
技术摘要:
一种基于强化学习的蝾螈机器人路径跟踪的分层控制方法。针对蝾螈仿生机器人的路径跟踪问题,建立了分层控制框架,包括基于强化学习的上层控制器和基于逆运动学的底层控制器,实现了蝾螈仿生机器人跟踪目标路径。具体地,对于上层控制器,在softActor‑Critic(演员‑评 全部
背景技术:
开发用于野外搜索和救援的机器人已成为一个热门的机器人研究领域,搜救场景 通常很狭小,并且地形复杂,这些地方很危险,救援人员很难到达,利用机器人来辅助救援 队进行探索获取信息,可以提高救援的效率。动物的一个关键特征是它们在环境中有效移 动的能力,这种基本但令人惊叹的能力是数百万年进化的结果,它的灵活性和能源利用效 率远远超过机器人的水平。所以仿生机器人根据动物的身体构造来设计结构,希望可以实 现相同的控制效果,仿生机器人正是为了完成非常具有挑战性的野外任务而开发的,例如 在灾难后的废墟中进行搜救,在不适合人类和其他普通机器人的危险环境中进行勘测探 索。 对于在地面执行任务,蝾螈机器人在结构上具有四只腿和可以摆动的脊柱,所以 具有穿越复杂环境的能力,同时重心较低,不容易倾倒,通过脊柱摆动配合四条腿的运动可 以提高运动速度并且保持稳定性。 国内外相关领域的学者对仿生机器人开展了大量的研究工作,其中一大类是多关 节仿生类机器人的研究。针对仿生类蝾螈机器人,早期开发的蝾螈仿生机器人没有腿,因此 限制了它们的运动能力,后来提出的机器人,比如Salamandra robotica II,它具有四条腿 和一个可以摆动的躯干,能够在借助腿在地面和浅水区运动,但是它的腿部结构只有一个 关节,这严重限制了在更复杂地形运动的能力,只能在一个平面运动。下一代提出的蝾螈机 器人Pleurobot与生物学上的结构极为相似,每条腿都有四个关节,具备高度的运动灵活 性,这极大提高了它在复杂地形运动的能力。 众所周知,蝾螈类机器人由于其冗余度高,控制起来非常困难,在各种控制方法 中,采用信息融合和平滑输出信号的中央模式发生器是一种有效的控制方法,但由于其复 杂的耦合关系,所涉及的参数的优化比较复杂,难以获得比较合适的震荡参数。另一种方法 是通过逆运动学规划机器人的轨迹,利用力反馈设计机器人的控制律。此外,有学者提出了 一种实时的脊柱腿协调控制算法,该算法消耗大量的计算资源,在研究转弯运动时没有考 虑左右步幅长度差值对转弯半径的影响。后来也有团队使用IMU和相机来收集环境信息,但 是在将传感器融合算法的输出用来实现闭环控制时并没有成功。
技术实现要素:
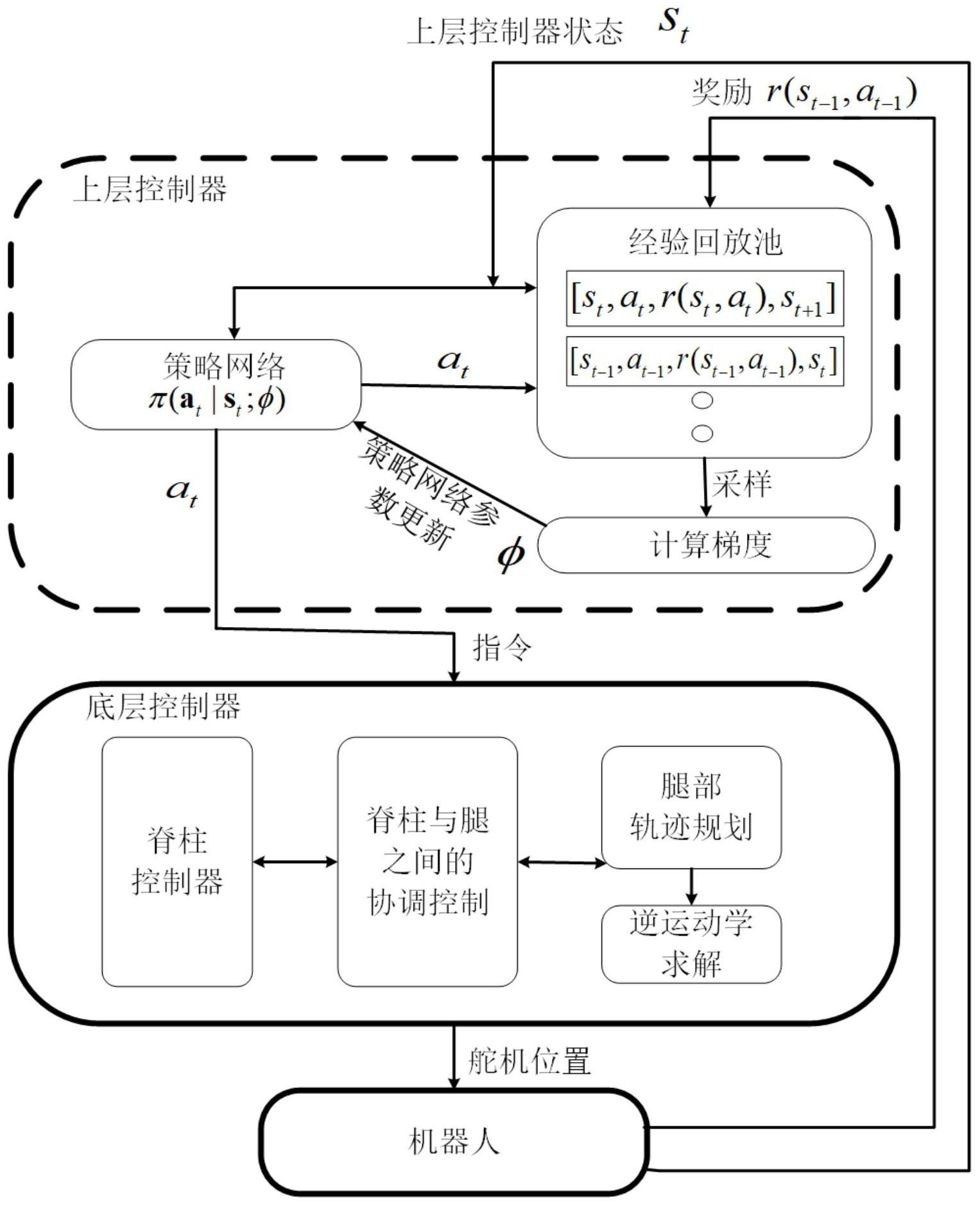
本发明的目的是解决现有蝾螈类机器人控制方法涉及的参数优化比较复杂、算法 消耗大量的计算资源等问题,提供一种基于强化学习的蝾螈机器人路径跟踪的分层控制方 法。 本发明为了解决蝾螈机器人路径跟踪的问题采用了分层控制的方法,上层的策略 7 CN 111552301 A 说 明 书 2/14 页 网络用强化学习训练,提供复杂的全局决策,而底层的传统控制器实现来自上层控制器的 命令。