
技术摘要:
在本发明申请中,我们提出了多层神经网络作为信息筛选的工作原理,并根据原理提出了一种可视化中间层信息处理的方法,从而提高多层神经网络信息处理的可信度。在本发明申请中,我们也提出了对数据做多分辨率预处理,然后再使用多层神经网络来筛选信息的方法。也提出了 全部
背景技术:
当前机器学习的主流算法是使用多层神经网络进行深度学习,而多层神经网络是 模拟 人脑思维方式的数学模型。但这种算法是一种信息黑盒模型,我们只能理解输入和输 出,而 算法为什么选择这样的中间层数据,算法做出判断的依据是什么并不明确。这会对 模型的可 信任程度造成影响。事实上,深度学习网络可能选取一些人类难以察觉的特征作 为识别依据, 从而造成在人类看来难以置信的误判。在已有的对深度学习网络解释的技术 中,一种信息瓶 颈理论(Information Bottleneck)认为,网络像把信息从一个瓶颈中挤压 出去一般,去除掉那 些含有无关细节的噪音输入数据,只保留与通用概念最相关的特征。 这种方法是建立在互信 息基础上的。一般而言,信道中总是存在着噪声和干扰,信源发出 消息x,通过信道后信宿 只可能收到由于干扰作用引起的某种变形的y。信宿收到y后推测 信源发出x的概率,这一 过程可由后验概率p(x|y)来描述。相应地,信源发出x的概率p(x) 称为先验概率。信息瓶颈理 论定义x的后验概率与先验概率比值的对数为y对x的互信息量 (简称互信息)。这种方法和 本发明申请中提出基于坐标基底变换和采用非线性激活函数 去掉干扰信息的方式,在基础假 设上和数据处理方法上都是不相同的,对中间隐含层的信 息处理的解释也是不相同的。另外 一种已有的对深度学习网络解释的技术是局部可解释 性描述(Local Interpretable Model-Agnostic Explanations,LIME),这种算法为了搞清 楚哪一部分输入对预测结果产生贡 献,它将输入值在其周围做微小的扰动,观察模型的预 测行为。然后根据这些扰动的数据点 距离原始数据的距离分配权重,基于它们学习得到一 个可解释的模型和预测结果。这是一种 采用尝试改变输入,来看看输出的变化,来寻找模 型的最后输出中保留了那些输入信息,而 去掉了那些输入信息的过程。这个过程和本发明 申请中提出的直接对每一个中间层做逆变换 到输入层,从而确定每一层输出中保留了那 些输入信息,而去掉了那些输入信息的方法是完 全不同的。LIME是一种尝试方法,是通过 尝试去寻找输入中那个部分对输出很敏感来确定 输入中的高权重信息的。而本发明申请 中提出的是一种数学方法,它不仅仅可以看到输出层 保留了那些输入信息,还可以看到每 一个中间层保留了那些信息。在本发明申请中,我们提 出了一种对多层神经网络的信息处 理过程的数学解释,并基于这个解释,提出了一种分析多 层神经网络的隐含层对信息的保 留和去除的情况,从而确保人类能够理解多层神经网络对数 据的处理方式。在这些基础 上,本发明申请进一步提出了对数据做多分辨率预处理,然后再 使用多层神经网络来筛选 信息的方法。也提出了对动态特征做多分辨率提取的方法。而这些 方法都是为了进一步提 高模型泛化能力打下基础。
