
技术摘要:
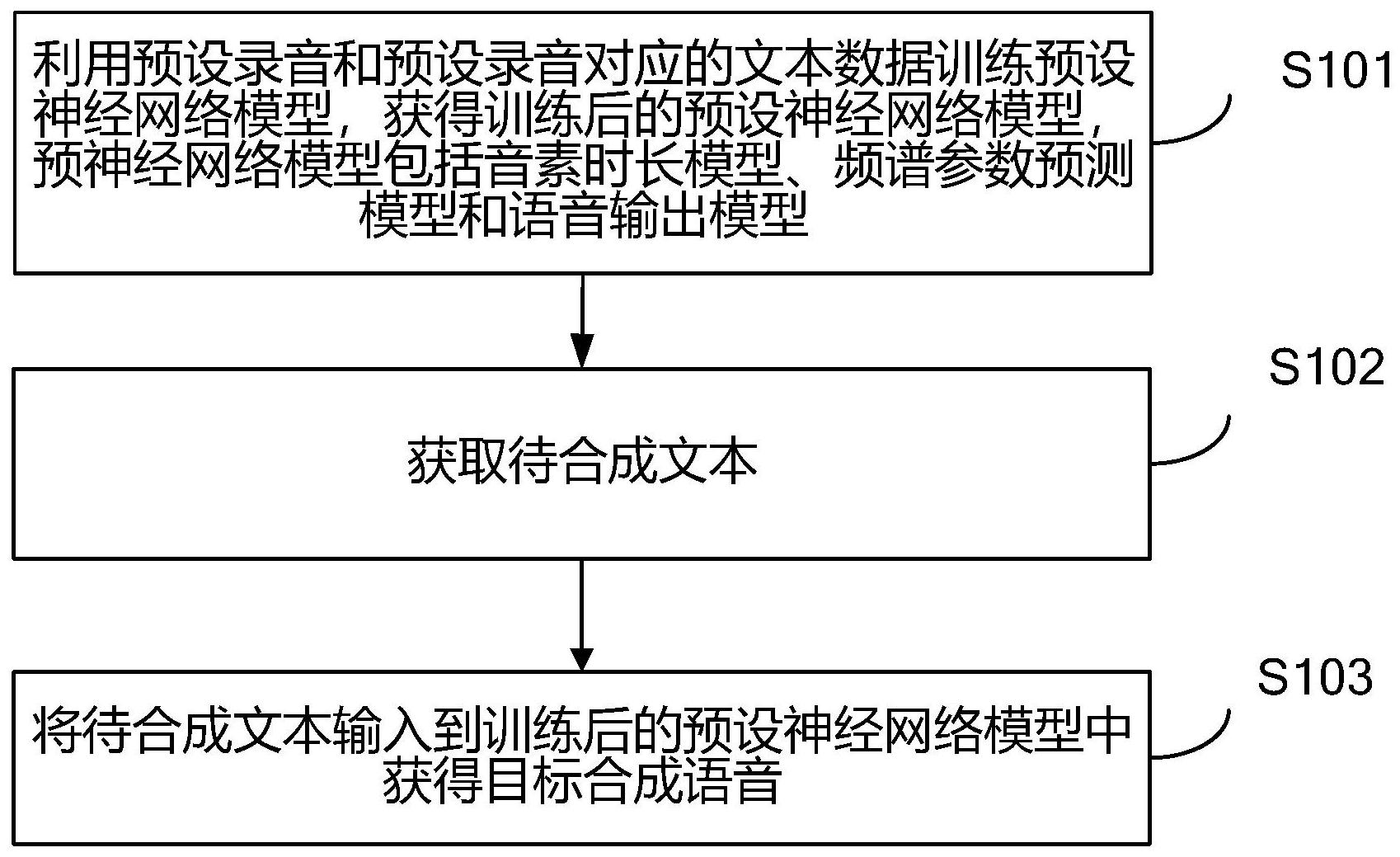
本发明公开了一种稳定可控的端到端语音合成方法及装置,包括:利用预设录音和预设录音对应的文本数据训练预设神经网络模型,获得训练后的预设神经网络模型,预设神经网络模型包括音素时长模型、频谱参数预测模型和语音输出模型;获取待合成文本;将待合成文本输入到训 全部
背景技术:
近年来,随着语音技术的日趋成熟,语音合成技术正逐步应用于语音交互、声音播 报、个性化声音制作等语音信号处理系统中。在社会与商业领域,合成音作为一种声音的展 现,给社会生活带来便利与丰富性,具有潜在广阔的使用价值,现有的语音合成技术是根据 预设录音和预设录音对应的文本对神经网络模型进行训练进而构建端到端语音合成系统, 为了保证合成语音的稳定性,以及可以对时长进行控制,加入了时长控制模块。但是这种方 法存在以下缺点:加入时长控制模块可以一定程度提升合成语音的稳定性,但是会引入由 于时长预测精度不足而导致合成语音效果不好的问题,降低了用户的体验感。
技术实现要素:
针对上述所显示出来的问题,本方法基于在预设网络神经模型中加入了音素时长 模型来优化语音合成效果,利用预设录音和其对应的文本数据来训练预设神经网络模型, 然后利用训练后的预设神经网络模型来对待合成文本进行语音合成。 一种稳定可控的端到端语音合成方法,包括以下步骤: 利用预设录音和所述预设录音对应的文本数据训练预设神经网络模型,获得训练 后的预设神经网络模型,所述预设神经网络模型包括音素时长模型、频谱参数预测模型和 语音输出模型; 获取待合成文本; 将所述待合成文本输入到所述训练后的预设神经网络模型中获得目标合成语音。 优选的,在利用预设录音和所述预设录音对应的文本数据训练预设神经网络模 型,所述预设神经网络模型包括音素时长模型、频谱参数预测模型和语音输出模型之前,所 述方法还包括: 获取预设数量个所述预设语音和所述预设数量个预设语音对应的预设数量个文 本数据; 对所述预设数量个预设语音进行预处理,过滤掉所述预设数量个预设语音中的噪 音成分,去除掉所述预设数量个预设语音中的静音成分; 检查所述预设数量个文本数据的文本内容是否有缺陷,所述缺陷包括:文本内容 不完整,文本内容读不通和文本内容具有逻辑问题,将所述预设数量个文本数据中具有所 述缺陷的第一数量个第一文本数据和其对应的第一预设语音剔除; 将所述预设数量个文本数据中没有所述缺陷的第二数量个第二文本数据和其对 应的第二预设语音确定为所述预设录音和所述预设录音对应的文本数据。 优选的,所述利用预设录音和所述预设录音对应的文本数据训练预设神经网络模 5 CN 111599338 A 说 明 书 2/8 页 型,所述预设神经网络模型包括音素时长模型、频谱参数预测模型和语音输出模型,包括: 获取所述第二数量个文本数据中各文本数据中的表征音素序列和第一音素时长; 将第二数量个表征音素序列作为所述音素时长模型的输入,将所述第二数量个第 一音素时长作为所述音素时长模型的输出来训练所述音素时长模型; 利用训练好的音素时长模型获取所述第二数量个预设录音的第二音素时长; 根据第二数量个第二音素时长对所述第二数量个表征音素序列进行第一帧扩展; 