
技术摘要:
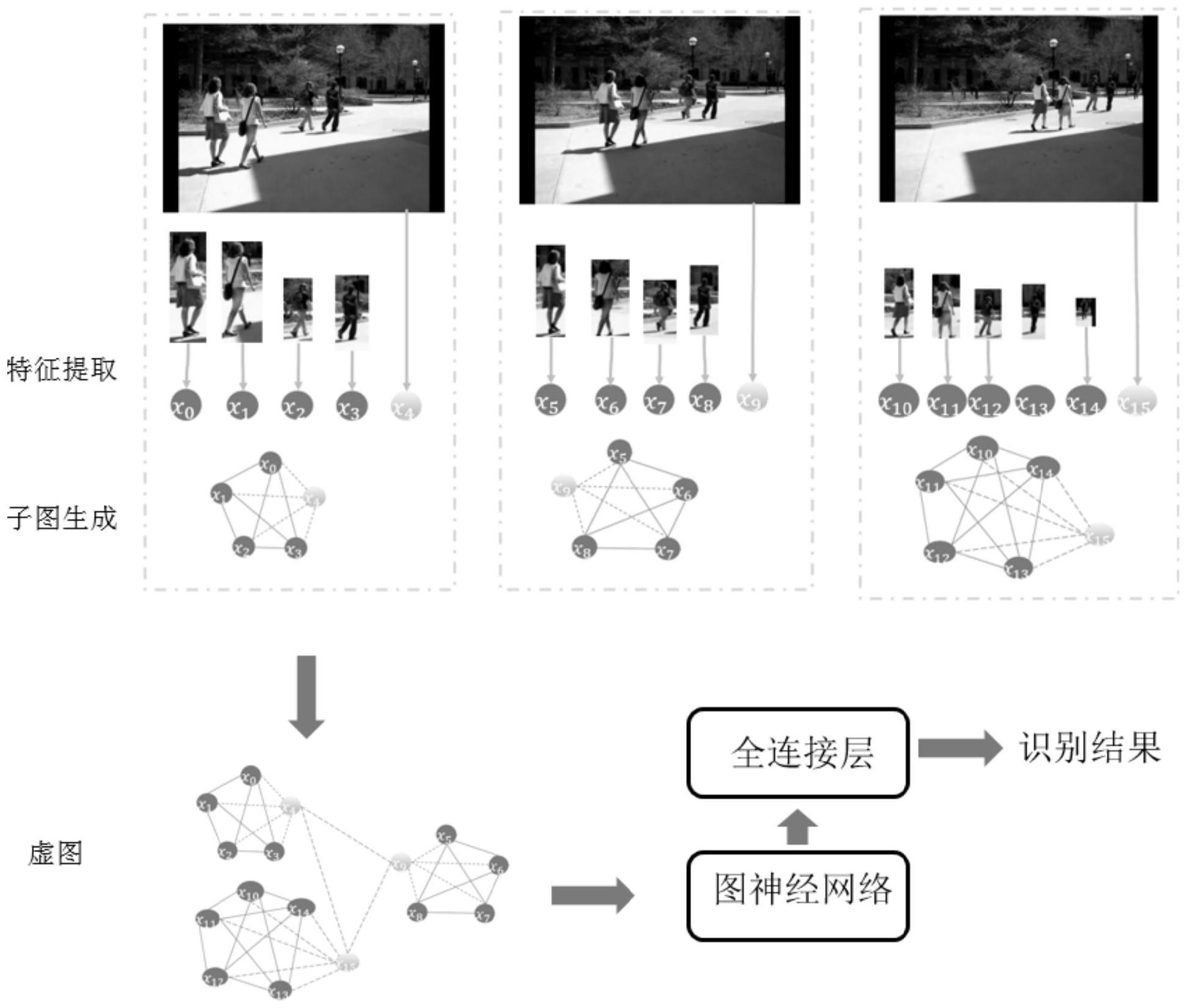
本发明公开了一种基于图神经网络的群体行为识别方法,方法包括以下步骤:特征提取,对单位时间内视频段的个体视觉特征进行提取,获取每个人的特征表达与整个场景特征表达;生成虚图,根据得到的每个人的特征表达与场景特征表达生成全连接的无向图,在无向图中引入虚节 全部
背景技术:
给定一段视频,智能识别系统需要对该段视频中所涉及的群体行为进行识别。这 涉及对视频中的内容在空间上和时间上进行分析。 目前主要的识别方法是将视频片段输入一个三维卷积神经网络,由三维卷积神经 网络在三维空间里进行特征提取,并直接输出对视频的识别结果。或者抽取视频中的多帧 图片,对每帧图片都输入一个二维卷积神经网络,由二维卷积神经网络对每帧图片进行识 别结果判别,并平均多个帧的识别结果作为最终结果。 一般的识别方法无论用的是二维卷积神经网络还是三维卷积神经网络,都存在一 定的不足。对二维卷积神经网络来说,对帧进行特征提取,每次输入二维卷积网络只有一帧 图像,所得到特征缺少时间维度的信息。三维卷积神经网络解决了二维卷积神经网络时间 维度上的不足,但这种时间维度缺少在不同时刻上的信息交流。并且,两者都由于输入为整 张图片或整个视频片段,因此是基于全局的特征,缺少对局部关键信息、各个局部信息之间 互相影响、各个局部信息和整体信息互相影响的刻画,如人与人互动的信息和人与环境互 动信息的刻画。
技术实现要素:
本发明的主要目的在于克服现有技术的缺点与不足,提出一种基于图神经网络的 群体行为识别方法;本发明定义了一种新型的基于虚节点的图神经网络,可以学习到视频 中丰富的时间空间特征,从而帮助对视频中的群体行为进行准确的识别。 为了达到上述目的,本发明采用以下技术方案: 一种基于图神经网络的群体行为识别方法,包括以下步骤: 特征提取,对单位时间视频端的个体进行检测,并依据检测到个体的位置,在空间 和时间上进行视频切片,然后将视频切片输入到三维残差卷积网络进行特征提取,获取每 个个体的特征表达与整个场景特征表达; 生成虚图,根据得到的每个个体的特征表达与场景特征表达,将每个个体视为图 的一个节点,计为实节点,将所有实节点两两相连,得到全连接的无向图,在无向图中引入 虚节点,将虚节点与原图中的节点连接,形成虚图; 对多个图进行虚拟节点引入形成的虚图进行图神经网络的更新,更新后的图神经 网络层具有充分的特征表达能力; 构建图神经网络,表达图神经网络层,根据图神经网络层的表达式构建图神经网 络模型; 群体行为识别,将完整的虚图导入到图神经网络模型,进行非线性变换归一化处 6 CN 111598032 A 说 明 书 2/9 页 理,对预测类标和真实类标进行误差计算。 进一步的,所述特征提取具体为: 对于单位时间的视频段,随机采样图像并按时间顺序排列; 将最后一帧图像送进yolo-v3检测网络,得到多个包含个体的检测框; 对于每个个体的检测框,按照检测框的位置和大小,对随机抽取图片进行截取; 对每个截取的分割图,对其大小进行改变并将多张同个检测框的分割图按时间顺 序叠加,得到图像块; 将图像块送入三维残差卷积神经网络进行特征提取,特征取残差网络最后一个池 化层的输出,特征维度为512维。 