
技术摘要:
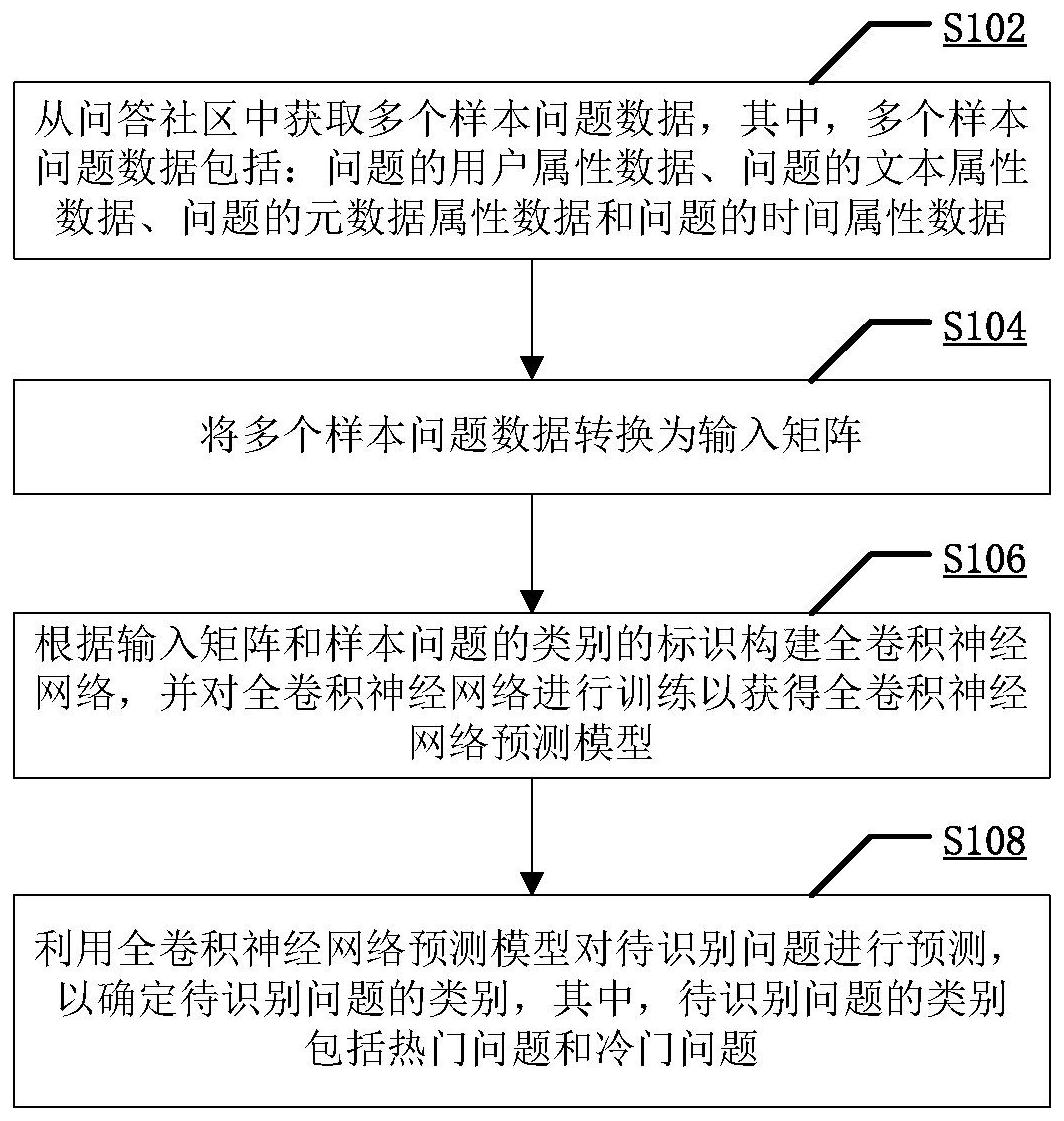
本发明涉及一种问答社区中的热门问题的预测方法,属于热门内容预测领域,解决了现有技术中采用的相关信息少,对热门问题的识别率和识别精度低的问题。预测方法包括:从问答社区中获取多个样本问题数据,其中,多个样本问题数据包括:问题的用户属性数据、问题的文本属 全部
背景技术:
软件工程师经常利用在线工具(称为software information sites)来解决他们 在软件开发和维护过程中遇到的问题。在这些在线工具中,软件问答社区非常受欢迎,用户 可以在这里询问、回答编程相关的问题。Stack overflow是一个代表性的软件问答社区。该 社区从2008年开始投入使用,目前已经有超过1000万的用户。这些软件问答社区中每天都 有大量的问题产生,一个新问题被发布之后,很快就会被其余的新发布的问题所掩盖。这使 得问题被回答的难度增大,并且使用户难以找到合适的问题来跟踪和贡献。随着时间的推 移,一些问题开始流行并获得很高的评价。吸引了更多用户注意力的帖子将具有相对较高 的用户活动,例如浏览量,回答数等。发现这些帖子使我们能够洞悉被用户广泛关注的问 题。在问题发布初期找到将要变得热门的问题,可以缩短其获得答案所需的时间,增加获得 答案的可能性,从而解决许多用户可能正在面临的问题。因此,有必要研究软件问答社区中 的热门问题预测方法。 现有的热门内容预测的方法通常是基于社交平台(例如,微博、推特、facebook等) 通过以下三种方法来完成预测任务:基于时间过程建模、基于文本特征建模以及根据社交 网络结构建模。基于时间建模的方法通过浏览量、转发量、评论量等信息构建预测模型,区 分热门内容和冷门内容。基于文本特征建模的方法通过内容的标题、正文、图像等信息构建 预测模型,识别热门内容。基于社交网络建模的方法通过扩散模型、传播模拟等方法,预测 热门内容。 现有预测方法具有以下缺点: 1、现有技术中选取的用于识别软件问答社区中热门问题的相关信息较少,导致对 热门问题的识别率低;以及 2、软件问答社区中的社交网络模型较为模糊,使用社交网络模型构建预测模型, 无法精确地识别热门问题。
技术实现要素:
鉴于上述的分析,本发明实施例旨在提供一种软件问答社区中热门问题的预测方 法及系统,用以解决现有方法中主要针对社交网络,采用的相关信息较少,导致对热门问题 的识别率和识别精度低的问题。 一方面,本发明实施例提供了一种问答社区中的热门问题的预测方法,包括:从所 述问答社区中获取多个样本问题数据,其中,所述多个样本问题数据包括:问题的用户属性 数据、问题的文本属性数据、问题的元数据属性数据和问题的时间属性数据;将所述多个样 本问题数据转换为输入矩阵;根据所述输入矩阵和样本问题的类别的标识构建全卷积神经 4 CN 111581382 A 说 明 书 2/8 页 网络,并对所述全卷积神经网络进行训练以获得全卷积神经网络预测模型;以及利用所述 全卷积神经网络预测模型对待识别问题进行预测,以确定所述待识别问题的类别,其中,所 述待识别问题的类别包括热门问题和冷门问题。 