
技术摘要:
本发明涉及一种基于多目标遗传算法的共享单车停放点分配方法,包括步骤:S1、服务器收集在某时间点内的若干当前用户请求数据;S2、服务器收集用户的请求数据后,对用户的坐标信息、目的地信息和附近可用停放点位置信息进行统计分析;S3、选择锦标赛算法作为选择算子, 全部
背景技术:
随着国外公共自行车的发展逐渐完善经验化,加上我国城市的发展导致的城市交 通问题的日益突出,在这种背景下,低碳环保、节能、方便、快捷和经济实用的共享单车在我 国城市中孕育而出。 中国的大部分城市都存在严重的交通问题,上下班高峰期时间造成的交通拥堵事 件在各大城市十分常见。加上共享单车行业从出现起便是交通与管理热点,单车乱停乱放 现象不仅影响市容,更加剧本就恶劣的交通环境。虽然共享单车改善了人们的出行方式,但 并不能任其停放问题影响到城市交通。停车问题不仅是用户个人的问题,单车行业没有对 用户停放车辆起到引导的作用,停放点的建设也并不成熟,加上用户的规范停放意识低等 问题,导致了单车乱停乱放现象随处可见。而且这种现象也在一定程度上引发了一系列问 题:比如交通拥堵和租车问题,降低了人们对共享单车行业的好感度;租车问题更是直接影 响到用户体验,造成恶性循环。随着共享单车行业规模的增大,与之同时带来了一系列问 题,尤其是租赁问题。在车辆调度方面经常表现为空位借不到车、满位停不了车;用户居住 地、商业办公区、商场和公园都存在明显的早晚高峰和单车分配不合理现象,导致了共享单 车用户体验下降。 目前,共享单车停放点的设置已经在建设中,大多数城市中心区域基本都设置了 停放点,但单车企业的引导措施和用户的停放意识还没有成熟,因此需要在企业开发的软 件中设置停放引导功能,针对性地培养用户的规定停放意识,解决共享单车行业的规范停 放问题。另外,单车扎堆问题对后续管理造成了不良的影响,单车很容易在地铁口、商场和 旅游景点等区域扎堆停放。现如今基本采取后续车辆调度管理措施,在一定程度上能够缓 解车辆扎堆问题,同时还需要用户分散停放来配合调度管理措施,用户停放目的地四周可 能还存在着空位较多的停放点但不自知,这时便需要企业来软性调控各停放点之间的密 度,也就是停放引导问题。由于共享单车租赁是一个新兴产业,建设初期其运营模式尚在探 索中,因此集成商将其他系统上的技术放到业务模式上套用会造成“不合身”的现象。综上 所述,提高单车停放区域利用率,为市民提供一个良好的用户体验,设计出一个良性引导的 共享单车停放点分配系统刻不容缓。 专利201810110235.4《一种结合遗传算法的混合粒子群优化算法》提出了一种结 合遗传算法的混合粒子群优化算法,将粒子群优化算法的全局搜索能力与遗传算法的收敛 速度相结合。把粒子群优化算法的全局搜索能力带入了算法中,再利用遗传算法的快速收 敛,最终达到改进算法的目的。但该发明被没有从根本上加速算法的执行,首先粒子群算法 和遗传算法同样属于随机搜索算法,算法的初始化对算法本身的影响较大,而粒子群算法 和遗传算法在进化的过程中都是盲目的,因此算法的不稳定性并没有得到很好的解决。专 6 CN 111582552 A 说 明 书 2/14 页 利201710068910.7《基于遗传算法的调度方法及装置》公开了一种基于遗传算法的调度方 法及装置,涉及智慧仓储技术领域。使用二维数组对种群个体进行编码,计算适应度值后, 选取具有合适适应度的个体进行交叉处理,并且将每个调度集合中排除元素相同且调度集 合相邻的基因外的元素随机组成子代个体中该调度集合的其余基因。基于遗传算法的调度 方法虽然提升了调度效率,节省了调度成本,但交叉个体的选择并不合理,实数编码中个体 的基因表现并不突出,因此适应度较好的个体并不能代表其某个染色体片段具有良好的基 因。