技术实现要素:
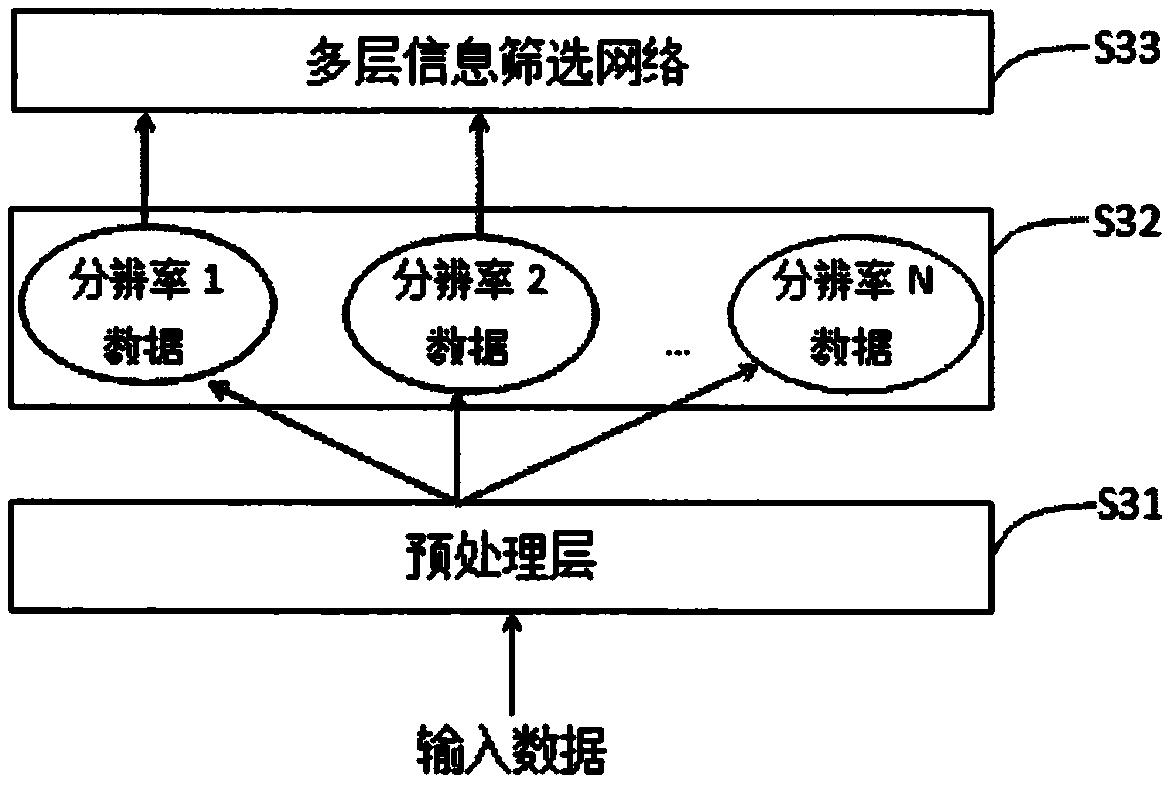
本发明申请提出一种理解多层神经网络的工作原理的方法:我们可以认为输入数 3 CN 111612131 A 说 明 书 2/6 页 据是 在冲击函数坐标基底下的坐标分量系数。每一次层间变换,就是一次信息表达方法的 变换过 程。比如,第一次变换,就是把输入的冲击函数坐标基底,线性变换到另外一个坐标 基底。 这个坐标基底是隐含的,可以改变的。这个坐标基底的坐标分量系数就是第一个中 间层的线 性输出(使用非线性激活函数之前)。如果两者维度相同,那么这两个坐标基底的 信息表达能 力是相同的,输入层到第一个中间层没有信息损失。 但多层神经网络的目的,就是把输入信息中的干扰信息(冗余信息)去掉,保留核 心 信息(有用信息),所以整个网络必须去掉那些干扰信息。而去掉这些干扰信息方法是通 过坐 标基底变换,把核心信息和干扰信息分别变换到不同的坐标基底上去,让它们成为不 同坐标 基底的分量。然后,机器通过抛弃那些代表干扰信息的分量,来去掉这些信息。 为了达到这个目的,一种很方便的方式就是采用非线性激活函数。通过非线性激 活函 数来把部分坐标基底上的信息分量置零,比如ReLU函数,就是把一半的坐标基底信息 去掉。 比如各种变形ReLU函数,或者其他激活函数,它们的本质都是去掉部分坐标基底或 者压缩 这些坐标基底上的信息来实现去掉干扰信息的目的,比如Leaky ReLU,就是通过对 一半的坐 标分量进行信息压缩来去掉冗余信息。 每个中间层神经元输出,都可以看作是信息在一个对应的隐含坐标基底上的分量 投 影。多层神经网络的优化过程,就是对数据做不同坐标基底分量的分解,然后去掉那些 不需 要的坐标基底上的信息。每一层由于非线性激活函数,都会带来部分基底上的信息分 量损失。 所以激活函数的非线性、中间神经元的数量和层数之间是相互制约的。激活函数 的非线性越 强,信息损失越多,这时需要使用更少的层数,更多的中间层神经元数量来保 证核心信息的 层间传递不受损失。假设输入信息包含的信息量是X,输出信息包含的信息 量是Y,中间层 每一次映射的信息表达能力传递率为G,那么需要的层数就是L>ln(Y/X)/ ln(G),其中L是需 要的层数。