上述技术方案的有益效果如下:通过多个样本问题数据包括问题的用户属性数 据、问题的文本属性数据、问题的元数据属性数据和问题的时间属性数据,使得这样完整全 面的样本问题数据提高热门问题的识别率。基于这样完整全面的样本问题数据所构建的全 卷积神经网络预测模型能够提高识别热门问题的精度。 基于上述方法的进一步改进,所述问题的用户属性数据包括:发布问题的用户声 誉值、发布问题的用户的向上投票数和发布问题的用户的向下投票数,其中,所述用户声誉 值、所述向上投票数和所述向下投票数与用户发布的问题质量和回答质量有关。 基于上述方法的进一步改进,所述问题的文本属性数据包括:问题的标题、问题的 正文和问题的标签,其中,所述问题的文本属性数据是词向量形式的文本属性数据。 基于上述方法的进一步改进,所述问题的元数据属性数据包括:问题的标签流行 度等级和问题正文中代码段与非代码段长度的比例,其中,所述问题的标签流行度等级是 对问题所含有的全部标签在近期发布的全部问题中出现频率的评估。 基于上述方法的进一步改进,所述问题的时间属性包括:每小时内问题浏览量的 变化量、每小时内问题得分的变化量、和每小时内问题回答数的变化量。 基于上述方法的进一步改进,将所述多个样本问题转换为输入矩阵进一步包括: 将每个样本问题的所述用户属性数据、所述词向量形式的文本属性数据、所述元数据属性 数据和所述时间属性数据分别作为特征向量中的元素,以生成一列特征向量;以及利用多 个样本问题的多列特征向量构成所述输入矩阵,所述输入矩阵包括m行和n列,其中,m对应 于样本问题的数量,n对应于所述一列特征向量中的元素的数量。 基于上述方法的进一步改进,根据所述输入矩阵构建全卷积神经网络,并对所述 全卷积神经网络进行训练以获得全卷积神经网络预测模型进一步包括:根据所述样本问题 的最终浏览量,确定每一个样本问题的类别并打上标识,其中,将具有较高浏览量的样本问 题确定为热门样本问题并标记为1,以及将具有较低浏览量的样本问题确定为冷门样本问 题并标记为0;以及将所述输入矩阵和所述标识导入所述全卷积神经网络并对所述全卷积 神经网络进行训练以获得全卷积神经网络预测模型。 基于上述方法的进一步改进,对所述全卷积神经网络进行训练以获得全卷积神经 网络预测模型进一步包括:将所述输入矩阵输入卷积层,并进行三次卷积,其中,所述卷积 层采用修正线性单元激活函数,每次卷积后均进行批标准化处理;所述三次卷积后,进入池 化层并进行全局平均池化处理;以及采用多项逻辑回归Softmax分类器,根据样本问题经过 卷积、池化后得到的向量及其标识,建立预测模型。 