与其他控制算法相比,本发明的分层控制框架充分利用了强化学习和传统控制算法 的特点,也就是说,上层控制器通常适合于处理缓慢变化的、高维的信息来做出全局决策, 而底层的传统控制器则擅长于跟踪特定的命令。此外,针对直线路径跟踪的具体任务,将状 态积分补偿引入到soft Actor-Critic算法中,实验结果表明,与普通soft Actor-Critic 算法相比,该算法取得了明显的改进。 本发明的技术方案 一种基于强化学习的蝾螈机器人路径跟踪的分层控制方法,该方法采用分层控制 框架,所述蝾螈机器人跟踪路径根据任务不同分为两层控制器,分别是基于强化学习的上 层控制器和基于逆运动学的底层控制器,其中基于强化学习的上层控制器包括状态空间的 设计、动作空间的设计和奖励函数的设计,底层控制器包括脊柱控制器和腿部控制器,腿部 控制器由轨迹生成模块和逆运动学求解模块构成。具体地,蝾螈机器人在t时刻的状态和动 作分别表示为st,at,上一时刻得到的奖励表示为r(st-1,at-1),在训练阶段,上层控制器在t 时刻输入r(st-1,at-1)和st,然后输出动作at,动作at作为底层控制器的输入,底层控制器根 据输入的指令输出蝾螈机器人19个关节的位置,并在仿真环境中执行,根据执行指令后机 器人的状态,生成下一时刻的奖励r(st,at),再将r(st,at)和st 1反馈给上层控制器,依次循 环。在实验阶段,上层控制器的输入和环境的反馈只有状态st,中间步骤相同。两层控制器 的具体设计方法如下: 第1、基于强化学习的上层控制器的设计: 蝾螈机器人跟踪路径的问题建模为一个马尔可夫决策过程(Markov decision process),通过一个元组来定义 其中 是连续的状态空间, 表示连续的动作 空间,p表示状态转移概率,r是在每次状态转移过程中来自环境的奖励。π(at|st)表示策略, 在状态为st时采取动作at,用ρπ(st,at)表示状态-动作的轨迹分布边际,soft Actor-Critic 强化学习算法的目标是学习一个最优策略π(at|st)使得奖励与交叉熵的累积加权和最大, 即 其中,α是超参数,权衡奖励与交叉熵的重要性,最大熵目标可以有效地扩大探索 范围,加快强化学习的收敛速度。 第1.1、状态空间的设计 对于路径跟踪问题,本发明将目标路径离散为一系列散点,用一个滑动窗口从路 径起点滑向终点,将滑动窗口中的n个散点在机器人坐标系中的坐标作为状态,即 其中,RP ti 表示滑动窗口中第i个散点在机器人坐标系中的坐标。滑动窗口的移动 取决于窗口中第一个点与机器人之间的距离,如果距离小于设定的阈值,则滑动窗口向前 移动一步,滑动窗口中第一个点将被移除,在队列末尾将增加一个点。当扫描完目标路径上 的所有点后,路径跟踪任务就完成了,变化较快的传感器数据不被选择作为状态的一部分, 8 CN 111552301 A 说 明 书 3/14 页 从而使训练好的网络更容易应用到真实的机器人上。 在路径跟踪任务中容易出现稳态误差,为了有效地消除跟踪的稳态误差,引入状 态积分补偿项,即 其中, 是积分补偿项,表示滑动窗口中第一个点的坐标的累积求和。 