
技术摘要:
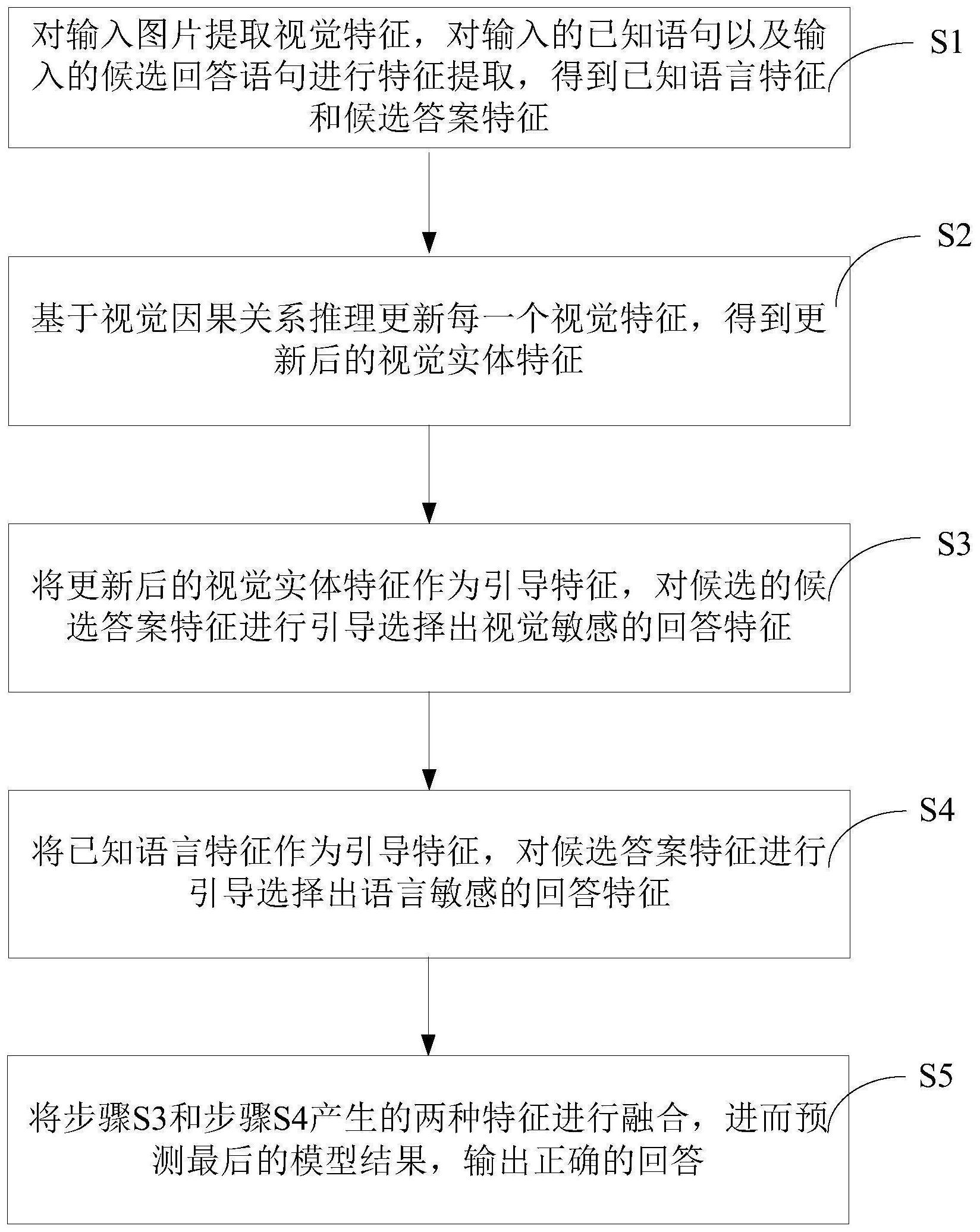
本发明公开了一种视觉问答任务实现方法及系统,该方法包括:步骤S1,对输入图片提取视觉特征Xo,对输入的已知语句以及输入的候选回答语句进行特征提取,得到已知语言特征Xq和候选答案特征Xc;步骤S2,基于视觉因果关系推理更新每一个视觉特征,得到更新后的视觉实体特 全部
背景技术:
基于视觉问答的任务是人工智能领域的一个基础问题,在计算机视觉和自然语言 处理的交叉领域中得到了日益增加的关注。近年来,视觉问答任务作为视觉和语言的交叉 领域的子问题,对人工智能领域的视觉导航、智能询问助手、家政辅导、情感对话机器人等 应用的辅助研究引起了热点关注。因为深度卷积神经网络的发展,该类问题得到了很大的 进步。现有的方法大多数是利用端到端的深度卷积神经网络的方法来直接融合视觉和语言 的特征来预测最终的回答,然而,该类方法缺少对网络的可解释性,同时也缺乏对问答推理 中的常识性场景进行视觉常识关系解析。相比而言,利用语言领域特有的问答因果关系嵌 入到视觉实体间关系,采用视觉因果关系推理的方法对视觉实体特征进行因果推理,同时 利用推理更新后的视觉特征结合语言特征来综合预测最终的基于常识的答案结果,可增强 网络在因果推理方面的认知能力,同时提升网络的总体性能。 目前在视觉问答方面的研究主要有以下两种方法:一种是简单利用端到端的深度 卷积神经网络的方法去直接融合视觉和语言的特征来预测回答,该类方法缺乏对网络的可 解释性,对单纯视觉数据敏感,同时也缺乏对问答推理中的常识性场景进行解析建模;另外 一种是单纯利用视觉实体间的属性相似性或类别相似性作为视觉实体间关系进行关系建 模,比如“人”这个视觉实体之间的相似性就很高,或者利用句子语义词和具体的视觉实体 建立语义对齐,比如句子中的“person”单词和视觉中的“人”的特征进行对齐,如图6的(a) 和(b)。然而,上述方法并没有对视觉常识关系进行有效建模的方法,让问答语句中的因果 关系无法有效地和视觉实体关系进行无缝衔接,从而无法达到赋予视觉关系因果性来提升 视觉常识问答推理任务的准确性。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种视觉问答任务实现 方法及系统,以实现一种将语言领域的因果关系引入到视觉领域进行视觉因果关系推理的 机制,拥有更高的预测精度和可解释性。 