
技术摘要:
本申请公开了一种排行榜生成方法、系统、服务器及存储介质,属于计算机技术领域。本申请通过先由至少两个第一服务器对属于各自分区的用户数据进行排序,生成各个分区对应的子排行榜,再由第二服务器基于子排行榜的数据顺序,对各个子排行榜中的用户数据进行分批次读取 全部
背景技术:
在网络游戏中,为促进玩家之间的竞争,通常设置有排行榜。对于采用分区分服架 构的网络游戏,不仅可以设置有用户当前所在区服的排行榜,还可以设置有全服排行榜,使 用户可以了解到全服玩家的排名状况。目前,在生成全服排行榜时,需要服务器先将各个区 服全部玩家的数据加载到内存中,再对这些玩家的数据进行排序,得到全服排行榜。 但是,应用上述排行榜生成方法,在全服玩家数量较大的情况下,加载全服玩家的 数据会占用服务器过多的内存空间,而且,在进行数据排序时,随着数据量的增大,服务器 的运算量、运算复杂度会大大增加,这不仅影响运算效,还会严重损耗服务器的性能。因此, 在生成排行榜时,如何降低服务器的内存占用以及降低服务器的性能损耗,是一个重要研 究方向。
技术实现要素:
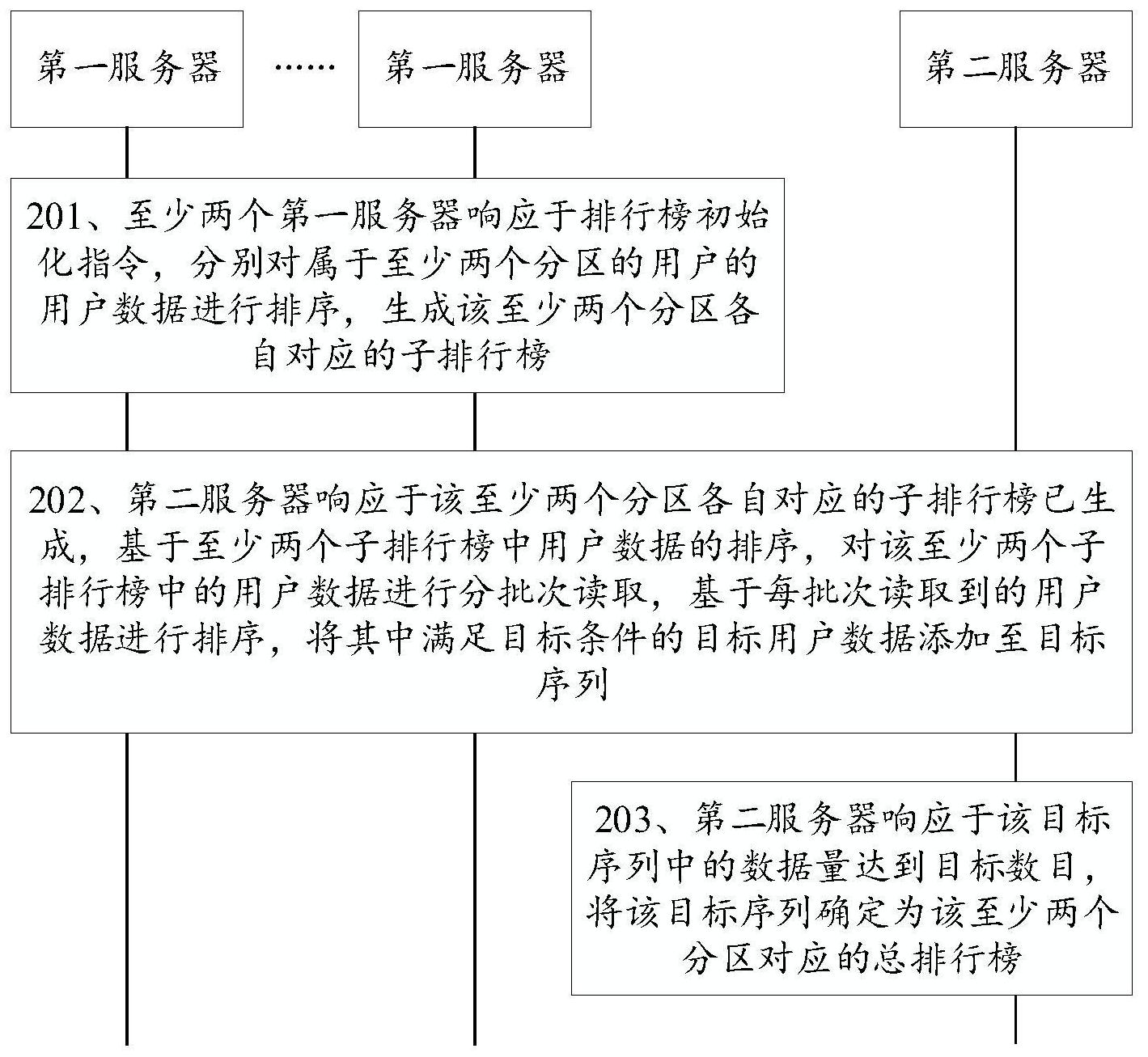
本申请实施例提供了一种排行榜生成方法、系统、服务器及存储介质,可以降低排 行榜生成过程中,服务器的内存占用以及性能损耗。该技术方案如下: 一方面,提供了一种排行榜生成方法,应用于用户数据处理系统,该用户数据处理 系统包括至少两个第一服务器以及第二服务器,一个该第一服务器对应于一个分区,该方 法包括: 该至少两个第一服务器响应于排行榜初始化指令,分别对属于至少两个分区的用 户的用户数据进行排序,生成该至少两个分区各自对应的子排行榜; 该第二服务器响应于该至少两个分区各自对应的子排行榜已生成,基于至少两个 子排行榜中用户数据的排序,对该至少两个子排行榜中的用户数据进行分批次读取,基于 每批次读取到的用户数据进行排序,将其中满足目标条件的目标用户数据添加至目标序 列; 该第二服务器响应于该目标序列中的数据量达到目标数目,将该目标序列确定为 该至少两个分区对应的总排行榜。 一方面,提供了一种排行榜生成系统,该系统包括至少两个第一服务器以及第二 服务器; 该至少两个第一服务器,用于响应于排行榜初始化指令,分别对属于至少两个分 区的用户的用户数据进行排序,生成该至少两个分区各自对应的子排行榜; 该第二服务器响,用于应于该至少两个分区各自对应的子排行榜已生成,基于至 少两个子排行榜中用户数据的排序,对该至少两个子排行榜中的用户数据进行分批次读 取,基于每批次读取到的用户数据进行排序,将其中满足目标条件的目标用户数据添加至 5 CN 111569435 A 说 明 书 2/14 页 目标序列;响应于该目标序列中的数据量达到目标数目,将该目标序列确定为该至少两个 分区对应的总排行榜。 在一种可能实现方式中,任一分区对应的该第一服务器,用于响应于对该任一分 区的子排行榜查看指令,将该子排行榜发送至目标终端进行显示。 在一种可能实现方式中,该第二服务器,用于响应于对总排行榜查看指令,将该总 排行榜发送至目标终端进行显示。 