
技术摘要:
本发明涉及通信技术领域,公开了一种音频信号的处理方法、装置及存储介质,该方法包括:每接收到一个音频帧时,根据第一映射关系识别音频帧的频点对应的处理数值;根据音频帧的频点对应的处理数值,对该频点执行相应的处理;将处理后的音频帧发送至终端设备并存储处理 全部
背景技术:
随着物联网进程加快,作为家庭安防设备的安防摄像头正走进千家万户,并在我 们的生活中扮演越来越重要的角色;而且,随着科学技术的发展,安防摄像头也越来越智 能,它不仅仅是一个监控工具,还有手机查看、实时对讲、视频回放、移动侦测等功能。 目前,现有的安防摄像头可以将监控到的音频与画面实时传输给手机app (Application,应用程序),用户通过手机app便能对实际场景进行监控。然而,当用户开启 手机app的扬声器,并在距离安防摄像头较近的地方观看安防摄像头的画面时,安防摄像头 采集环境中的声音发送给手机app,手机app再将此声音通过扬声器播放出来,而扬声器播 放的音频会重新被安防摄像头的麦克风采集到,如此循环往复,声音不断叠加,导致容易产 生啸叫。 因此,为了避免啸叫的产生,需要对安防摄像头采集到的音频进行处理。目前,普 遍采用两种方式对安防摄像头采集到的音频进行处理;其中一种方式是先对音频进行啸叫 检测,然后对存在啸叫的频点进行陷波处理,即降低啸叫频点的增益;另一种方式是先对音 频进行啸叫检测,然后对存在啸叫的频点的相位进行处理,如可采用随机相位或反相的方 法进行处理。在这两种处理方式中,啸叫检测是非常重要的步骤,而现有的啸叫检测方法均 是采用先验知识来进行检测,误判率相对较高,容易将非啸叫的频点误判为有啸叫的频点; 而且,将非啸叫的频点误判为有啸叫的频点,并进行抑制处理后,必然会造成音频的失真, 导致对原始音频造成损坏。
技术实现要素:
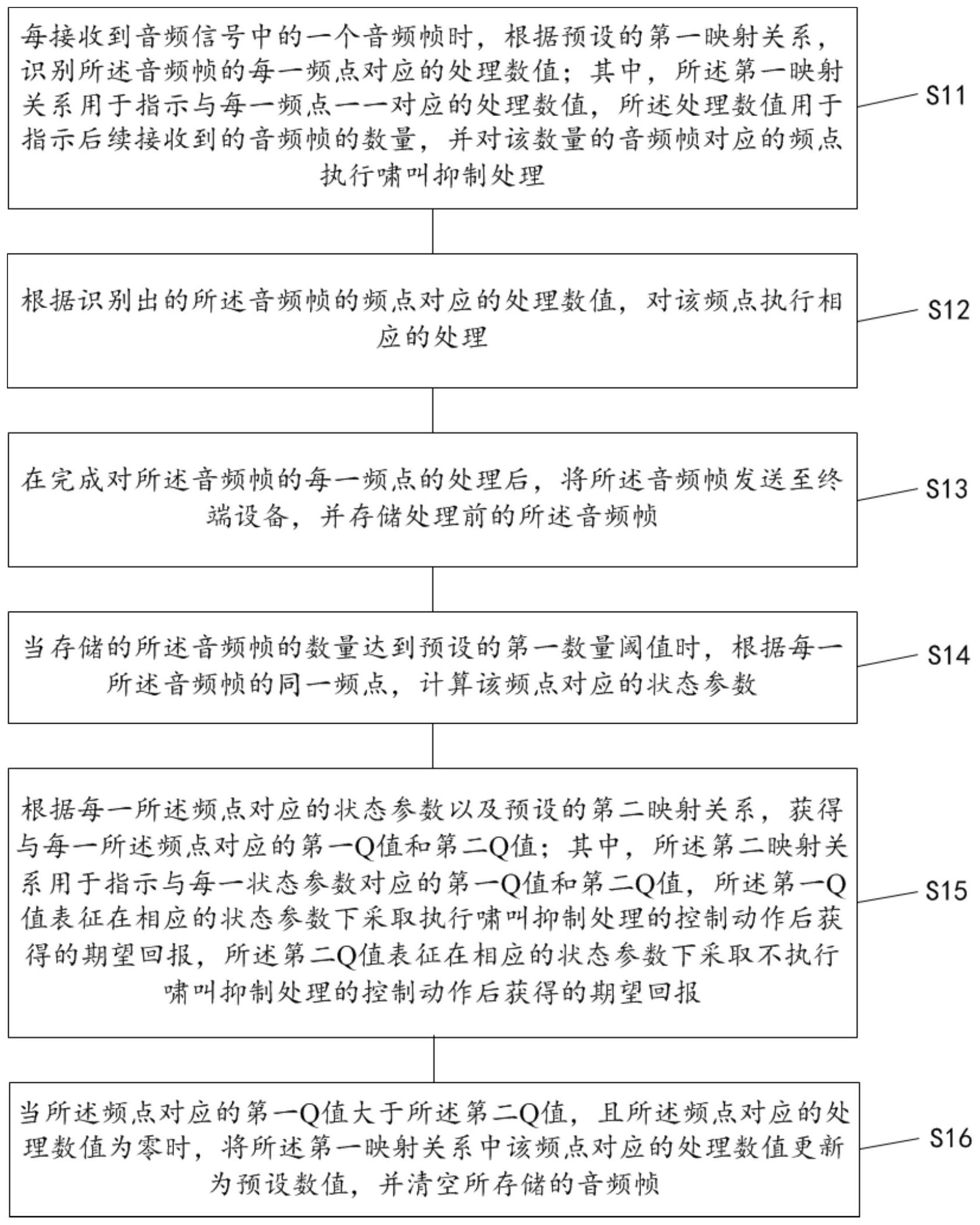
本发明的目的是提供一种音频信号的处理方法、装置及存储介质,能够降低啸叫 的误检率,从而保证音频的质量。 为了解决上述技术问题,本发明提供一种音频信号的处理方法,包括: 每接收到音频信号中的一个音频帧时,根据预设的第一映射关系,识别所述音频 帧的每一频点对应的处理数值;其中,所述第一映射关系用于指示与每一频点一一对应的 处理数值,所述处理数值用于指示后续接收到的音频帧的数量,并对该数量的音频帧对应 的频点执行啸叫抑制处理; 根据识别出的所述音频帧的频点对应的处理数值,对该频点执行相应的处理; 在完成对所述音频帧的每一频点的处理后,将所述音频帧发送至终端设备,并存 储处理前的所述音频帧; 当存储的所述音频帧的数量达到预设的第一数量阈值时,根据每一所述音频帧的 