
技术摘要:
本发明属于大气污染物浓度预测技术领域,具体涉及一种基于两阶段非负Lasso模型的大气PM2.5浓度预测方法,该方法包括:将某一地区在空间层面上划分多个网格区域,对每个网格区域利用自下而上的空间化方法核算出该网格区域内全年的二氧化碳排放数据,作为该网格区域的二 全部
背景技术:
PM2.5是指环境中空气动力学当量直径小于等于2.5微米的颗粒物,其在空气中含 量浓度越高就代表空气污染越严重。随着工业化的快速推进,大气雾霾现象越来越严重, PM2.5是造成雾霾现象的主要元凶之一,其颗粒粒径小,能长时间悬浮于空气中并传播,并可 携带有毒有害物质进入呼吸道和肺部,经常性的大规模雾霾影响了人们的日常出行,对人 体健康造成直接威胁。PM2.5是雾霾的主要成分,治理雾霾、改善空气质量的首要任务是控制 PM2.5,PM2.5浓度预测是空气质量预测的主要内容。近年来的研究表明,以PM2.5为代表的大气 复合型空气污染已经开始成为影响人民生活质量的重大环境问题。 仿真技术是指通过数值计算等手段反映系统行为的模型技术。不同于一般预测模 型仅仅追求预测精度高,仿真模型更加看重模型可解释性,注重模拟过程,需要根据业务实 际情况在模型中添加限制条件。 研究表明,中国以化石燃料为主的能源结构,CO2排放与大气污染物排放同根(化 石燃料)、同时(燃烧过程中)、同源(同一设备或排放口),其相互之间具有非常紧密的关系。 对于大气PM2 .5浓度预测,通常是基于污染排放数据与气象条件数据,使用多元回 归模型和随机森林模型,进行大气PM2.5浓度预测。但是,现有方法存在如下问题: 1)无法保证模型系数的正负与实际业务一致; 2)不能保证模型系数全部不为零,即不能保证每个二氧化碳指标对环境监测站点 PM2 .5浓度都产生影响,这与实际业务不符,造成了预测存在较大误差,降低了预测的准确 度。
技术实现要素:
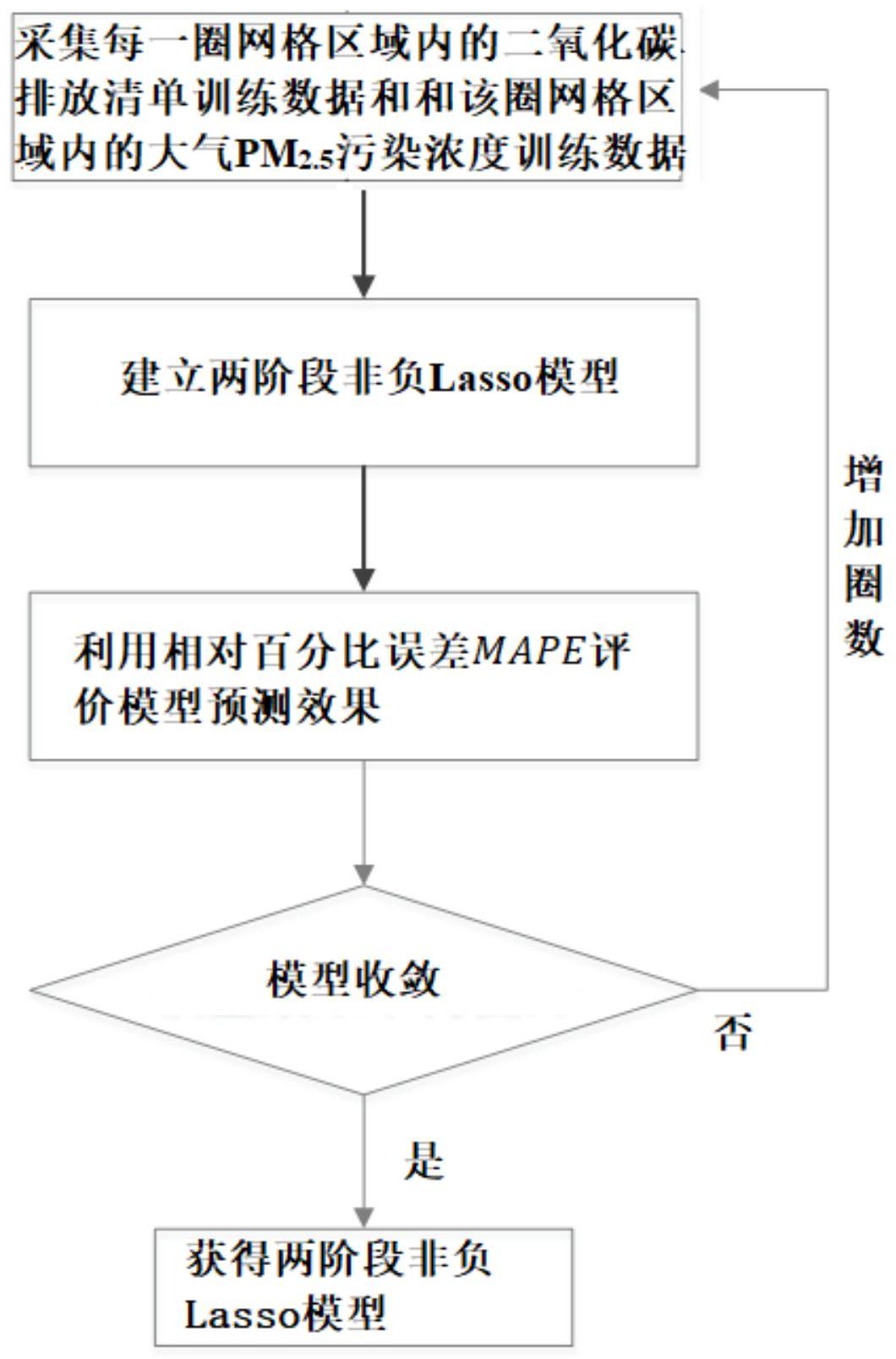
本发明的目的在于,为解决现有技术存在上述缺陷,本发明提出了一种基于两阶 段非负Lasso模型(Least Absolute Shrinkage and Selection Operator)的大气PM2.5浓 度预测方法,通过对不同环境监测站点的PM2.5浓度及站点周围区域二氧化碳排放清单数据 建立模型,分析二者之间的具体关联关系。 本发明提供的一种基于两阶段非负Lasso模型的大气PM2.5浓度预测方法,该方法 包括: 将某一地区在空间层面上划分多个网格区域,对每个网格区域利用自下而上的空 间化方法核算出该网格区域内全年的二氧化碳排放数据,作为该网格区域的二氧化碳排放 清单数据; 将该地区的某网格区域的二氧化碳排放清单数据输入至预先训练的两阶段非负 7 CN 111581792 A 说 明 书 2/14 页 Lasso模型,输出第一预测结果和第二预测结果; 将第一预测结果和第二预测结果相加,获得该区域的PM2 .5浓度数据预测结果,实 现该区域的大气PM2.5浓度预测。 