在一种可能实现方式中,该第二服务器,还用于接收目标用户的用户排名获取指 令,该用户排名获取指令包括该目标用户的用户标识以及所属分区的分区标识;响应于该 总排行榜中包括该用户标识,基于该总排行榜以及该用户标识确定该目标用户的用户排 名;响应于该总排行榜中不包括该用户标识,基于该分区标识,从该分区标识所指示的第一 服务器中获取该目标用户对应的子排行榜,基于该目标用户对应的子排行榜、该总排行榜, 确定该目标用户的排名区间。 一方面,提供了一种服务器,该服务器包括一个或多个处理器和一个或多个存储 器,该一个或多个存储器中存储有至少一条程序代码,该至少一条程序代码由该一个或多 个处理器加载并执行以实现该排行榜生成方法中第一服务器所执行的操作。 一方面,提供了一种服务器,该服务器包括一个或多个处理器和一个或多个存储 器,该一个或多个存储器中存储有至少一条程序代码,该至少一条程序代码由该一个或多 个处理器加载并执行以实现该排行榜生成方法中第二服务器所执行的操作。 一方面,提供了一种计算机可读存储介质,该计算机可读存储介质中存储有至少 一条程序代码,该至少一条程序代码由处理器加载并执行以实现该排行榜生成方法中第一 服务器或第二服务器所执行的操作。 一方面,提供了一种计算机程序产品,该计算机程序产品包括计算机指令,该计算 机指令存储在计算机可读存储介质中。第一服务器或第二服务器的处理器从计算机可读存 储介质读取该计算机指令,处理器执行该计算机指令,使得该第一服务器或该第二服务器 执行上述排行榜生成方法所执行的操作。 本申请实施例提供的技术方案,先由至少两个第一服务器对属于各自分区的用户 数据进行排序,生成各个分区对应的子排行榜,再由第二服务器基于各个子排行榜的数据 顺序,对各个子排行榜中的用户数据进行分批次读取,无需一次性加载各个分区的全部用 户数据,从而降低对第二服务器的内存占用;在对用户数据进行排序时,第一服务器基于每 批次读取到的用户数据进行排序,将其中满足目标条件的目标用户数据添加至总排行榜的 数据序列中,直到总排行榜的数据量达到目标数据,在这一过程中,每次排序所涉及的数据 量均较小,从而有效降低了排序时第一服务器的运算量和运算复杂度,降低服务器的性能 损耗。 附图说明 为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使 用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于 本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他 的附图。 6 CN 111569435 A 说 明 书 3/14 页 图1是本申请实施例提供的一种排行榜生成方法的实施环境示意图; 图2是本申请实施例提供的一种排行榜生成方法的流程图; 图3是本申请实施例提供的一种排行榜生成方法的时序图; 图4是本申请实施例提供的一种排序方法的示意图; 图5是本申请实施例提供的一种排序方法的示意图; 图6是本申请实施例提供的一种总排行榜生成方法的示意图; 图7是本申请实施例提供的一种子排行榜显示页面的示意图; 图8是本申请实施例提供的一种总排行榜显示页面的示意图; 图9是本申请实施例提供的一种排行榜生成系统的示意图; 图10是本申请实施例提供的一种终端的结构示意图; 图11是本申请实施例提供的一种服务器的结构示意图。