同一频点,计算该频点对应的状态参数; 5 CN 111599370 A 说 明 书 2/13 页 根据每一所述频点对应的状态参数以及预设的第二映射关系,获得与每一所述频 点对应的第一Q值和第二Q值;其中,所述第二映射关系用于指示与每一状态参数对应的第 一Q值和第二Q值,所述第一Q值表征在相应的状态参数下采取执行啸叫抑制处理的控制动 作后获得的期望回报,所述第二Q值表征在相应的状态参数下采取不执行啸叫抑制处理的 控制动作后获得的期望回报; 当所述频点对应的第一Q值大于所述第二Q值,且所述频点对应的处理数值为零 时,将所述第一映射关系中该频点对应的处理数值更新为预设数值,并清空所存储的音频 帧。 作为优选方案,在所述每接收到音频信号中的一个音频帧时,根据预设的第一映 射关系,识别所述音频帧的每一频点对应的处理数值之前,还包括: 循环接收音频信号,并在接收到所述音频信号时,开始计时; 当计时的时间在预设的时间阈值内时,根据接收到的所述音频信号的音频帧,通 过强化学习训练得到所述第二映射关系。 作为优选方案,所述根据接收到的所述音频信号的音频帧,通过强化学习训练得 到所述第二映射关系,具体包括: 依次获取接收到的每一所述音频帧的预设频点并存储; 当存储的所述预设频点的数量等于预设的第二数量阈值时,根据每一所述预设频 点,计算所述预设频点对应的第一状态参数,并采用贪婪策略选取一个控制动作;其中,所 述控制动作包括执行啸叫抑制处理和不执行啸叫抑制处理; 当选取的所述控制动作为执行啸叫抑制处理时,对所述音频帧的预设频点执行啸 叫抑制处理; 当存储的所述预设频点的数量等于预设的第三数量阈值时,根据在所述预设频点 的数量等于预设的第二数量阈值之后才存储的每一所述预设频点,计算所述预设频点对应 的第二状态参数;其中,所述第二数量阈值小于所述第三数量阈值; 根据存储的每一所述预设频点、所述第一状态参数、所述第二状态参数和所选取 的所述控制动作,计算得到所述第一状态参数对应的第一Q值和第二Q值,以更新预设的第 二映射关系中相应的状态参数所对应的第一Q值和第二Q值; 在更新完所述第二映射关系中相应的第一Q值和第二Q值后,清空所存储的预设频 点,并返回步骤:依次获取接收到的每一所述音频帧的预设频点并存储。 作为优选方案,所述根据存储的每一所述预设频点、所述第一状态参数、所述第二 状态参数和所选取的所述控制动作,计算得到所述第一状态参数对应的第一Q值和第二Q 值,以更新预设的第二映射关系中相应的状态参数所对应的第一Q值和第二Q值,具体包括: 根据存储的每一所述预设频点、所述第一状态参数和所述第二状态参数,识别所 存储的所述音频帧是否存在啸叫; 