为达上述及其它目的,本发明提出一种视觉问答任务实现方法,包括如下步骤: 步骤S1,对输入图片提取视觉特征Xo,对输入的已知语句以及输入的候选回答语 句进行特征提取,得到已知语言特征Xq和候选答案特征Xc; 步骤S2,基于视觉因果关系推理更新每一个视觉特征,得到更新后的视觉实体特 征Xg; 步骤S3,将更新后的视觉实体特征Xg作为引导特征,对候选的候选答案特征Xc进行 4 CN 111598118 A 说 明 书 2/8 页 引导选择出视觉敏感的回答特征XV; 步骤S4,将已知语言特征Xq作为引导特征,对候选答案特征Xc进行引导选择出语言 敏感的回答特征XL; 步骤S5,将步骤S3和步骤S4产生的两种特征进行融合,进而预测最后的模型结果, 输出正确的回答。 优选地,步骤S2进一步包括: 步骤S200,初步构建视觉特征间的语义关联关系; 步骤S201,基于视觉特征Xo、已知语言特征Xq和候选答案特征Xc,利用语言层面的 问答因果关系生成视觉因果关系; 步骤S202,根据生成的视觉因果关系,采用视觉因果关系推理来更新每一个视觉 特征。 优选地,于步骤S200中,利用矩阵內积的方法初步构建视觉特征间的语义关联关 系。 优选地,步骤S201进一步包括: 将已知语言特征Xq和候选答案特征Xc进行串联,通过长短期记忆网络对语言问答 特征间的因果关系进行建模,得到初步的问答因果关系表征Xqc; 利用该问答因果关系表征Xqc嵌入到视觉特征Xo,构建每一个视觉实体和对应问答 因果关系间的关联Xoqc,搭建起视觉实体和语言因果关系的桥梁; 利用自注意力机制的操作结合矩阵乘法的操作,进一步生成视觉因果关系 Ag。 优选地,于步骤S202中,采用图卷积的操作,利用步骤S201得到的视觉因果关系, 对视觉特征实施视觉因果关系推理,得到更新后的视觉实体特征Xg。 优选地,步骤S3进一步包括: 融合更新后的视觉实体特征Xg和候选答案特征Xc,得到一个中间特征Xgc; 利用归一化表征进行投票学习得到和候选答案相关性强的若干视觉实体表征的 关系XVα; 利用该关系XVα作用于更新后的视觉实体特征Xg得到最终的视觉敏感的回答特征 XV。 优选地,于步骤S4中,在已知语言特征Xq的引导下,利用注意力机制在候选语言中 找到和已知语言的语义最相关的回答特征,作为所述语言敏感的回答特征XL。 