进一步的,所述yolo-v3使用的是经过COCO数据库预训练的参数;所述三维残差卷 积神经网络使用经过Kinetics预训练的34层三维残差卷积网络参数。 进一步的,所述生成虚图具体为: 根据得到的每个个体的特征表达与整体场景特征表达,将每个个体视为图的一个 节点,将所有节点两两相连,得到全连接的无向图; 在得到的无向图中引入一个新节点,称其为虚拟节点,将原图中所有节点与虚拟 节点连接,形成包含虚拟节点的子图;在此基础上,将多个子图中的虚拟节点两两连接,形 成完整的虚图;则虚拟节点特征代表该图的整体特征,虚拟节点与原图节点的边的连接,代 表了该图整体特征与局部特征之间的交互,将引入虚拟节点后的新图称为虚图,实节点与 实节点之间的连接称为实连接,实节点与虚拟节点之间的连接称为虚连接,虚节点与虚节 点之间的连接也称为虚连接。 进一步的,所述图神经网络更新具体为: 对所有节点特征进行一个线性变换,每个节点特征线性变换后得到的特征yi表示 为: yi=Θxi 其中Θ为一个所有节点共享的线性变换矩阵,xi为节点特征,Θ∈RF′xF,x Fi∈R ,yi ∈RF′,R代表实数空间,其右上角上标为实数空间的维度,RF代表其为F维的实数空间,RF′代 表其为F′维的实数空间,RF′xF代表其为F′xF维的实数空间;Θ是一个可学习的参数,由所有 节点特征共享。 进一步的,所述节点的新特征由该节点特征和与其相邻节点特征的加权和表示, 表示为: 其中N(i)代表与节点i相邻的所有节点的集合;αij为归一化的权重参数,αij满足 ∑j∈N(i)∪{i}αij=1,0<αij<1,当j与i相等时,αij则表示为αii,表示节点本身的加权系数;y′i 为节点i经过信息传播后整合相邻节点的信息和自身信息的特征。 进一步的,所述图神经网络更新还包括下述步骤: 区分实节点和虚节点的作用,对αij做如下的区分: 当节点i和节点j相连且都是实节点时,节点i和节点j连接到同一个虚拟节点V(i, j);引入注意力机制对节点i和节点j之间的αij参数进行信息嵌入,将αij表示为特征yi、yj和 7 CN 111598032 A 说 明 书 3/9 页 yV(i,j)的函数,其表示如下: αij=exp{LeakyReLU(aT[yi||yj||yV(i,j)])} 其中LeakyReLU是一种常见的神经网络激活函数,a∈R3F′,R3F′代表一个维度为3乘 以F′的实数空间,该空间所有的元素为一个3乘以F′的向量,该向量的数值为实数;a是由所 有节点共享的可学习的参数;||代表将两个向量拼接成一个向量;V(i,j)表示节点i和节点 j连接到的同一虚拟节点; 当节点i和节点j相连且其中一个为虚拟节点时,通过节点i的特征yi和节点j的特 征yj之间的向量相似性的大小来确定系数αij;当相似程度大时,系数取值大,当相似程度 小,系数也相应取值小,用向量之间的内积来衡量这种相似性,此时αij表示如下: 当αij的所有取值确定时,对其进行归一化处理,得到归一化后的α′ij: 所述节点的特征的表示改为: 为了得到更高维度的空间,对y′i进行非线性变换: x′i=ReLU(y′i) x′i为图卷积层新的节点特征。 