
技术摘要:
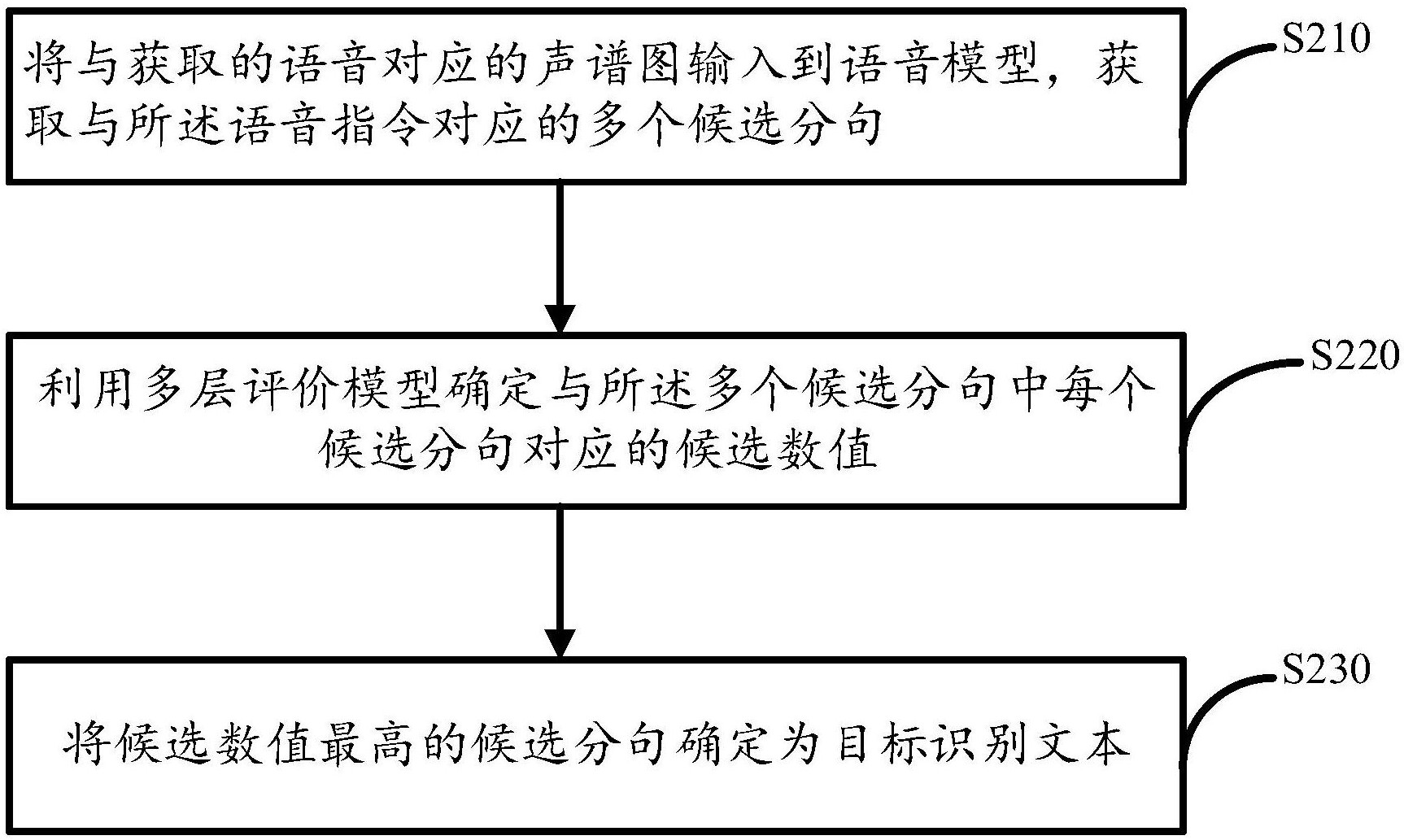
本申请公开了一种语音识别的方法及其装置,所述方法包括:将与获取的语音对应的声谱图输入到语音模型,获取与所述语音对应的多个候选分句;利用多层评价模型确定与所述多个候选分句中每个候选分句对应的候选值;将候选值最高的候选分句确定为目标识别文本。采用本申请 全部
背景技术:
随着信息化社会的发展以及信息技术的进步,语音识别技术经历了从无到有,从 稚嫩到成熟的发展过程,现有语音识别技术无论是从识别速度上还是从识别准确度上,均 可满足人们对语音识别的基本需求。 但是在很多场景中对语音识别的准确度提出了更高的挑战,例如,医疗场景中,如 何能够更准确且高效地识别医务工作人员的语音信息且自动转化成文字信息,可以极大提 升医院的整体效率,需要一种能够更准确地执行语音识别的技术方案。
技术实现要素:
本申请的主要目的之一在于提供一种语音识别的方法及其装置,旨在至少解决以 上提到的问题 本申请实施例提供一种语音识别的方法,所述方法包括:将与获取的语音对应的 声谱图输入到语音模型,获取与所述语音对应的多个候选分句;利用多层评价模型确定与 所述多个候选分句中每个候选分句对应的候选值;将候选值最高的候选分句确定为目标识 别文本。 本申请实施例还提供一种语音识别装置,包括:处理器;以及被安排成存储计算机 可执行指令的存储器,所述可执行指令在被执行时使所述处理器执行如上方法。 本申请实施例提供一种语音识别的方法,所述方法包括:获取与语音对应的多个 候选分句;利用多层评价模型确定与所述多个候选分句中每个候选分句对应的候选值;将 候选值最高的候选分句确定为目标识别文本。 本申请实施例提供一种语音识别的方法,所述方法包括:将与获取的语音对应的 声谱图输入到多层语音识别模型,获取数值最高的候选分句作为与所述语音对应的目标识 别文本。 本申请实施例采用的上述至少一个技术方案能够达到以下有益效果: 根据本申请的示例性实施例的语音识别的方法及其装置可利用多层评价模型对 利用语音模型输出的多个候选分句执行量化处理,从而能够更准确且直观地确定目标识别 文本。 附图说明 此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申 请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中: 图1是根据本申请的示例性实施例的语音识别方法的场景图; 图2是根据本申请的示例性实施例的语音识别方法的流程图; 4 CN 111599363 A 说 明 书 2/8 页 图3是根据本申请的示例性实施例的语音识别方法的示图; 图4是根据本申请的示例性实施例的语音识别装置的框图。