作为上述技术方案的改进之一,所述将某一地区在空间层面上划分多个网格区 域,对每个网格区域利用自下而上的空间化方法核算出该网格区域内全年的二氧化碳排放 数据,作为该网格区域的二氧化碳排放清单数据;具体为: 将某一地区按照10km×10km在空间层面上划分为多个方形网格区域,对每个方形 网格区域利用自下而上的空间化方法核算出该方形网格区域内全年的二氧化碳排放数据, 作为该网格区域的二氧化碳排放清单数据; 其中,所述二氧化碳排放清单数据包括:二氧化碳总排放数据、能源二氧化碳排放 数据、工业二氧化碳排放数据、农业二氧化碳排放数据、服务业二氧化碳排放数据、城市生 活二氧化碳排放数据、农村生活二氧化碳排放数据、交通二氧化碳排放数据、航空二氧化碳 排放数据、公路二氧化碳排放数据、铁路二氧化碳排放数据、水运二氧化碳排放数据和工业 过程二氧化碳排放数据。 作为上述技术方案的改进之一,所述将该地区的某网格区域的二氧化碳排放清单 数据输入至预先训练的两阶段非负Lasso模型,输出第一预测结果和第二预测结果;具体 为: 所述两阶段非负Lasso模型包括:第一阶段非负Lasso模型和第二阶段非负Lasso 模型; 其中,第一阶段非负Lasso模型为: 其中, 为第一预测结果;Xtt表示该地区的某网格区域的二氧化碳排放清单数 据中的二氧化碳总排放数据构成的向量; 表示第一阶段模型系数估计值; 其中,构造第一目标函数: 其中, 为第一阶段平方误差; 表示正则项,即模型的Lasso 部分;λn为第一阶段正则项的权重系数;Ypm2.5为所有环境监测站点PM2.5浓度数据构成的向 量; 将上述第一目标函数转化为矩阵形式: 其中, 为第一阶段模型系数估计值 的转置;Xtt′为Xtt的转置;1表示维度为p1 ×1且每项均为1的列向量;p1等于第一阶段模型系数的维数; 通过二次规划,求解第一阶段模型系数估计值 8 CN 111581792 A 说 明 书 3/14 页 第二阶段非负Lasso模型为: 其中,X-tt为该地区的某网格区域中的除二氧化碳总排放数据之外的剩下的二氧 化碳排放数据构成的向量,作为自变量; 表示第二阶段模型系数估计值;respm2.5为第二 预测结果; 其中,构造第二目标函数: 其中, 为第二阶段模型系数估计值; 为第二阶段 平方误差; 表示正则项;λm为第二阶段正则项的权重系数; 将上述第二目标函数转化为矩阵形式: 其中, 为第二阶段模型系数估计值 的转置;X-tt′为X-tt的转置;1表示维度 为p2×1且每项均为1的列向量;p2等于第二阶段模型系数的维数; 通过二次规划,求解第二阶段模型系数估计值 将该地区的某网格区域的二氧化碳排放数据中的二氧化碳总排放数据输入至上 述第一阶段非负Lasso模型,输出第一预测结果; 将该地区的某网格区域的二氧化碳排放数据中的除了二氧化碳总排放数据之外 的剩下的二氧化碳排放数据输入至上述第二阶段非负Lasso模型,输出第二预测结果。 作为上述技术方案的改进之一,所述两阶段非负Lasso模型的训练步骤具体包括: 按照10km×10km在空间层面上,将上述某一地区划分为多个方形网格区域,对每 个方形网格区域利用自下而上的空间化方法核算出该方形网格区域内全年的二氧化碳排 放训练数据,作为该网格区域的二氧化碳排放清单训练数据; 其中,所述二氧化碳排放清单训练数据包括:二氧化碳总排放训练数据、能源二氧 化碳排放训练数据、工业二氧化碳排放训练数据、农业二氧化碳排放训练数据、服务业二氧 化碳排放训练数据、城市生活二氧化碳排放训练数据、农村生活二氧化碳排放训练数据、交 通二氧化碳排放训练数据、航空二氧化碳排放训练数据、公路二氧化碳排放训练数据、铁路 二氧化碳排放训练数据、水运二氧化碳排放训练数据和工业过程二氧化碳排放训练数据; 