
技术摘要:
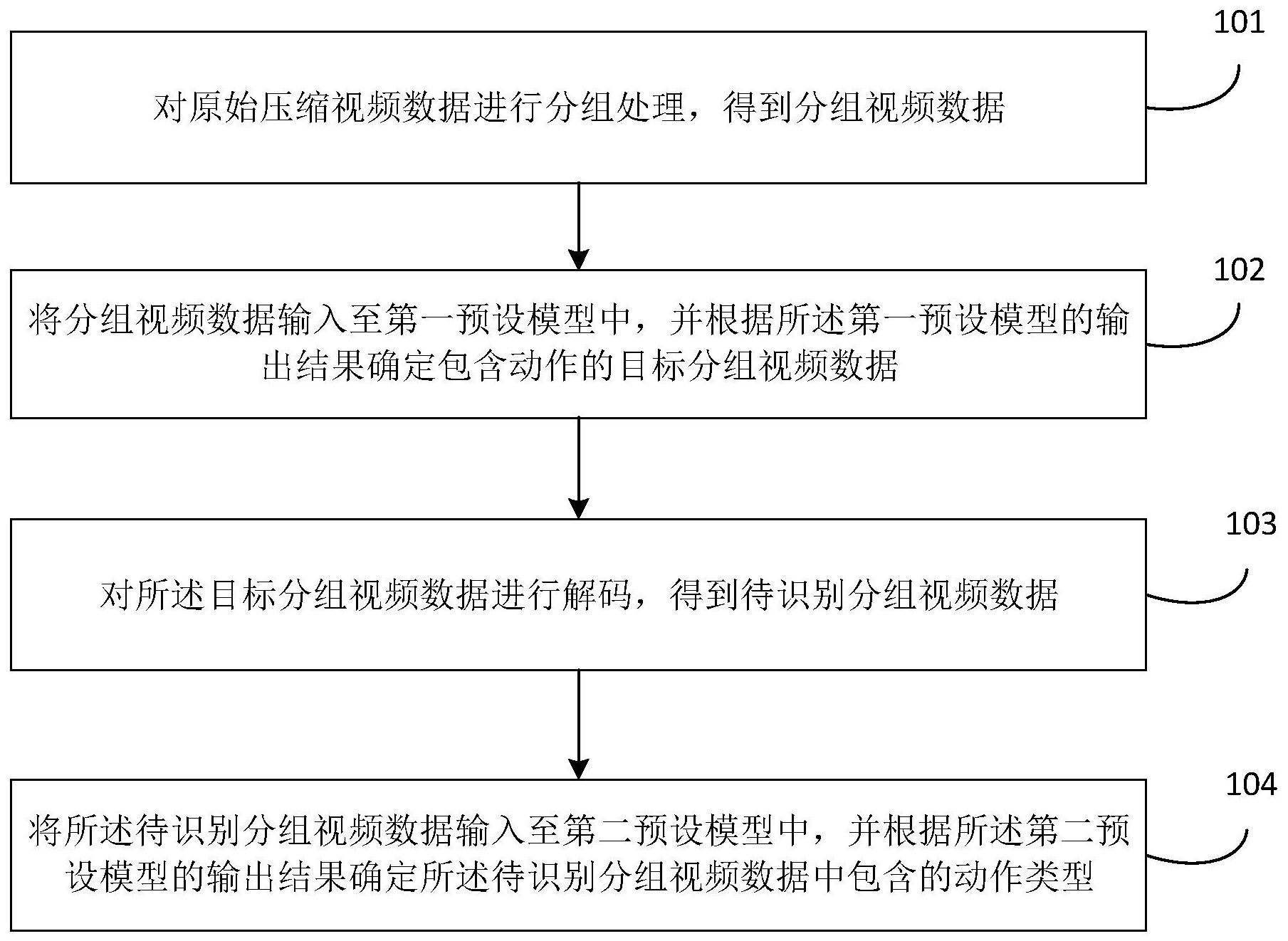
本发明实施例公开了动作识别方法、装置、设备及存储介质。其中,该方法包括:对原始压缩视频数据进行分组处理,得到分组视频数据,将分组视频数据输入至第一预设模型中,并根据第一预设模型的输出结果确定包含动作的目标分组视频数据,对目标分组视频数据进行解码,得 全部
背景技术:
基于视频的动作识别,一直是计算机视觉研究的重要领域。视频动作识别的实现 主要包括特征抽取与表示,以及特征分类两大部分。经典的如密度轨迹追跟踪等方法,一般 为手动设计特征的方法,而近些年来,人们发现深度学习具备强大的特征表示能力,神经网 络便逐渐成为动作识别领域的主流方法,相对于手动设计特征的方法,大大提升了动作识 别的性能。 目前,神经网络动作识别方案大部分基于从视频中获取的序列图片构建出时序关 系,从而对动作进行判断。例如:基于循环神经网络构建图片之间的时序、基于3D卷积提取 多个图片时间的时序信息以及基于图片的深度学习技术叠加动作变化的光流信息等。上述 方案存在计算量与识别精度不能兼顾的问题,需要改进。
技术实现要素:
本发明实施例提供了动作识别方法、装置、设备及存储介质,可以优化现有的针对 视频的动作识别方案。 第一方面,本发明实施例提供了一种动作识别方法,该方法包括: 对原始压缩视频数据进行分组处理,得到分组视频数据; 将所述分组视频数据输入至第一预设模型中,并根据所述第一预设模型的输出结 果确定包含动作的目标分组视频数据; 对所述目标分组视频数据进行解码,得到待识别分组视频数据; 将所述待识别分组视频数据输入至第二预设模型中,并根据所述第二预设模型的 输出结果确定所述待识别分组视频数据中包含的动作类型。 第二方面,本发明实施例提供了一种动作识别装置,该装置包括: 视频分组模块,用于对原始压缩视频数据进行分组处理,得到分组视频数据; 目标分组视频确定模块,用于将所述分组视频数据输入至第一预设模型中,并根 据所述第一预设模型的输出结果确定包含动作的目标分组视频数据; 视频解码模块,用于对所述目标分组视频数据进行解码,得到待识别分组视频数 据; 动作类型识别模块,用于将所述待识别分组视频数据输入至第二预设模型中,并 根据所述第二预设模型的输出结果确定所述待识别分组视频数据中包含的动作类型。 