技术实现要素:
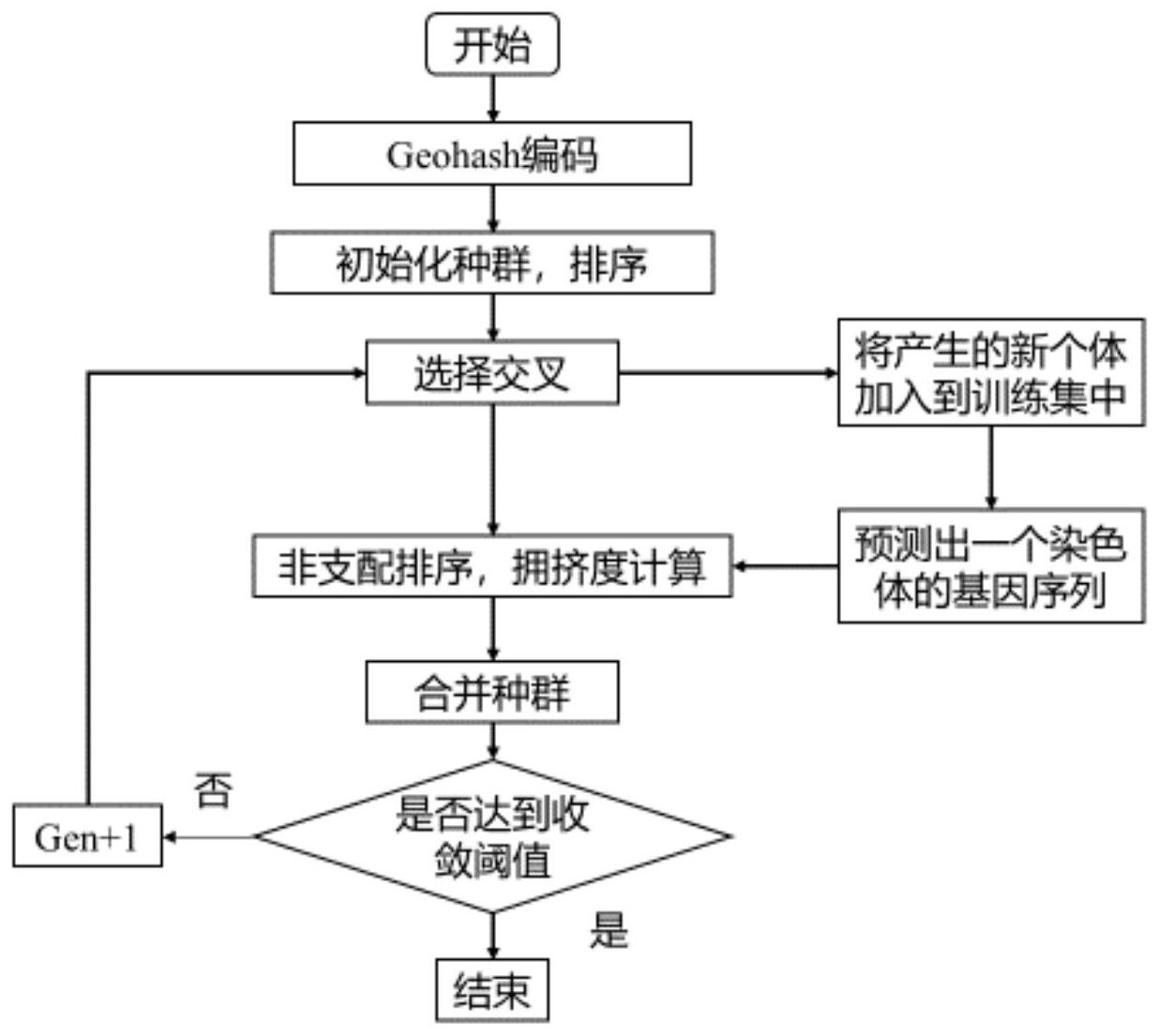
本发明的目的是克服现有技术中的不足,提出一种基于改进的多目标遗传算法, 并将其应用在共享单车停放点分配系统上,通过使用Hypervolume评价指标对改进算法与 原算法进行评估。 这种基于多目标遗传算法的共享单车停放点分配方法,具体包括如下步骤: S1、服务器收集在某时间点内的若干当前用户请求数据;将请求数据中的坐标信 息经过Geohash编码成为字符串;将时间分段为T={1,2,3,…,t},请求停车的车辆集合为I ={1,2,3,…,i},停放点集合为J={1,2,3,…,j},目的地区域集合为P={1,2,3,…,p};将 每个用户的请求数据存放至用户请求信息表中;所述请求数据包括坐标信息、车辆编号、用 户编号和目的地区域p; S2、服务器收集用户的请求数据后,对用户的坐标信息、目的地信息和附近可用停 放点位置信息进行统计分析;某时间点内的若干当前用户的请求数据组成请求队列,按照 时间节点划分请求队列并进行标记,根据目的地信息对其周围停放区域进行搜索并计算距 离,生成用户标号距离矩阵; S2.1、种群初始化:生成若干条基因组成相同但排列组合不同的染色体;将请求队 列作为遗传算法中的染色体,染色体的基因排序由请求队列的处理顺序组成;在之后的种 群迭代过程中保持种群的染色体数不变; S2.2、选择实数编码的NSGA-II作为遗传算法的基因编码方式;用适应度函数区分 种群内的染色体差异,并作为筛选染色体的标准:让种群随着迭代朝着更符合优化目标的 方向进化,最终得到最适合环境的染色体; 适应度函数由优化目标函数和约束条件组成;所述优化目标函数为距离函数f(x) 和密度函数g(x);f(x)为待停的单车到停放点的距离代价总和,g(x)为所有停放点之间的 停车密度代价总和; 优化目标函数的数学模型为: 上式中,pj为各停放点的理想停放数;I为待停的车辆集合,I={1,2,3,…,i};J为 停放点集合,J={1,2,3,…,j};xij为分配标志位取值为xij∈{0,1},xij取值为1时表示i车 辆分配给j停放点,xij取值为0时表示i车辆未分配给j停放点;目标区域p与停放点j之间的 距离用dij表示;其中: 7 CN 111582552 A 说 明 书 3/14 页 首先计算距离函数f(x)的矩阵,接着根据距离函数f(x)的矩阵和约束条件按照染 色体的基因组成计算密度函数g(x)的矩阵; 所述约束条件为: xij∈{0,1} (7) 上式(5)至式(7)中,I为待停的车辆集合,I={1,2,3,…,i};J为停放点集合,J= {1,2,3,…,j};xij为分配标志位取值为xij∈{0,1},xij取值为1时表示i车辆分配给j停放 点,xij取值为0时表示i车辆未分配给j停放点;Bj为每个停放点的车辆容纳上限; S3、选择锦标赛算法作为选择算子,选择自交作为交叉算子,选择双参赛模式; S3.1、锦标赛算法的计算过程如下: S3.1.1、规定筛选后的种群大小为数值Sp,随机选择种群中两个个体p1和p2进行适 应度比较; S3.1.2、若p1和p2之间存在支配关系,则淘汰被支配的个体;若两个个体处在同一 