第1.2、动作空间设计 在分层控制框架中,上层控制器输出的动作作为底层控制器的输入,动作是一个 抽象的命令,包括向前、向左、向右运动一个很小的距离,而不是具体的关节位置或者速度, 这样做的优点是能够对任何路径有效,即任何路径的跟踪可以转化为机器人向前、向左、向 右运动一个很小的距离。在本发明中,对于蝾螈机器人跟踪路径,动作是左腿的步长、右腿 的步长和脊柱的偏置,如果左腿的步长比右腿的步长大,机器人则向右运动,脊柱偏置对转 弯有一定的影响,动作空间设计如下: 其中,lleft表示左腿步长,lright表示右腿步长, 表示脊柱偏置。 第1.3、奖励函数的设计 强化学习利用奖励来引导机器人学习到一个最优的策略,在机器人跟踪路径的任 务中,机器人与滑动窗口内所有散点的距离的加权和的相反数作为奖励函数,直观意义是 距离越小,奖励越大,即 其中,ki是权重系数,用来调整每个目标点的重要性,随着i的增加,相应的目标点 距离机器人越远,所以权重系数越小,注意到滑动窗口中的n个目标点表示跟踪路径的前视 距离,机器人可以据此决定前进的方向,将奖励定义为负值,以激励机器人以最少的控制步 数到达目标位置。 第2、基于逆运动学的底层控制器的设计 第2.1、腿部控制器设计 每条腿有四个关节,通过解逆运动学得到每个关节的角度,使末端执行器按照给 定的轨迹运动。这四条腿的参数相同,所以下面的分析适用于每条腿,下面对一条腿建立运 动学模型,从腿部末端点到基座的四个坐标变换矩阵如下: 9 CN 111552301 A 说 明 书 4/14 页 其中sθ=sin(θ) ,cθ=cos(θ)腿部末端点在第四个坐标系下的位置为4P=[0 -96 0 1]T,则末端点在基座坐标系下的位置为 如此便找到了四个关节角与腿部末端点在基坐标系的对应关系,基坐标系固定在 机器人上,通过改变四个关节角就可以改变末端点的位置。腿部的控制是通过在基坐标系 下给定一条轨迹,让末端点跟踪这条轨迹。末端点相对地面静止,利用腿部末端与地面的反 作用力推动身体前进,轨迹通过贝塞尔曲线生成,通过改变控制点可以改变轨迹的步幅长 度和高度。在每条轨迹上等间隔取样100个点pi=[xi yi zi]T作为腿部末端点的目标位置, 通过逆运动学求解出所对应的四个关节角,以固定频率向四个舵机发送求解出的目标角度 便可以让腿部走出对应的轨迹。 机器人腿部末端在基坐标系下的笛卡尔空间坐标为: 机器人腿部末端点的速度 与四个关节角速度 满足: 其中, 10 CN 111552301 A 说 明 书 5/14 页 雅可比矩阵J是3×4阶的矩阵不可以对其求逆,否则利用雅可比逆矩阵,通过给定 腿部末端点的目标位置与当前位置的误差项,便可以求出控制项关节角速度。现在将求解 关节角转换为一个优化问题: 其中Δq=qt-q表示目标角度与当前角度的误差; Δp=pt-p表示腿部末端点在笛卡尔空间下目标位置与当前的误差; J是雅可比矩阵,λ是常数阻尼项,目的是避免关节角进入极点,转速太快,损坏舵 机。 