第三方面,本发明实施例提供了一种计算机设备,包括存储器、处理器及存储在存 储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如本发 明实施例提供的动作识别方法。 5 CN 111598026 A 说 明 书 2/12 页 第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程 序,该程序被处理器执行时实现如本发明实施例提供的动作识别方法。 本发明实施例中提供的动作识别方案,对原始压缩视频数据进行分组处理,得到 分组视频数据,将分组视频数据输入至第一预设模型中,并根据第一预设模型的输出结果 确定包含动作的目标分组视频数据,对目标分组视频数据进行解码,得到待识别分组视频 数据,将待识别分组视频数据输入至第二预设模型中,并根据第二预设模型的输出结果确 定待识别分组视频数据中包含的动作类型。通过采用上述技术方案,在对压缩视频进行解 压前,先利用第一预设模型粗略筛选出包含动作的视频片段,再利用第二预设模型精确识 别包含的动作的具体类型,可以在保证识别精度的前提下有效减少计算量,提高动作识别 效率。 附图说明 图1为本发明实施例提供的一种动作识别方法的流程示意图; 图2为本发明实施例提供的一种压缩视频中帧排列示意图; 图3为本发明实施例提供的一种特征变换操作示意图; 图4为本发明实施例提供的另一种动作识别方法的流程示意图; 图5为本发明实施例提供的一种基于压缩视频流的动作识别过程示意图; 图6为本发明实施例提供的一种第一2D残差网络结构示意图; 图7为本发明实施例提供的一种动作标签示意图; 图8为本发明实施例提供的又一种动作识别方法的流程示意图; 图9为本发明实施例提供的基于短视频的动作识别应用场景示意图; 图10为本发明实施例提供的一种基于序列图片的动作识别过程示意图; 图11为本发明实施例提供的一种第二2D残差网络结构示意图; 图12为本发明实施例提供的一种3D残差网络结构示意图; 图13为本发明实施例提供的两级多感受野池化操作的运算过程示意图; 图14为本发明实施例提供的一种动作识别装置的结构框图; 图15为本发明实施例提供的一种计算机设备的结构框图。