层非支配解,则跳过淘汰阶段,比赛的轮数由种群中剩下的个体数决定; S3.1.3、继续进行适应度比较,直到种群大小降低至数值Sp; S3.2、自交的计算过程如下: S3.2.1、对种群中的每个个体设定一个基因可交叉长度Lp,该长度不得超过染色 体中基因个数的一半; S3.2.2、在染色体中随机设置两个点M1和M2,满足M1和M2之间的距离大于基因可交 叉长度Lp,且M1和M2中后置位点的距离染色体末端距离大于基因可交叉长度Lp; S3.2.3、以M1和M2为锚点,向后端展开两个长度为Lp的基因片段,进行交叉操作; S4、利用快速非支配排序将种群分为若干个等级,并计算种群拥挤度; S4.1、利用快速非支配排序将种群分为若干个等级的过程为: S4.1.1、设种群中个体数为P,其中每个个体有被支配个数np和支配的解Mp这两个 参数,其中Mp为数组; S4.1.2、将该个体被支配个数np取值为0的个体放入数组S1中,作为该种群中的非 支配解; S4.1.3、取消非支配解对支配个体的支配,将S1数组中的个体从种群中排除:对每 个在数组S1中的个体,遍历支配的解Mp中的个体,将该个体的被支配个数np参数减1,当前数 组S1中的个体被支配个数np取值为-1; S4.1.4、将剩余个体中被支配个数np取值为0的个体加入数组S2,对数组S2重复执 8 CN 111582552 A 说 明 书 4/14 页 行步骤S4.1.3,直至种群等级划分完毕; S4.2、种群拥挤度计算的过程为: S4.2.1、对种群中所有个体引入拥挤度Ld,并初始化拥挤度Ld为0; S4.2.2、对每个优化目标函数fm进行遍历,根据每个优化目标函数对个体目标值 排序, 为优化目标函数fm的最大值, 为优化目标函数fm的最小值;得到数量为m的 个体按优化目标函数升序排序后的数组; S4.2.3、将每个数组中优化目标函数最大与最小的个体拥挤度Ld置为∞; S4.2.4、计算数组中剩余个体的拥挤度Ld,当前个体的拥挤度计算公式为: 上式(8)中,L[i]d为当前个体的拥挤度,L[i 1]m和L[i-1]m为相邻个体的拥挤度, 公式(8)将当前个体在m个矩阵中的拥挤度累加得到最终拥挤度; S5、合并种群:引入精英保留策略维持种群的大小和多样性; 每一代种群选择、交叉和变异之后产生新的个体,将新的个体与父种群合成一个 种群Ri;接着根据快速非支配排序的结果将种群按等级从低到高覆盖父种群,直到某一层 的个体不能完全放入;最后将该层的个体按拥挤度降序排列,依次覆盖父种群,直到父种群 被完全覆盖; S6、将用户标号距离矩阵和停放点信息表输入后台遗传算法,判断遗传算法是否 收敛,决定是否继续执行下一代遗传操作: 选用Hypervolume指标进行解集的收敛性评价:给定在n个目标中包含m个点的集 合S;相对于参考点计算S的Hypervolume评价指标: 上式(9)中,δ为Lebesgue测度;|S|表示非支配解集的数目,vi表示参照点与解集 中第i个解构成的Hypervolume评价指标;Hypervolume评价指标值越大,则该解集收敛性越 好; 当种群达到规定的收敛阈值时,执行步骤S7,且遗传算法终止;反之则遗传代数 Gen增加1,返回执行步骤S3至步骤S5,直到种群达到规定的收敛阈值; S7、服务器根据路径规划算法计算用户到达目的地时间,并根据用户到达目的地 时间、目的地周围的停放点信息和调控停放点区域密度,将推荐停放点和目的地附近其余 停放点发送给用户终端供用户选择;并将分配信息存入结果表中。 