根据各个环境监测站点的站点位置,即各个环境监测站点的经度数据和纬度数 据,以及对应的网格区域的四个顶点的经度数据和纬度数据,计算出每个环境监测站点所 属的网格区域; 根据每个环境监测站点所属的网格区域,选出每个站点周围的N圈网格区域,从环 境站点所在的网格区域获取大气PM2.5污染浓度数据,作为该圈网格区域内的大气PM2.5污染 浓度训练数据; 9 CN 111581792 A 说 明 书 4/14 页 再选取环境监测站点周围每一圈网格区域内的二氧化碳排放清单训练数据;对每 一圈网格区域中的二氧化碳排放清单训练数据,根据不同的二氧化碳指标类别,求出对应 的二氧化碳类别均值,得到对应的二氧化碳指标类别的均值化处理的氧化碳排放清单训练 数据; 对环境监测站点周围每一圈网格区域内的均值化处理的二氧化碳排放清单训练 数据,和该圈网格区域内的大气PM2.5污染浓度训练数据,将上述二者组成的数据按照7:3划 分为训练集数据和测试集数据;即将70%的环境监测站点周围每一圈网格区域内的均值化 处理的二氧化碳排放清单训练数据,和该圈网格区域内的大气PM2.5污染浓度训练数据作为 训练集数据;将30%的环境监测站点周围每一圈网格区域内的均值化处理的二氧化碳排放 清单训练数据,和该圈网格区域内的大气PM2.5污染浓度训练数据作为测试集数据; 利用环境监测站点周围第N圈网格区域内的大气PM2 .5污染浓度训练数据,作为因 变量,利用环境监测站点周围第N圈网格区域内的均值化处理的二氧化碳排放清单训练数 据中的二氧化碳总排放训练数据,作为自变量,建立第一阶段非负Lasso模型; 其中, 第一预测结果;Xtt1表示环境监测站点周围第N圈网格区域内的均值化 处理的二氧化碳排放训练清单数据中的二氧化碳总排放训练数据构成的向量; 表示第 一模型系数训练估计值; 求解第一模型系数训练估计值时,构造以下目标函数: 其中, 为第一阶段训练平方误差; 表示训练正则项,λn1 为第一阶段训练正则项的权重系数; 将(8)中的目标函数转化为矩阵形式: 其中, 表示目标函数; 为 的转置;Xtt1′为Xtt1的转置;1表示维度为 p1×1且每项均为1的列向量;p1等于第一阶段模型系数的维数; 通过二次规划,求解第一阶段模型系数训练估计值 计算第一阶段非负Lasso模型的拟合误差respm2.5: 将(10)式中计算得到的拟合误差res,作为因变量;利用除二氧化碳总排放训练数 据之外剩余的二氧化碳排放训练清单数据,作为自变量(X-tt1),建立第二阶段非负Lasso模 型: 10 CN 111581792 A 说 明 书 5/14 页 其中,X-tt1为该地区的某个网格区域中的除二氧化碳总排放训练数据之外的剩下 的二氧化碳排放训练数据构成的向量,作为自变量; 表示第二阶段模型系数训练估计 值;respm2.5为第二预测结果; 求解第二模型系数训练估计值时,构造以下目标函数: 其中, 为第二阶段模型系数训练估计值; 为第二阶 段训练平方误差; 表示正则项;λm1为第二阶段训练正则项的权重系数; 将(12)中的目标函数转化为矩阵形式: 其中, 为 的转置;X-tt1′为X-tt1的转置;1表示维度为p2×1且每项均为1 的列向量;p2等于第二阶段模型系数的维数; 通过二次规划,求解第二阶段模型系数估计值 对于预留的30%测试集,分别使用训练得到的两阶段模型,进行预测,获得对应的 