调整调率。 进一步地,所述通过预先构建的识别模型对所述合并特征进行负载识别处理,得 到待调整的迁移源列表,包括: 获取所述分布式数据库的所有节点列表; 将所述合并特征输入至预先构建的识别模型中,输出处理结果; 根据所述处理结果从所述所有节点列表中选择出所有待调整的节点,得到初始迁 移源列表; 对所述初始迁移源列表中每个节点进行排序处理,得到待调整的迁移源列表。 在上述实现过程中,该方法在获取待调整的迁移源列表的过程中,可以优先获取 分布式数据库的所有节点列表;然后将合并特征输入至预先构建的识别模型中,以使识别 模型输出相应的处理结果;该方法在获取到处理结果之后,根据该处理结果从所有节点列 表中选择出所有待调整的节点,得到初始迁移源列表;然后再对初始迁移源列表中每个节 点进行排序处理,得到待调整的迁移源列表。可见,实施这种实施方式,该方法可以通过识 别模型来对合并特征进行处理,得到处理结果,然后再根据处理结果在分布式数据库中的 节点列表中提取出初始迁移源列表,然后再对节点记性排序得到待调整的迁移源列表,从 而实现迁移源列表的准确获取,从而提高了对分布式负载的均衡调整效果。 进一步地,所述根据所述迁移源列表对所述分布式数据库进行负载均衡调整处 理,得到调整后的分布式数据库,包括: 获取上一次进行负载均衡调整时的存储迁移目的列表、上一次进行负载均衡调整 时使用率最高的数据类别以及上一次进行负载均衡调整时使用率最低的数据类别; 根据所述存储迁移目的列表和所述使用率最高的数据类别对所述迁移源列表中 每个节点的存储数据进行数据迁移处理,得到初步调整的分布式数据库; 在所述初步调整的分布式数据库的基础上,根据所述存储迁移目的列表和所述使 用率最低的数据类别对所述迁移源列表中每个节点的存储数据进行数据回迁处理,得到调 整后的分布式数据库。 在上述实现过程中,该方法在获取调整后的分布式数据库的过程中,可以优先获 取上一次进行负载均衡调整时的存储迁移目的列表、上一次进行负载均衡调整时使用率最 高的数据类别以及上一次进行负载均衡调整时使用率最低的数据类别;然后,再根据存储 迁移目的列表和使用率最高的数据类别对迁移源列表中每个节点的存储数据进行数据迁 移处理,得到初步调整的分布式数据库;最后,再在初步调整的分布式数据库的基础上,根 据存储迁移目的列表和使用率最低的数据类别对迁移源列表中每个节点的存储数据进行 5 CN 111611228 A 说 明 书 3/11 页 数据回迁处理,得到调整后的分布式数据库。可见,实施这种实施方式,分布式数据库可以 根据历史数据进行更新调整,从而实现高效准确的调整分布式数据库的效果。 进一步地,所述负载特征包括所述分布式数据库的每个节点的负载均值,所述负 载均值包括中央处理器负载均值、机器负载均值、内存负载均值中的一种或者多种; 所述数据使用特征包括所述分布式数据库中存储的每种类型数据的数据使用率。 在上述实现过程中,负载特征包括分布式数据库的每个节点中包括中央处理器负 载均值、机器负载均值、内存负载均值中的一种或者多种的负载均值;该负载均值可以通过 多个负载均值的各项数值来均衡调整调整分布式数据库,从而提高分布式数据库的均衡调 整效果;同时,数据使用特征包括分布式数据库中存储的每种类型数据的数据使用率,该每 种类型数据的数据使用率可以提高数据丰富程度,从而获取更准确的数据内容,进而提高 分布式数据库的均衡调整效果。 本申请实施例第二方面提供了一种基于分布式数据库的负载均衡调整装置,所述 负载均衡调整装置包括: 获取单元,用于获取所述分布式数据库的负载特征和数据使用特征; 合并单元,用于对所述负载特征和所述数据使用特征进行特征合并处理,得到合 并特征; 识别单元,用于通过预先构建的识别模型对所述合并特征进行负载识别处理,得 到待调整的迁移源列表; 调整单元,用于根据所述迁移源列表对所述分布式数据库进行负载均衡调整处 理,得到调整后的分布式数据库。 在上述实现过程中,该基于分布式数据库的负载均衡调整装置可以通过获取单元 来获取分布式数据库的负载特征和数据使用特征;再通过合并单元来对负载特征和数据使 用特征进行特征合并处理,得到合并特征;再通过识别单元来通过预先构建的识别模型对 合并特征进行负载识别处理,得到待调整的迁移源列表;再通过调整单元来根据迁移源列 表对分布式数据库进行负载均衡调整处理,得到调整后的分布式数据库。