令 f(Δq)=||Δp-JΔq||2 λ||Δq||2 =tr[(Δp-JΔq)(Δp-JΔq)T] λtr(ΔqΔqT) (19) =tr(ΔpΔpT-ΔpΔqTJT-JΔqΔpT JΔqΔqT) λtr(ΔqΔqT) 再求导 得到目标角度和当前角度的误差的最优解如下 Δq=(JTJ λI)-1JTΔp (21) 根据公式(21)得到当前角度与目标角度的差值,通过积分得到当前角度,再运用 正运动学公式(13)得到当前腿部末端点在基坐标系下的位置,计算腿部末端点的目标位置 与当前位置的误差项Δp,如果误差项大于给定的阈值,则将误差项Δp继续带入公式(21) 求解Δq,如果误差项小于给定的阈值,则将当前角度作为当前目标位置的解,然后更新下 一个目标位置和雅可比矩阵,重新计算位置误差项Δp作为公式(21)的输入项,得到目标角 度和当前角度的误差Δq,如此迭代计算可以求解出所有样本目标位置所对应的四个舵机 的目标角度,如果计算机性能允许,可以实现在线规划腿部末端位置,再求解得到所对应的 舵机角度。 与蝾螈爬行相似,本文考虑了四足蝾螈机器人以静态稳定、规则对称的爬行步态 行走,先放下空中的腿,再抬起地面上的腿,至少有三条腿始终接地。在走路的过程中,前腿 从摆动阶段切换到站立阶段,然后后腿的相对一侧切换到摆动阶段,然后前腿进入摆动阶 段。 四只腿的相位如下所示: ψRF=0,ψLH=0.25,ψLF=0.5,ψRH=0.75 (22) 11 CN 111552301 A 说 明 书 6/14 页 其中RF、LH、LF、RH分别代表右前肢、左后肢、左前肢、右后肢。 第2.2、脊柱控制器设计 脊柱的运动可以改变重心的位置,增加运动的平稳性,还可以增大腿迈出的步幅 长度,从而加快运动的速度。脊柱按照正弦信号摆动控制器设置如下 其中bi是脊柱第i个舵机按正弦信号摆动的振幅,f是摆动的频率,通过与腿部运 动频率配合能够改变运动速度,φi是第i个舵机正弦信号的初相位, 是第i个舵机正弦信 号的偏置项。 由于脊柱关节数目较少,中间关节的运动幅度较大。脊柱的正弦信号周期的四分 之一是一个相位,有四个相位,因此 φ1=0,φ2=π,φ3=0 (24) 在公式(24)中给出了偏置项的选取原则,当机器人直行的时候,偏置项为零,脊柱 按照正弦信号摆动,当机器人需要转弯的时候,脊柱向转弯相反的方向弯曲,偏置项的大小 与转弯的半径成正比。 本发明的优点和有益效果: 本发明提出一种基于强化学习的蝾螈机器人路径跟踪的分层控制方法。针对蝾螈 仿生机器人的路径跟踪问题,建立了分层控制框架,包括基于强化学习的上层控制器和基 于逆运动学的底层控制器,实现了蝾螈仿生机器人跟踪目标路径。具体地,首先构建蝾螈机 器人的仿真环境,对于上层控制器,在soft Actor-Critic(演员-评论)算法的基础上引入 状态积分补偿,可以提高跟踪精度,消除静态误差,此外,提出更为紧凑的机器人状态表示 和更为抽象的动作表示。最终,将机器人在仿真环境中训练好的控制器迁移到真实环境中, 来验证算法的可行性与泛化能力。实验结果表明,本发明能够较好的完成控制目标,在仿真 到实际的迁移性与泛化性方面表现出了更好的控制效果。 附图说明 图1是基于强化学习的分层控制框架图; 图2是蝾螈机器人的仿真和实际模型; 图3是蝾螈机器人路径跟踪的实验环境; 图4是蝾螈机器人的动作空间表示示意图; 图5是蝾螈机器人在真实环境中跟踪直线的结果图; 图6是蝾螈机器人在真实环境中跟踪正弦曲线的结果图。











