
技术摘要:
本发明公开了一种汉语唇语单音节识别分类器构建方法,包括步骤:S1、采集待识别汉字单音节的发音视频;S2、构建唇部特征点标注图像样本集;S3、训练唇部特征点提取模型;S4、将所录制的每个汉语单音节发音视频均匀切分得到若干帧采样图像;S5、利用训练所得的唇部特征 全部
背景技术:
随着人工智能技术的高速发展与计算机技术的普及,人脸识别、语音识别、瞳孔识 别等一系列生物特征识别技术近几年得到了迅速的发展,唇语识别技术也备受关注。唇语 识别技术是通过获取说话人说话时的唇部动作等信息并进行分析,识别出说话人想要表达 的意思。由此可见,唇语识别的技术关键在于如何从图像中提取唇部特征,提取哪些唇部特 征,如何表示具有时序性的唇部特征,唇部特征如何进行分类。这项技术所包含的技术领域 甚为广泛,主要涉及计算机视觉、机器学习与人工智能、模式识别、计算机图形图像处理等。 结合社会实际情况,唇语识别技术具有较为广泛的应用范围: (1)辅助语言障碍人士交流 根据中国残疾人联合会发布的最新数据调查结果显示,我国约有2200万语言障碍 人士,约占全国人口总数的1.5%,语言障碍人士数量庞大,由于先天或后天的原因,这些人 无法听到或发出声音,在生活中与他人沟通极为困难,因沟通问题所带给语言障碍人士的 困扰不只局限于生理层面,也体现在心理层面,语言障碍人士因沟通不便而带来的心理问 题更为严重。通过唇语识别技术的辅助识别,语言障碍人士可以尽可能表达自己的意思,普 通人也可以尽可能与语言障碍人士交流沟通。 (2)辅助嘈杂环境工作者交流 与语言障碍人士不同,嘈杂环境中的工作者可以听到声音也能发出声音,但由于 环境噪声的影响,工作者之间的交流很难准确捕获,因此难免会影响工作效率。通过唇语识 别技术的应用于辅助,可以帮助工作者在嘈杂环境中及时准确的捕获对方所要表达的信息 提高工作效率。 (3)辅助公共安全分析及刑侦分析 唇语识别技术对于公安执法部门的证据采集工作也有重要的帮助,在案件侦破过 程中,视频画面由于距离等一些因素导致视频声音缺损甚至丢失的情况较为常见,这样的 情况下直接导致案件的关键证据、线索无法获取得到。此类情况常发生于公共场所监控系 统中。通过唇语识别技术的辅助,能够分析出视频画面中的部分关键语音信息,协助缉查人 员推进案件的侦破。 (4)用于身份验证的唇动密码 由于发音习惯以及嘴型的不同,每个人私有的一段唇动变化具有其唯一性,可以 用来作为一种密码,该密码可以用来进行身份认证等。唇动密码在识别时会以唇语内容、嘴 唇特征和唇动特性为基本依据进行识别,具有较高的安全性。 国内外研究现状 吕品轩[1]提出了一种基于主动型状模型(ASM)的唇型特征提取方法,该方法采用 5 CN 111582195 A 说 明 书 2/9 页 14点主动形状模型,选择嘴唇模型的宽、高形状特征,通过曲线拟合得到的参数组合作为几 何特征,实验结果表明所提取到的特征均为有效特征,并使用隐马尔科夫模型(HMM)进行处 理特征,实验结果表明该方法能够达到一定的识别率,但与其他研究结果还有一定的差距 且未提及对汉语识别的准确率。 Preety Singh,Vijay Laxmi,Manoj Singh Gaur[2]利用最小冗余最大相关性 (mRMR)方法选择视觉相关特征,,测试不同数量的相关属性的特征向量已确定最佳特征集。 以此特征集作为基础向量,以帧为单位完成特征连接以构建n-gram模型,以便捕获语言的 时间特性。利用随机森林算法以及k-近邻算法进行分类。 以上两种方法中使用ASM模型提取唇部关键点,但是当图像中没有完整的人脸信 息时,ASM模型无法准确提取关键点。 杨龙生,贾振堂[3]提出了一种基于人工神经网络迁移学习的唇语识别系统,该系 统使用已有的英语唇语数据集作为训练集,首先对视频序列根据嘴唇之间的点距离与嘴巴 闭合时的相应点之间的距离的差值进行分割处理,使用dlib工具提取视频中每帧人脸的68 个关键点,并选择嘴唇附近20个点坐标线性化得到一个40维的向量压缩后作为人工神经网 络的输入,利用人工神经网络(ANN)长短期记忆模型(LSTM)识别唇语。该实验方案计算成本 较大且对汉语的泛化能力未知。 从国内外和研究现状来看,唇语识别技术的关键在于如何提取唇部信息,且提取 哪些关键特征并加以分类。目前已有的技术应用范围较窄,许多唇语识别实验尚未涉及汉 语识别,部分论文中技术路线描述较为模糊且所使用的数据集只公布了录制方法与录制内 容,但数据集并未公开,导致实验难以复现,无法确认其实验结果是否准确。 参考文献: [1]吕品轩.基于唇语身份识别的特征鉴别力分析[R].上海交通大学,2007. [2]Preety Singh,Vijay Laxmi,Manoj Singh Gaur.Department of Computer Engineering Malaviya National Institute of Technology Jaipur ,India 302017 [D]//International Conference on Advances in Computing ,Communications and Informatics(ICACCI-2012) ,pages 1199-1204. [3]杨龙生,贾振堂.用于可靠身份认证的唇语识别[J].电视技术,2018,42(10): 88-91 .YANG L S,JIA Z Lip-reading algorithm for reliable authentication[J] .Video engineering,2018,42(10):88-91.