可见,实施这种实 施方式,能够将分布式数据库中的集群节点负载信息作为负载特征,将分布式数据库中节 点高热度数据的数据量信息作为数据使用特征,然后合并上述两种特征得到合并特征,以 使识别模型可以根据该合并特征进行负载识别,得到相应的迁移源列表,然后再进一步根 据该迁移源列表对分布式数据库进行负载均衡处理,得到调整后的分布式数据库,从而能 够实现对分布式数据库的负载均衡,进而能够解决由于数据的使用热度不同导致存储节点 访问压力过大的问题,达到分布式数据库负载均衡的效果,提升数据集群的读写性能。 进一步地,所述基于分布式数据库的负载均衡调整装置还包括: 构建单元,用于在所述获取所述分布式数据库的负载特征和数据使用特征之前, 构建原始识别模型; 数据获取单元,用于获取用于训练所述原始识别模型的训练特征数据; 归一化单元,用于对所述训练特征数据进行特征归一化处理,得到归一化特征数 据; 训练单元,用于通过所述归一化特征数据对所述原始识别模型进行模型训练,得 到识别模型。 6 CN 111611228 A 说 明 书 4/11 页 在上述实现过程中,该基于分布式数据库的负载均衡调整装置还可以通过构建单 元在获取分布式数据库的负载特征和数据使用特征之前,构建原始识别模型;再通过数据 获取单元来获取用于训练原始识别模型的训练特征数据;再通过归一化单元来对训练特征 数据进行特征归一化处理,得到归一化特征数据;再通过训练单元来通过归一化特征数据 对原始识别模型进行模型训练,得到识别模型。可见,实施这种实施方式,该方法可以在特 征获取之前预先建立用于进行负载识别处理的识别模型,从而使得识别模型可以根据实际 情况实时建立,并且实时使用,进而提高该基于分布式数据库的负载均衡调整方法的应用 实时性,提高分布式数据库的调整调率。 进一步地,所述识别单元包括: 获取子单元,用于获取所述分布式数据库的所有节点列表; 识别子单元,用于将所述合并特征输入至预先构建的识别模型中,输出处理结果; 选择子单元,用于根据所述处理结果从所述所有节点列表中选择出所有待调整的 节点,得到初始迁移源列表; 排序子单元,用于对所述初始迁移源列表中每个节点进行排序处理,得到待调整 的迁移源列表。 在上述实现过程中,所述识别单元可以通过获取子单元来获取所述分布式数据库 的所有节点列表;通过识别子单元将所述合并特征输入至预先构建的识别模型中,输出处 理结果;通过选择子单元来根据所述处理结果从所述所有节点列表中选择出所有待调整的 节点,得到初始迁移源列表;通过排序子单元来对所述初始迁移源列表中每个节点进行排 序处理,得到待调整的迁移源列表。可见,实施这种实施方式,该方法可以通过识别模型来 对合并特征进行处理,得到处理结果,然后再根据处理结果在分布式数据库中的节点列表 中提取出初始迁移源列表,然后再对节点记性排序得到待调整的迁移源列表,从而实现迁 移源列表的准确获取,从而提高了对分布式负载的均衡调整效果。 本申请实施例第三方面提供了一种电子设备,包括存储器以及处理器,所述存储 器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行本申请实 施例第一方面中任一项所述的基于分布式数据库的负载均衡调整方法。 本申请实施例第四方面提供了一种计算机可读存储介质,其存储有计算机程序指 令,所述计算机程序指令被一处理器读取并运行时,执行本申请实施例第一方面中任一项 所述的基于分布式数据库的负载均衡调整方法。 附图说明 为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例中所需要使 用的附图作简单地介绍,应当理解,以下附图仅示出了本申请的某些实施例,因此不应被看 作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以 根据这些附图获得其他相关的附图。 图1为本申请实施例提供的一种基于分布式数据库的负载均衡调整方法的流程示 意图; 图2为本申请实施例提供的另一种基于分布式数据库的负载均衡调整方法的流程 示意图; 7 CN 111611228 A 说 明 书 5/11 页 图3为本申请实施例提供的一种基于分布式数据库的负载均衡调整装置的结构示 意图; 图4为本申请实施例提供的另一种基于分布式数据库的负载均衡调整装置的结构 示意图。