第一预测结果和第二预测结果,将两次预测结果相加得到环境监测站点的大气PM2.5浓度数 据的预测值: 利用相对百分比误差MAPE评价模型预测效果: 其中,observed t表示环境监测站点的大气PM 2 .5污染浓度数据的真实值; predictedt为环境监测站点的大气PM2.5浓度数据的预测值,即两阶段非负lasso模型输出 的预测结果;N1表示预测样本的数量;下标t用于标识第t样本; 对每个环境监测站点,对选取的环境监测站点周围的N圈网格区域中的每一圈网 格区域内的70%的二氧化碳排放清单数据和环境监测站点所属网格区域内的大气PM2.5污 染浓度数据,作为训练集数据,重复上述建模过程,直到模型效果评价指标MAPE在测试集数 据使得模型效果收敛,得到最终的两阶段非负Lasso模型。 本发明还提供了一种基于两阶段非负Lasso模型的大气PM2.5浓度预测系统,该系 统包括: 网格划分模块,用于将某一地区在空间层面上划分多个网格区域,对每个网格区 域利用自下而上的空间化方法核算出该网格区域内全年的二氧化碳排放数据,作为该网格 区域的二氧化碳排放清单数据;和 预测模块,用于将该地区的某网格区域的二氧化碳排放清单数据输入至预先训练 11 CN 111581792 A 说 明 书 6/14 页 的两阶段非负Lasso模型,输出第一预测结果和第二预测结果; 将第一预测结果和第二预测结果相加,获得该区域的PM2.5浓度数据预测结果。 本发明还提供了一种计算机设备,包括存储器、处理器及存储在所述存储器上并 可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实 现上述方法。 本发明还提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介 质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行上述方法。 本发明与现有技术相比的有益效果是: 利用两阶段非负Lasso模型,模拟出网格区域内的二氧化碳排放清单数据与附近 环境监测站点所属网格区域内的大气PM2.5浓度数据间的关系; 采用两阶段非负Lasso模型,能够保证在预测环境监测站点大气PM2.5浓度时,周围 的所有网格的二氧化碳排放清单数据均对预测PM2.5均产生积极的影响,即表现在模型中, 每个二氧化碳指标对应的系数都不为0,这样更加符合业务实际; 模型中的Lasso部分,可以压缩不重要的变量,去除指标之间的共线性,保证模型 的泛化能力; 在空间网格层面上,实现任意网格区域内的大气PM2 .5浓度数据的预测,从而完成 对空气质量影响的定量评估;快速、有效地实现地区的二氧化碳排放和大气污染物协同管 理。 附图说明 图1是本发明的一种基于两阶段非负Lasso模型的大气PM2.5浓度预测方法中的两 阶段非负Lasso模型在训练时的环境监测站点所属网格区域的空间相对位置示意图; 图2是本发明的一种基于两阶段非负Lasso模型的大气PM2.5浓度预测方法中的两 阶段非负Lasso模型的训练流程示意图; 图3是本发明的一种基于两阶段非负Lasso模型的大气PM2.5浓度预测方法中的两 阶段非负Lasso模型在完成训练之后采用测试集进行测试验证的环境监测站点的大气PM2.5 浓度的预测误差的分布直方图。











