
技术摘要:
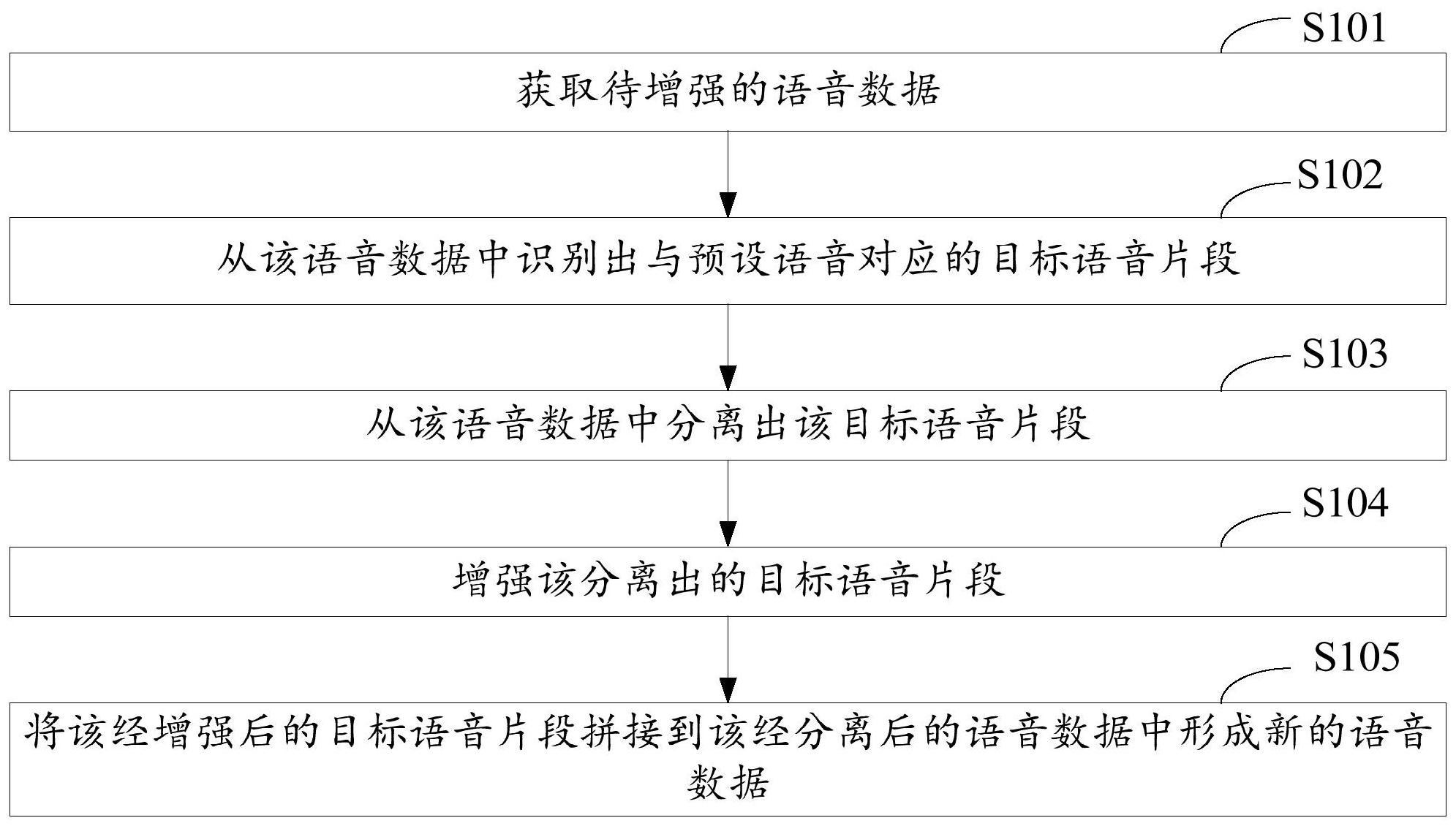
本发明公开了一种语音增强方法和装置以及设备。其中,所述方法包括:获取待增强的语音数据,和从该语音数据中识别出与预设语音对应的目标语音片段,和从该语音数据中分离出该目标语音片段,和增强该分离出的目标语音片段,以及将该经增强后的目标语音片段拼接到该经分 全部
背景技术:
语音增强是指当语音数据被各种各样的噪声干扰、甚至淹没后,从噪声背景中提 取有用的语音数据,抑制、降低噪声干扰的技术。 然而,现有的语音增强方案,一般是对整段语音数据进行增强,无法实现对整段语 音中的语音片段进行增强。
技术实现要素:
有鉴于此,本发明的目的在于提出一种语音增强方法和装置以及设备,能够实现 对整段语音中的语音片段进行增强。 根据本发明的一个方面,提供一种语音增强方法,包括:获取待增强的语音数据; 从所述语音数据中识别出与预设语音对应的目标语音片段;从所述语音数据中分离出所述 目标语音片段;增强所述分离出的目标语音片段;将所述经增强后的目标语音片段拼接到 所述经分离后的语音数据中形成新的语音数据。 其中,所述从所述语音数据中识别出与预设语音对应的目标语音片段,包括:采用 基于所述语音数据的声纹特征和预设语音数据的声纹特征,通过将所述语音数据中涵盖所 述预设语音数据的声纹特征最多且时间长度最短的语音片段作为目标语音片段的方式,从 所述语音数据中识别出与预设语音对应的目标语音片段。 其中,所述从所述语音数据中分离出所述目标语音片段,包括:采用提取所述目标 语音片段和所述语音数据的线性预测分析特征,和对所述线性预测分析特征进行归一化操 作,和将所述经归一化操作后的线性预测分析特征作为长短期记忆网络和卷积神经网络和 卷积神经网络的训练输入的方式,构建基于所述语音数据和所述目标语音片段的二分类模 型,和根据所述二分类模型,从所述语音数据中分离出所述目标语音片段。 其中,在所述将所述经增强后的目标语音片段拼接到所述经分离后的语音数据中 形成新的语音数据之后,还包括:对所述新的语音数据进行优化。 其中,所述对所述新的语音数据进行优化,包括:提取所述新的语音数据的短时短 时傅里叶变换特征和一阶短时傅里叶变换特征以及二阶短时傅里叶变换特征,通过交叉熵 损失的损失函数对所述短时傅里叶变换特征和一阶短时傅里叶变换特征以及二阶短时傅 里叶变换特征进行参数更新,通过所述经更新后的短时傅里叶变换特征和一阶短时傅里叶 变换特征以及二阶短时傅里叶变换特征采用预设次数的迭代方式,对所述新的语音数据进 行优化。 