技术实现要素:
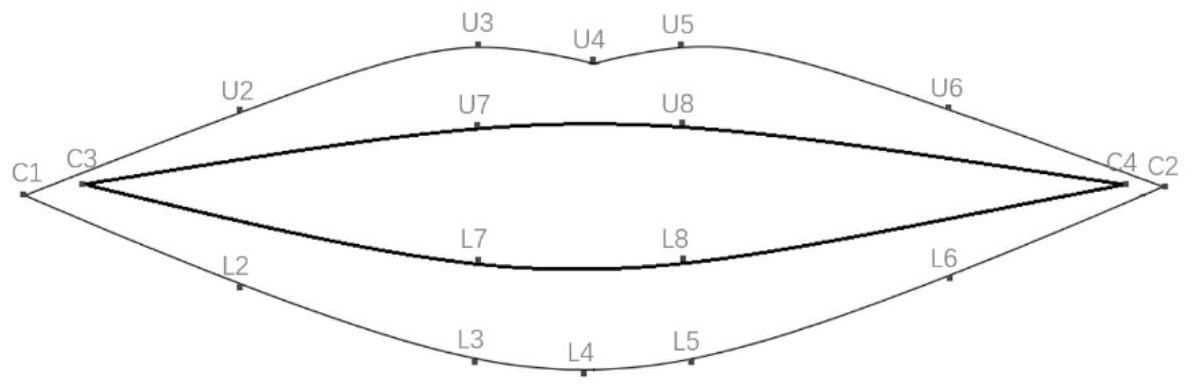
针对现有技术的不足,本发明旨在提供一种汉语唇语单音节识别分类器构建方 法。 为了实现上述目的,本发明采用如下技术方案: 一种汉语唇语单音节识别分类器构建方法,包括如下步骤: S1、采集待识别汉字单音节的发音视频; S2、构建唇部特征点标注图像样本集: 所述唇部特征点标注图像样本集的原始图像包括来自步骤S1中筛选的发音视频, 还包括来自其他视频的采样,图像中要求唇部信息完整,即唇部轮廓清晰可见; 6 CN 111582195 A 说 明 书 3/9 页 为每一幅原始图像的唇部边缘手工标注20个特征点得到唇部特征点标注图像,所 有唇部特征点标注图像的集合为唇部特征点标注图像样本集;特征点包括两侧唇角的外沿 点C1、C2,两侧唇角的内沿点C3、C4,两个唇峰的上唇外沿最高点U3、U5;两个唇峰间的上唇 外沿最低点U4,C1与U3之间的上唇外沿中间点U2,C2与U5之间的上唇外沿中间点U6,上唇内 沿点U7、U8,下唇外沿点L2、L3、L4、L5、L6;下唇内沿点L7、L8;U3与U7所在直线垂直于C3与C4 所在直线,U5与U8所在直线垂直于C3与C4所在直线;L2为C1与L3之间的下唇外沿中间点,L5 与U5所在直线垂直于C1与C2所在直线,L6与U6所在直线垂直于C1与C2所在直线;L6为C2与 L5之间的下唇外沿中间点;L4为C1与C2之间的下唇外沿中间点;L7与U7所在直线垂直于C3 与C4所在直线,L8与U8所在直线垂直于C3与C4所在直线; S3、训练唇部特征点提取模型: 训练集的唇部向量为: xi=(xi0,yi0,xi1,yi1,...,xi19,yi19)T; 式中,xi表示第i幅唇部特征点标注图像中的所有特征点构成的唇部向量,(xik, yik)表示图像中第k个特征点的横、纵坐标; 训练唇部特征点提取模型的具体步骤为: S3.1、从唇部特征点标注图像样本集中选择一个唇部模型作为基准模型,将唇部 特征点标注图像样本集中其他所有唇部模型对齐到基准模型,对齐是指将一系列唇部模型 通过旋转、平移、缩放变换,在不改变模型的基础上对齐到基准模型上; S3.2、计算平均唇部模型; S3.3、将唇部特征点标注图像样本集中所有唇部模型对齐到步骤S3.2计算得到的 平均唇部模型; S3.4、重复步骤S3.2-S3.3直到收敛,收敛的条件为使下式最小化: Ej=(x Ti-M(sj,θj)[xj]-tj) W(xi-M(sj,θj)[xj]-tj); 式中,xi、xj为第i幅和第j幅唇部特征点标注图像中的所有特征点构成的唇部向 量,i≠j;sj表示第j幅唇部特征点标注图像的唇部模型的缩放系数;M(sj,θj)[xj]为第j幅 唇部特征点标注图像的唇部模型的变化函数;tj表示第j幅唇部特征点标注图像的唇部模 型的平移向量,tj=(t Txj,tyj,…,txj,tyj) ,txj,tyj分别表示第j幅唇部特征点标注图像的唇 部模型每个点的横坐标和纵坐标的偏移量,每个点的横坐标和纵坐标的偏移量相等;θj表 示第j幅唇部特征点标注图像的唇部模型的旋转系数;W为一个对角矩阵,其对角线中的每 一项为 k表示唇部模型中的一个特征点,其中,n为唇部模型中特征 点的个数,Rkl表示唇部模型中两个特征点k和l之间的距离; 表示距离Rkl的方差; S4、将步骤S1中采集的待识别汉语单音节发音视频均匀切分得到采样图像; S5、利用步骤S3训练所得的唇部特征点提取模型对步骤S4所得的每一帧采样图像 分别进行特征点提取,提取过程具体为: S5.1、对唇部特征点提取模型进行仿射变换得到一个初始模型: 7 CN 111582195 A 说 明 书 4/9 页 X=M(Tp) Xc; 该式表示对唇部特征点提取模型通过仿射变换Tp以及平移Xc得到初始模型X; S5.2、使用初始模型X在步骤S4所得的每一帧图像中搜索目标形状,使搜索到的最 终形状中的特征点和相对应的真正特征点最为接近;每一帧图像提取得到的特征点构成唇 部特征点集; S6、根据步骤S5所得的唇部特征点集,分别构建每一帧图像的唇部几何特征;根据 两点之间距离,构建几何特征序列X=(W1,W2,…,W8,H1,H2,H3)如下: W1=D(C1,C2); W2=D(U2,U6); W3=D(U3,U5); W4=D(L2,L6); W5=D(L3,L5); W6=D(C3,C4); W7=D(U7,U8); W8=D(L7,L8); H1=D(U2,L2); H2=D(U3,L3); H3=D(U4,L4); 其中,W1,W2,…,W8,H1,H2,H3为人为设定的几何特征名称; 按顺序组合所得的几何特征序列,得到同一汉语单音节发音视频的11维几何特 征;将同一汉语单音节发音视频的图像的几何特征保存并归一化; 将每个几何特征序列X=(W1,W2,…,W8,H1 ,H2,H3)线性组合μ得到一组新的几何 特征序列Y=(Y1,Y2,…,Y7): Y=μXT; T为转置符; S7、将步骤S6中所得的新的属于同一发音视频的帧的全部几何特征序列按顺序保 存,并标明所属类别,得到每个发音视频的特征矩阵;类别为人为设定,以整数f为类别标签 (f=0,1,2,…); S8、利用步骤S7所得每个发音视频的特征矩阵,训练得到唇语识别器。 进一步地,步骤S1的具体过程为: 采集多个来自不同的人的完整发音视频,然后对于每个待识别汉字单音节,从不 同的人的完整发音视频中筛选出设定数量的唇部区域无遮挡、唇部变化过程明显的发音视 频。 进一步地,步骤S1中,录制发音视频时,选择在白天自然光室内录制,录制时背景 为白色墙壁,录制者正对摄像机,录制者面部与摄像机镜头保持水平且距离为75cm;要求录 制出发音时嘴型从闭合开始到闭合结束,以确保能够录制到每一个音节的嘴型变化的全部 过程;每位录制者的每个汉语单音节发音对应一个独立的视频文件,每个视频文件标明对 应的音节。 进一步地,步骤S4中,切分时分别以设定的帧数作为间隔,不同间隔的切分采样设 8 CN 111582195 A 说 明 书 5/9 页 置为对照组实验,以确定最合适的采样帧间隔。 进一步地,步骤S6中,归一化的过程为:将同一汉语单音节发音视频中的几何特征 的组合看作一个特征矩阵,归一化时选择特征矩阵中的最大值max(A),特征矩阵中的每一 个值都除以这个最大值作为新的矩阵中的值,即: A'(i,j)=A(i,j)/max(A) 其中,A’(i,j)表示归一化后的特征矩阵,A(i,j)表示原始特征矩阵。 进一步地,步骤S8的具体过程为: 将步骤S7中所得的特征矩阵以4:1的比例随机分为训练集与验证集;训练集用于 唇语识别器的训练,训练完成输出一个权重矩阵Q;验证唇语识别器的分类准确度时,输入 验证集与权重矩阵Q,输出一组分类结果,将输出的分类结果与验证集的标签做统计,得到 唇语识别器的分类准确率。 进一步地,步骤S8中,唇语识别器采用softmax分类器。 本发明的有益效果在于:相对于现有技术而言,本发明具有训练数据规模较小、模 型训练时间较短、唇语识别准确率较高、唇语识别时长较短的有益效果。 附图说明 图1为本发明实施例1中唇部轮廓特征点设计示意图; 图2为本发明实施例1中唇部特征设计示意图。











