
技术摘要:
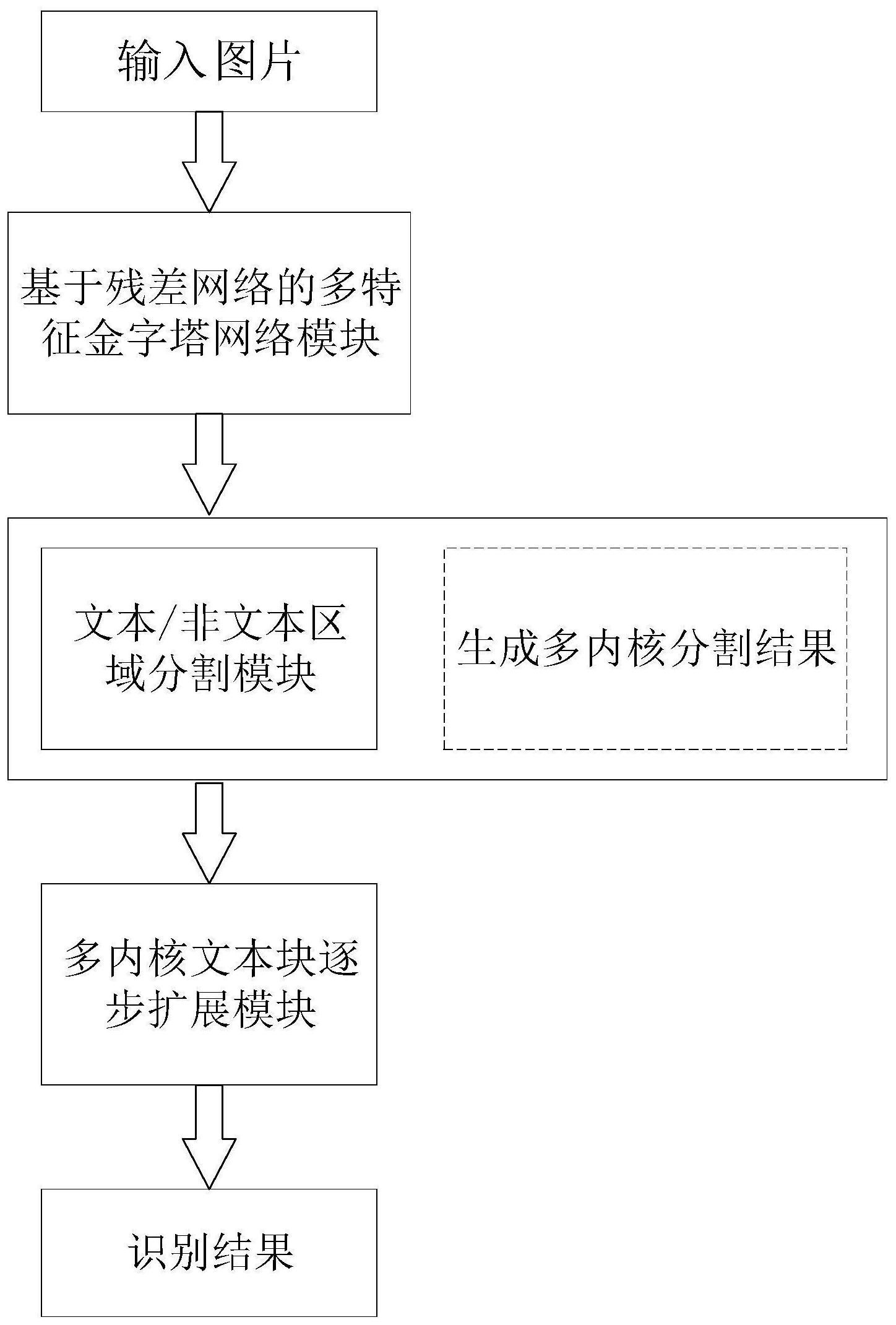
本发明公开一种基于语义分割的场景任意形状的文本检测方法,包括以下步骤:S1、构建任意形状的基于语义分割的场景文本检测网络模型;S2、根据整体目标损失函数,利用反向传播算法和随机梯度下降优化,最小化整体损失函数,对S1中设计的模型进行迭代训练;S3、利用逐步 全部
背景技术:
随着卷积神经网络的发展,场景文本检测已经取得了快速发展,目前在地理定位、 实时翻译、盲人帮助等领域得到了不错的应用。但场景文本的检测不同于传统的光学字符 识别(OCR),由于多方向、弯曲甚至非文本行的文字布局,场景文本的检测更具有挑战性。目 前,广泛应用的场景文本检测方法中主要存在两大困难:一方面,大多数现有方法采用四边 形bounding box(边界框),这种边界框无法准确定位具有任意形状的文本;另一方面,有很 多场景文本行间彼此很相近,导致检测正确率不高,会把连着的文本行识别为一行。传统 上,基于分割的方法可以很好的缓解第一个困难,但通常无法解决第二个困难。
技术实现要素:
针对上述问题,本发明提出一种基于语义分割的场景任意形状的文本检测方法, 主要解决