根据本发明的另一个方面,提供一种语音增强装置,包括:获取模块、识别模块、分 离模块、增强模块和拼接模块;所述获取模块,用于获取待增强的语音数据;所述识别模块, 用于从所述语音数据中识别出与预设语音对应的目标语音片段;所述分离模块,用于从所 4 CN 111583947 A 说 明 书 2/8 页 述语音数据中分离出所述目标语音片段;所述增强模块,用于增强所述分离出的目标语音 片段;所述拼接模块,用于将所述经增强后的目标语音片段拼接到所述经分离后的语音数 据中形成新的语音数据。 其中,所述识别模块,具体用于:采用基于所述语音数据的声纹特征和预设语音数 据的声纹特征,通过将所述语音数据中涵盖所述预设语音数据的声纹特征最多且时间长度 最短的语音片段作为目标语音片段的方式,从所述语音数据中识别出与预设语音对应的目 标语音片段。 其中,所述分离模块,具体用于:采用提取所述目标语音片段和所述语音数据的线 性预测分析特征,和对所述线性预测分析特征进行归一化操作,和将所述经归一化操作后 的线性预测分析特征作为长短期记忆网络和卷积神经网络和卷积神经网络的训练输入的 方式,构建基于所述语音数据和所述目标语音片段的二分类模型,和根据所述二分类模型, 从所述语音数据中分离出所述目标语音片段。 其中,所述语音增强装置,还包括:优化模块;所述优化模块,用于对所述新的语音 数据进行优化。 其中,所述优化模块,具体用于:提取所述新的语音数据的短时短时傅里叶变换特 征和一阶短时傅里叶变换特征以及二阶短时傅里叶变换特征,通过交叉熵损失的损失函数 对所述短时傅里叶变换特征和一阶短时傅里叶变换特征以及二阶短时傅里叶变换特征进 行参数更新,通过所述经更新后的短时傅里叶变换特征和一阶短时傅里叶变换特征以及二 阶短时傅里叶变换特征采用预设次数的迭代方式,对所述新的语音数据进行优化。 根据本发明的又一个方面,提供一种语音增强设备,包括:至少一个处理器;以及, 与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处 理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执 行上述任一项所述的语音增强方法。 根据本发明的再一个方面,提供一种计算机可读存储介质,存储有计算机程序,所 述计算机程序被处理器执行时实现上述任一项所述的语音增强方法。 可以发现,以上方案,可以获取待增强的语音数据,和可以从该语音数据中识别出 与预设语音对应的目标语音片段,和可以从该语音数据中分离出该目标语音片段,和可以 增强该分离出的目标语音片段,以及可以将该经增强后的目标语音片段拼接到该经分离后 的语音数据中形成新的语音数据,能够实现对整段语音中的语音片段进行增强。 