作为优选,所述步骤S1中的Geohash编码将目的地区域p划分为一个个规则矩形并 对每个矩形进行编码,使用Peano空间填充曲线,首先筛选Geohash编码相似的POI点,然后 进行实际距离的计算。 作为优选,所述步骤S2.2适应度函数中的距离函数f(x)根据每条染色体的基因顺 序来停放车辆,停放时选择贪心策略:轮到某车辆响应时采取就近停放原则,如果最近停放 点的车辆已满则选择距离次级的停放点,以此类推,直至某车辆找到停放点为止。 作为优选,所述步骤S2.2适应度函数中的密度函数g(x)引入平方差评价指标,计 算车辆停放后停放点之间的车辆密度差距。 作为优选,所述步骤S3和步骤S4之间还有: 9 CN 111582552 A 说 明 书 5/14 页 S8、利用融入回归的改进算法在遗传算法的框架上融合回归算法,代替遗传算法 本身的变异算子;遗传算法与回归算法同步执行,当遗传算法通过交叉产生新个体时,将其 加入回归算法的训练集;设定每新加入若干新个体,执行一次回归算法;融入回归的改进算 法计算过程如下: S8.1、按请求队列的顺序对车辆数组P=[1,2,3,…,p]标号,新个体的基因顺序按 请求队列的顺序记录停放状态得出输入变量x=[x1,x2,x3,…,xp];将个体染色体长度作为 回归算法的输入变量x的维数,遍历循环个体的基因,当前基因的停放状态作为取值,若单 车被分配为就近停放则取值为1,反之为0; S8.2、将该个体的适应度相加得出预测值y;广义线性模型如下所示: y(w,x)=w0 w1x1 … wpxp (10) 上式中x为停放状态,预测值y由距离代价和密度代价组成,回归算法回归计算结 束之后,得到一个带有系数w的线性模型,表示请求队列中每辆车的停放状态对适应度的影 响程度; S8.3、将带有索引的w升序排序后,索引顺序作为变异算子得出的新个体:定义w= [w ,w ,w ,…,w ]为系数,w 为截距,回归算法回归计算结束后对w升序排列得到w11 2 3 p 0 ,w1的下 标数组与数组P对应,得出下标数组P1为新个体。 基于多目标遗传算法的共享单车停放点分配系统包括信息采集模块、信息传输模 块、信息的分析和处理模块和信息管理与发布模块; 所述信息采集模块作为线上算法的输入源,用于对用户、车辆、停放点的信息进行 实时数据采集; 所述信息的分析与处理模块用于记录用户产生的实时数据,对数据库中的历史数 据信息和实时数据中用户发送的请求信息进行筛选,用停放点分配算法进行计算;将处理 过的信息进行存放或通过前端App反馈给用户; 所述信息管理与发布模块包括信息管理模块和信息发布模块;信息发布模块用于 对用户的请求做出响应,将服务器计算后得出的结果传送到用户的手机终端上;信息发布 模块还引入各停放点实时信息标注在前端App中的地图标志上。 本发明的有益效果是:本发明提出了基于多目标遗传算法的停放点分配系统,结 合了遗传算法和回归算法,并加入了Hypervolume评价指标,讨论算法的改进性能,主要表 现为收敛性和分布性,一定程度上对算法的执行效率和执行效果进行了优化。 附图说明 图1为系统架构子模块图; 图2为Geohash编码流程图; 图3为本发明的算法流程图; 图4为预测个体与传统遗传算法适应度对比图; 图5为供需比为0.8时Hypervolume评价指标比较图; 图6为单变异与三变异算法Hypervolume评价指标比较图。 10 CN 111582552 A 说 明 书 6/14 页