进一步的,所述构建图神经网络具体为: 构建图神经网络层,用如下公式表示: 其中Θ∈RF′xF,a∈R3F′为学习参数;βij为αij未进行归一化时的数值; 图神经网络层将虚图的节点特征集合X作为输入,将新的节点特征集合X′作为输 出,将其抽象为: X′=f(X) 将n个图神经网络层叠加,将当前层的输出作为下一层的输入,则图神经网络第L 层表示为: XL=fL(XL-1) 其中1≤L≤n,XL-1为第L层输入的节点特征集合;为表征整个图的特征,将最后一 8 CN 111598032 A 说 明 书 4/9 页 层图神经网络层输出的所有节点特征进行平均,作为该图的全局特征hgraph,表示如下: 其中N为图节点的个数,Xn为图神经网络第n层的节点特征集合。 进一步的,所述导入到图神经网络具体为: 将得到的完整的虚图导入到图神经网络,表示为: hgraph=g(X) 其中函数g代表图神经网络,hgraph为图神经网络输出的全局特征; 非线性变换归一化处理,得到识别的群体行为类别的后验概率为: p(y|hgraph)=φ(Wouthgraph) 其中,φ为softmax激活函数,Wout是可学习参数矩阵,其行数为群体行为类别数,y 为群体行为类别的概率变量的向量表示; 在得到分类的后验概率后,利用交叉熵损失函数对预测类标和真实类标进行误差 计算: 其中θ为模型需要学习的参数,n是群体行为类标的个数,yk为真实类标,yk为1则该 视频片段属于第k类群体行为,为0则不属于;pk为所述群体行为类别后验概率p的第k个元 素。 进一步的,当预测的结果与现实真实结果不一致时,L(θ)取值较大,从而在训练时 对网络中的参数进行惩罚,最终使得预测的结果与真实事件类标更为接近。 本发明与现有技术相比,具有如下优点和有益效果: 1、本发明在每个时间单位引入代表该单位时间内整体信息的虚拟节点,通过不同 时刻上多个虚拟节点之间的信息传递,每个虚拟节点与该时间单位的实际图节点之间的信 息流动,每个单位时间内的实际图节点内部的信息交换这三种信息流动方式,使得该图神 经网络在信息交互的过程中充分考虑到了个体和个体的交互,个体和整体环境的交互,整 体环境在不同时间单位上的交互,使得视频特征得到充分的表达,让模型既能聚焦局部,又 能兼顾整体,同时跨时间整合信息。本发明提出的模型能对视频进行良好的特征描述,从而 实现对视频中群体行为进行准确识别。 2、本发明为捕捉视频中所有个体与个体之间关系的交互,个体与环境之间的交 互,不同时间环境的信息交流,定义了新型的基于虚节点的图神经网络,从而获得一个更加 完整的行为特征描述,进而有效地对群体行为进行识别。 3、本发明在对图神经网络进行更新时,对于实连接,引入注意力机制,注意力机制 是一种被验证过得有效提升序列学习任务效果的一种方法。 4、对于虚连接,本发明通过内积充分考虑向量空间的相似性,从而对目标数据进 行加权变换,有效地提高对信息的获取能力和筛选能力。 9 CN 111598032 A 说 明 书 5/9 页 附图说明 图1是本发明的整体流程示意图; 图2是本发明单个图虚拟节点引入的示意图; 图3是本发明多个图虚拟节点引入的示意图。











