
技术摘要:
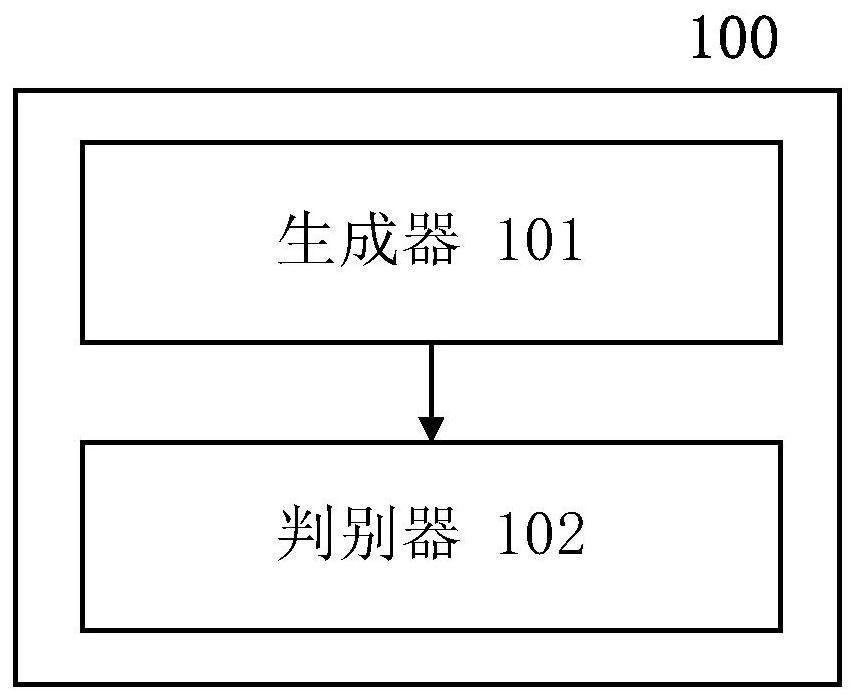
公开了一种语音处理装置,包括:生成器,其被配置成将包括两个或更多个原始单一语音的混合语音分离成两个或更多个分离的单一语音;以及判别器,其被配置成区分所述分离的单一语音是否是所述原始单一语音,其中,对所述生成器和所述判别器进行训练,直到所述判别器不再 全部
背景技术:
这个部分提供了与本公开有关的背景信息,这不一定是现有技术。 多语音单声道语音分离具有广泛的应用。例如,在许多人讲话的家庭环境或会议 环境中,人类听觉系统可以容易地从多个讲话者的混合语音中跟踪和跟随目标讲话者的语 音。在这种情况下,如果要执行自动语音识别和讲话者识别,则需要将目标讲话者的干净语 音信号从混合语音中分离,以完成随后的识别工作。因此,为了在语音或讲话者识别任务中 实现令人满意的性能,必须解决该问题。
技术实现要素:
这个部分提供了本公开的一般概要,而不是其全部范围或其全部特征的全面披 露。 本公开的目的在于提供一种有效的端到端装置来进行自动语音分离。根据本公开 的装置不仅旨在最大化信号与失真比(Signal-to-DistortionRatio,SDR)来获得更好的语 音质量,其还将语音分离和提高语音质量集成到单个模型中。根据本公开的技术方案通过 这个过程执行生成性对抗训练,这使得分离的语音与真实的语音难以区分。 根据本公开的一方面,提供了一种语音处理装置,包括:生成器,其被配置成将包 括两个或更多个原始单一语音的混合语音分离成两个或更多个分离的单一语音;以及判别 器,其被配置成区分所述分离的单一语音是否是所述原始单一语音,其中,对所述生成器和 所述判别器进行训练,直到所述判别器不再能够区分所述分离的单一语音是否是所述原始 单一语音。 根据本公开的另一方面,提供了一种语音处理方法,包括:由生成器将包括两个或 更多个原始单一语音的混合语音分离成两个或更多个分离的单一语音;以及由判别器区分 所述分离的单一语音是否是所述原始单一语音,其中,对所述生成器和所述判别器进行训 练,直到所述判别器不再能够区分所述分离的单一语音是否是所述原始单一语音。 根据本公开的另一方面,提供了一种程序产品,该程序产品包括存储在其中的机 器可读指令代码,其中,所述指令代码当由计算机读取和执行时,能够使所述计算机执行根 据本公开的语音处理方法。 根据本公开的另一方面,提供了一种机器可读存储介质,其上携带有根据本公开 的程序产品。 使用根据本公开的语音处理装置和方法能够在分离混合语音的同时提高所分离 的语音的质量。 从在此提供的描述中,进一步的适用性区域将会变得明显。这个概要中的描述和 3 CN 111554316 A 说 明 书 2/7 页 特定例子只是为了示意的目的,而不旨在限制本公开的范围。 附图说明 在此描述的附图只是为了所选实施例的示意的目的而非全部可能的实施,并且不 旨在限制本公开的范围。在附图中: 图1为根据本公开的一个实施例的语音处理装置100的框图; 图2为根据本公开的一个实施例的语音处理方法的流程图;以及 图3为其中可以实现根据本公开的实施例的语音处理装置和语音处理方法的通用 个人计算机的示例性结构的框图。 虽然本公开容易经受各种修改和替换形式,但是其特定实施例已作为例子在附图 中示出,并且在此详细描述。然而应当理解的是,在此对特定实施例的描述并不打算将本公 开限制到公开的具体形式,而是相反地,本公开目的是要覆盖落在本公开的精神和范围之 内的所有修改、等效和替换。要注意的是,贯穿几个附图,相应的标号指示相应的部件。