当识别出所存储的所述音频帧存在啸叫,且所选取的控制动作为不执行啸叫抑制 处理时,将奖励值设置为预设的第一奖励阈值,并通过贝尔曼方程计算得到所述第一状态 参数对应的第二Q值,以更新所述第二映射关系中相应的状态参数所对应的第二Q值; 当识别出所存储的所述音频帧存在啸叫,且所选取的控制动作为执行啸叫抑制处 理时,将奖励值设置为预设的第二奖励阈值,并通过贝尔曼方程计算得到所述第一状态参 6 CN 111599370 A 说 明 书 3/13 页 数对应的第一Q值,以更新所述第二映射关系中相应状态参数所对应的第一Q值; 当识别出所存储的所述音频帧不存在啸叫,且所选取的控制动作为不执行啸叫抑 制处理时,将奖励值设置为预设的第三奖励阈值,并通过贝尔曼方程计算得到所述第一状 态参数对应的第二Q值,以更新所述第二映射关系中相应的状态参数所对应的第二Q值; 当识别出所存储的所述音频帧不存在啸叫,且所选取的控制动作为执行啸叫抑制 处理时,将奖励值设置为预设的第四奖励阈值,并通过贝尔曼方程计算得到所述第一状态 参数对应的第一Q值,以更新所述第一映射关系中相应的状态参数所对应的第一Q值;其中, 所述第二奖励阈值大于所述第三奖励阈值,所述第三奖励阈值大于所述第一奖励阈值,所 述第一奖励阈值大于所述第四奖励阈值; 所述贝尔曼方程,具体为: NewQ(s,a)=Q(s,a) α[R(s,a) γmaxQ′(s′,a′)-Q(s,a)] 其中,NewQ(s ,a)为在状态参数s为所述第一状态参数下采取控制动作a后获得的 期望回报;Q(s,a)为在所述第二映射关系中,在状态参数s为所述第一状态参数下采取控制 动作a后获得的期望回报;α为预设的学习率;R(s,a)为所述奖励值;γ为折扣因子;maxQ′ (s′,a′)为在所述第二映射关系中,状态参数s′为所述第二状态参数时所对应的数值最大 的Q值。 作为优选方案,所述根据存储的每一所述预设频点、所述第一状态参数和所述第 二状态参数,识别所存储的所述音频帧是否存在啸叫,具体包括: 根据存储的每一所述预设频点,计算第一和值和第二和值;其中,所述第一和值为 在所述预设频点的数量等于预设的第二数量阈值时,所存储的每一所述预设频点的幅值之 和;所述第二和值为在所述预设频点的数量等于预设的第二数量阈值之后才存储的每一所 述预设频点的幅值之和; 当所述第一和值、所述第二和值、所述第一状态参数和所述第二状态参数符合预 设的条件时,确定所存储的所述音频帧存在啸叫; 当所述第一和值、所述第二和值、所述第一状态参数和所述第二状态参数不符合 预设的条件时,确定所存储的所述音频帧不存在啸叫; 其中,所述预设的条件为同时满足: |df1-ds1| |df2-ds2|