优选地,于步骤S5中,利用步骤S4和步骤S3的输出特征,应用一个全连接的操作结 合串联操作,来预测出最后的问题答案表示。 优选地,步骤S1进一步包括: 步骤S100,利用物体检测器作为视觉特征提取网络,对输入图片I进行特征提取得 到视觉特征Xo; 步骤S101,采用一个共享权重的特征提取器分别对输入的已知语句以及输入的候 选回答语句进行特征提取,得到已知语句的语义特征表示Xq以及候选答案的语义特征表示 Xc。 为达到上述目的,本发明还提供一种视觉回答任务实现系统,包括: 基础视觉特征提取模块,用于对输入图片提取视觉特征Xo; 5 CN 111598118 A 说 明 书 3/8 页 语言特征提取模块,用于对输入的已知语句以及输入的候选回答语句进行特征提 取,得到已知语言特征Xq和候选答案特征Xc; 因果关系引导模块,用于基于视觉因果关系推理更新每一个视觉特征,得到更新 后的视觉实体特征Xg; 视觉引导模块,用于将更新后的视觉实体特征Xg作为引导特征,对候选的候选答 案特征Xc进行引导选择出视觉敏感的回答特征XV; 语言引导模块,用于将已知语言特征Xq作为引导特征,对候选答案特征Xc进行引导 选择出语言敏感的回答特征XL; 融合模块,用于将所述视觉引导模块和语言引导模块产生的两种特征进行融合, 进而预测最后的模型结果,输出正确的回答。 与现有技术相比,本发明一种视觉问答任务实现方法通过提出视觉因果关系推 理,并将其应用到通用的常识问答任务中,使得问答语句中的因果关系可以有效地和视觉 实体关系进行无缝衔接,从而达到赋予视觉关系因果性来提升视觉常识问答推理任务的准 确性的目的。本发明相比于近期的基于多种注意力机制预测、基于视觉实体间关系预测以 及利用语义词和具体视觉实体进行语义对齐的问答推理方法本发明不仅拥有更高的预测 精度和可解释性,而且提供了一种将语言领域的因果关系引入到视觉领域进行视觉因果关 系推理的机制。 附图说明 图1为本发明一种视觉问答任务实现方法的步骤流程图; 图2为本发明一种视觉回答任务实现系统的系统架构图; 图3为本发明具体实施例中因果关系引导模块的细部结构图; 图4为本发明具体实施例之视觉回答任务实现系统的系统框架图; 图5为本发明实施例中因果关系引导模块、语言引导模块以及视觉引导模块的示 意图; 图6示出本发明视觉因果关系推理与现有技术的区别。