另一方面,本发明实施例提供了一种问答社区中的热门问题的预测系统,包括:样 本问题数据获取模块,用于从所述问答社区中获取多个样本问题数据,其中,所述多个样本 问题数据包括:问题的用户属性数据、问题的文本属性数据、问题的元数据属性数据和问题 的时间属性数据;转换模块,用于将所述多个样本问题转换为输入矩阵;预测模型获取模 块,用于根据所述输入矩阵和样本问题的类别的标识构建全卷积神经网络,并对所述全卷 积神经网络进行训练以获得全卷积神经网络预测模型;以及待识别问题预测模块,用于利 5 CN 111581382 A 说 明 书 3/8 页 用所述全卷积神经网络预测模型对待识别问题进行预测,以确定所述待识别问题的类别, 其中,所述待识别问题的类别包括热门问题和冷门问题。 基于上述系统的进一步改进,所述问题的用户属性数据包括:发布问题的用户声 誉值、发布问题的用户的向上投票数和发布问题的用户的向下投票数,其中,所述用户声誉 值、所述向上投票数和所述向下投票数与用户发布的问题质量和回答质量有关;所述问题 的文本属性数据包括:问题的标题、问题的正文和问题的标签,其中,所述问题的文本属性 数据为转换为词向量形式的文本属性数据;所述问题的元数据属性数据包括:问题的标签 流行度等级和问题正文中代码段与非代码段长度的比例,所述问题的标签流行度等级是对 问题所含有的全部标签在近期发布的全部问题中出现频率的评估;以及所述问题的时间属 性包括:每小时内问题浏览量的变化量、每小时内问题得分的变化量、和每小时内问题回答 数的变化量。 与现有技术相比,本发明至少可实现如下有益效果之一: 1、基于软件问答社区获取的用于判别问题是否热门的属性数据比较全面,包括用 户属性数据、文本属性数据、元数据属性数据和时间属性数据,因此这样完整全面的样本问 题数据提高热门问题的识别率; 2、热门问题和冷门问题在时间属性数据上差异性比较显著,在识别问题是否热门 问题时,通过待识别问题的时间属性数据可以更加快速确定问题是否热门问题;以及 3、根据上述属性数据构建的全卷积神经网络预测模型,能够提高识别热门问题的 精度。 本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本 发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而 易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所 特别指出的内容中来实现和获得。 附图说明 附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图 中,相同的参考符号表示相同的部件。 图1为根据本发明的实施例的问答社区中的热门问题的预测方法的流程图; 图2为根据本发明的实施例的对全卷积神经网络进行训练以获得全卷积神经网络 预测模型的流程图;以及 图3为根据本发明的实施例的问答社区中的热门问题的预测系统的结构图。 附图标记: 302-样本问题数据获取模块;304-转换模块;306-预测模型获取模块;以及308-待 识别问题预测模块