提取所述第二数量个预设录音的频谱参数; 将第二数量个第一帧扩展之后的表征音素序列作为所述频谱参数预测模型的输 入,将所述第二数量个频谱参数作为所述频谱参数模型的输出来训练所述频谱参数预设模 型; 将所述第二数量个频谱参数作为所述语音输出模型的输入,将所述第二数量个预 设录音作为所述语音输出模型的输出来训练所述语音输出模型; 当所述音素时长模型、频谱参数预测模型和语音输出模型都训练完毕后,获得所 述训练后的预设神经网络模型。 优选的,在获取待合成文本之前,所述方法还包括: 获取待合成文本内容中的n个汉字; 确认所述n个汉字是否有多音字; 若是,获取所述n个汉字中是多音字的第一汉字的第一字母序列和第二字母序列, 所述第一字母序列为所述第一汉字为第一音调时组成所述第一音调的字母的第一序列,所 述第二字母序列为所述第一汉字为第二音调时组成所述第二音调的字母的第二序列; 根据所述待合成文本内容在所述第一字母序列和第二字母序列中选择目标字母 序列; 获取第二汉字的第三字母序列,所述第二汉字为所述n个汉字中除所述第一汉字 之外的汉字; 将所述目标字母序列和第三序列标注到所述待合成文本内容中的n个汉字各自对 应的汉字上。 优选的,所述将所述待合成文本输入到所述训练后的预设神经网络模型中获得目 标合成语音,包括: 对所述待合成文本进行解析,获取目标表征音素序列; 将所述目标表征音素序列输入到所述训练后的音素时长模型中获得目标音素音 长; 根据所述目标音素时长对所述目标表征音素序列进行第二帧扩展; 将第二帧扩展之后的目标表征音素序列输入到训练后的频谱参数预设模型中获 得预测频谱参数; 将所述预测频谱参数输入到训练后的语音输出模型中获得所述目标合成语音。 一种稳定可控的端到端语音装置,该装置包括: 训练模块,用于利用预设录音和所述预设录音对应的文本数据训练预设神经网络 模型,获得训练后的预设神经网络模型,所述预设神经网络模型包括音素时长模型、频谱参 数预测模型和语音输出模型; 6 CN 111599338 A 说 明 书 3/8 页 第一获取模块,用于获取待合成文本; 获得模块,用于将所述待合成文本输入到所述训练后的预设神经网络模型中获得 目标合成语音。 优选的,所述装置还包括: 第二获取模块,用于获取预设数量个所述预设语音和所述预设数量个预设语音对 应的预设数量个文本数据; 预处理模块,用于对所述预设数量个预设语音进行预处理,过滤掉所述预设数量 个预设语音中的噪音成分,去除掉所述预设数量个预设语音中的静音成分; 检查模块,用于检查所述预设数量个文本数据的文本内容是否有缺陷,所述缺陷 包括:文本内容不完整,文本内容读不通和文本内容具有逻辑问题,将所述预设数量个文本 数据中具有所述缺陷的第一数量个第一文本数据和其对应的第一预设语音剔除; 确定模块,用于将所述预设数量个文本数据中没有所述缺陷的第二数量个第二文 本数据和其对应的第二预设语音确定为所述预设录音和所述预设录音对应的文本数据。 