显然,我们可以通过在多层网络中插入线性变换层(或者弱非 线性变换层),这些 层带来的信息损失为零或者很小,从而在保留了有用信息的前提下,增 加了坐标基底变换的 次数,这样既能避免因为层数增加而带来有用信息受损(带来层数增 加,性能反而下降的问 题),又能使得机器有更多的机会使用更好的中间坐标基底(比如正 交坐标基底)。正交坐标 基底使得优化梯度之间彼此独立,从而避免了改变一个权重系数 时,实际上改变了多个彼此 关联的坐标分量的问题。而这个问题会带来局域极点问题。 在坐标基底维度缩减到1/K的情况下,每层信息表达的能力缩减到1/K2;在坐标基 底 维度不变的情况下,假设R为非线性激活函数的输入输出取值范围之比,那么每层信息 表达 的能力缩减到1/R2;需要指出,这里是指信息表达能力损失率,不是指信息损失率。在 很多 时候,针对特定的信息,维度过高的坐标基底可能有冗余的维度。当这个信息从高维 转向低 维坐标基底时,如果去掉的都是那些冗余的维度,那么这个信息本身就没有损失。 所以在本 发明申请中,可以通过上述约束条件来约束每一层到下一层的信息表达损失率, 从而决定采 用的激活函数、神经元数量和层数。 采用非线性激活函数的意义是:建立一种限制信息传递的方法。通过对输出区间 限制 信息的传递率,这样,机器才能通过误差优化把需要限制传递的信息放入这个区间。 如果没 有非线性函数,只是在每次线性变换后,直接抛弃一部分基底坐标上的分量,那么 结果就是 被限制信息传递的区间是随机的(因为被限制信息传递的输出区间和输入区间 是一样,都是 全空间),这样机器就无法通过误差优化算法来把应该被限制传递的信息放 4 CN 111612131 A 说 明 书 3/6 页 入到对应的输出区 间去,从而无法达到优化整个多层映射网络的目的。 在人类识别事物时,我们是通过语义连接来把特定的特征和语言符号连接起来, 这种 连接是通过学习来建立的,和信息特征传递过程无关。另外,人类在识别事物时,常常 可以 根据动态特征和常识来帮助识别事物。另外,人类在识别事物时,常常是先整体,再局 部来 识别事物。所以,在上述分析的基础上,我们提出了如下方法: 1,多层神经网络应该包含两个层次。其中,下层是感知层,它通过信息特征映射来完成 的信 息的传递和抛弃过程。上层是认知层,它通过对信息特征到概念建立特定映射。这种 映射是 通过学习来获得的:比如“狗”的图形特征到“狗”的语言符号之间的语义映射。 2,多层神经网络可以通过坐标基底反变换来识别机器选取的中间层特征,从而解 决信 息黑盒问题。 3,采用多分辨率信息来训练多层神经网络有更好的健壮性和更高的效率。 4,多层神经网络应该包含识别动态特征。 附图说明 图1是感知层和认知层组成的双层系统。认知层主要是通过记忆和遗忘机制来实现。图 2是多层信息筛选网络,层间主要是隐含的坐标基底变换和通过非线性激活函数抛弃部分 坐标基底上的信息。图3是整个可解释的多层信息筛选网络。