进一步的,以上方案,可以采用基于该语音数据的声纹特征和预设语音数据的声 纹特征,通过将该语音数据中涵盖该预设语音数据的声纹特征最多且时间长度最短的语音 片段作为目标语音片段的方式,从该语音数据中识别出与预设语音对应的目标语音片段, 这样的好处是能够提高从该语音数据中识别出与预设语音对应的目标语音片段的准确率。 进一步的,以上方案,可以采用提取该目标语音片段和该语音数据的线性预测分 析特征,和对该线性预测分析特征进行归一化操作,和将该经归一化操作后的线性预测分 析特征作为长短期记忆网络和卷积神经网络和卷积神经网络的训练输入的方式,构建基于 该语音数据和该目标语音片段的二分类模型,和根据该二分类模型,从该语音数据中分离 出该目标语音片段,这样的好处是由于该长短期记忆网络和卷积神经网络能够保留音频上 下文的信息,能够提高该构建的二分类模型的准确率,同时又能够根据该构建的二分类模 5 CN 111583947 A 说 明 书 3/8 页 型从该语音数据中分离出该目标语音片段,能够提高该从该语音数据中分离出该目标语音 片段的准确率。 进一步的,以上方案,可以对该新的语音数据进行优化,这样的好处是能够实现提 高该新的语音数据对应的语音的播放效果。 进一步的,以上方案,可以提取该新的语音数据的短时短时傅里叶变换特征和一 阶短时傅里叶变换特征以及二阶短时傅里叶变换特征,通过交叉熵损失的损失函数对该短 时傅里叶变换特征和一阶短时傅里叶变换特征以及二阶短时傅里叶变换特征进行参数更 新,通过该经更新后的短时傅里叶变换特征和一阶短时傅里叶变换特征以及二阶短时傅里 叶变换特征采用预设次数的迭代方式,对该新的语音数据进行优化,这样的好处是能够使 该新的语音数据的特征更加突出,能够实现提高该新的语音数据对应的语音的播放效果。 附图说明 为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现 有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本 发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以 根据这些附图获得其他的附图。 图1是本发明语音增强方法一实施例的流程示意图; 图2是本发明语音增强方法另一实施例的流程示意图; 图3是本发明语音增强装置一实施例的结构示意图; 图4是本发明语音增强装置另一实施例的结构示意图; 图5是本发明语音增强设备一实施例的结构示意图。