优选的,所述训练模块,包括: 第一获取子模块,用于获取所述第二数量个文本数据中各文本数据中的表征音素 序列和第一音素时长; 第一训练子模块,用于将第二数量个表征音素序列作为所述音素时长模型的输 入,将所述第二数量个第一音素时长作为所述音素时长模型的输出来训练所述音素时长模 型; 第二获取子模块,用于利用训练好的音素时长模型获取所述第二数量个预设录音 的第二音素时长; 第一扩展子模块,用于根据第二数量个第二音素时长对所述第二数量个表征音素 序列进行第一帧扩展; 提取子模块,用于提取所述第二数量个预设录音的频谱参数; 第二训练子模块,用于将第二数量个第一帧扩展之后的表征音素序列作为所述频 谱参数预测模型的输入,将所述第二数量个频谱参数作为所述频谱参数模型的输出来训练 所述频谱参数预设模型; 第三训练子模块,用于将所述第二数量个频谱参数作为所述语音输出模型的输 入,将所述第二数量个预设录音作为所述语音输出模型的输出来训练所述语音输出模型; 第一获得子模块,用于当所述音素时长模型、频谱参数预测模型和语音输出模型 都训练完毕后,获得所述训练后的预设神经网络模型。 优选的,所述装置还包括: 第三获取模块,用于获取待合成文本内容中的n个汉字; 确认模块,用于确认所述n个汉字是否有多音字; 第四获取模块,用于若所述确认模块确认所述n个汉字有多音字时,获取所述n个 汉字中是多音字的第一汉字的第一字母序列和第二字母序列,所述第一字母序列为所述第 一汉字为第一音调时组成所述第一音调的字母的第一序列,所述第二字母序列为所述第一 汉字为第二音调时组成所述第二音调的字母的第二序列; 选择模块,用于根据所述待合成文本内容在所述第一字母序列和第二字母序列中 7 CN 111599338 A 说 明 书 4/8 页 选择目标字母序列; 第五获取模块,用于获取第二汉字的第三字母序列,所述第二汉字为所述n个汉字 中除所述第一汉字之外的汉字; 标注模块,用于将所述目标字母序列和第三序列标注到所述待合成文本内容中的 n个汉字各自对应的汉字上。 优选的,所述获得模块,包括: 解析模块,用于对所述待合成文本进行解析,获取目标表征音素序列; 第二获得子模块,用于将所述目标表征音素序列输入到所述训练后的音素时长模 型中获得目标音素音长; 第二扩展子模块,用于根据所述目标音素时长对所述目标表征音素序列进行第二 帧扩展; 第三获得子模块,用于将第二帧扩展之后的目标表征音素序列输入到训练后的频 谱参数预设模型中获得预测频谱参数; 第四获得子模块,用于将所述预测频谱参数输入到训练后的语音输出模型中获得 所述目标合成语音。 本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变 得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明 书以及附图中所特别指出的结构来实现和获得。 下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。 附图说明 图1为本发明所提供的一种稳定可控的端到端语音合成方法的工作流程图; 图2为本发明所提供的一种稳定可控的端到端语音合成方法的另一工作流程图; 图3为本发明所提供的一种稳定可控的端到端语音合成装置的结构图; 图4为本发明所提供的一种稳定可控的端到端语音合成装置的另一结构图。











