
技术摘要:
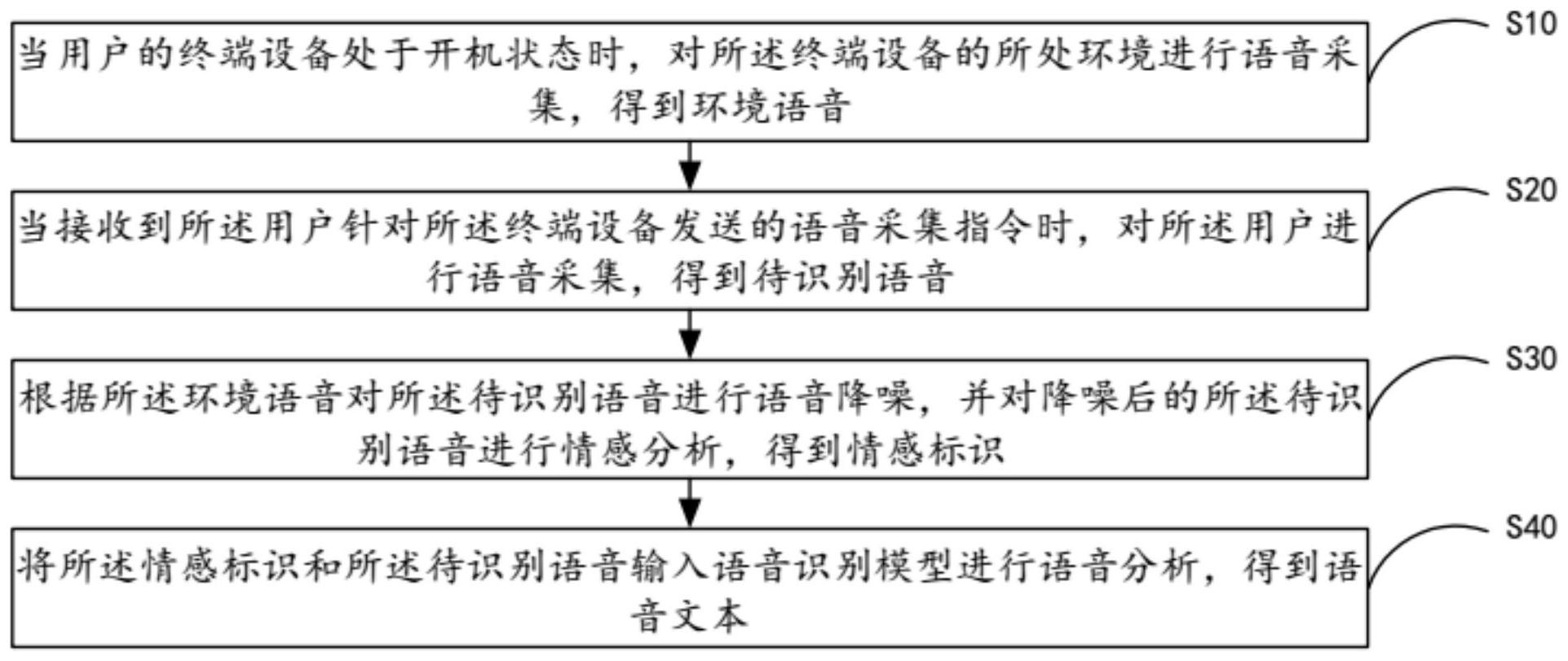
本发明适用于语音识别技术领域,提供了一种语音识别方法、系统、移动终端及存储介质,该方法包括:当用户的终端设备处于开机状态时,对终端设备的所处环境进行语音采集,得到环境语音;当接收到用户针对终端设备发送的语音采集指令时,对用户进行语音采集,得到待识别 全部
背景技术:
语音识别技术,简要来说就是让机器通过识别和理解过程把语音信号转变为相应 的文本或命令的技术。语音识别技术主要包括声音特征提取技术、模式匹配准则及模型训 练技术等方面。目前语音识别技术已经得到快速的发展以及广泛的使用。但是,在环境噪声 较大的环境下,例如在体育场等嘈杂背景的环境下,语音识别技术的应用却受到了很大的 限制,因此,语音识别准确性的问题越来越受人们所重视。 现有的语音识别方法使用过程中,均是通过采用降噪器的方式实现背景声的降 噪,但由于降噪器是针对指定语音音频进行降噪,并不能对用户所处的不同场景的背景音 进行降噪,进而导致其语音降噪效率低下,降低了语音识别的准确性。
技术实现要素:
本发明实施例的目的在于提供一种语音识别方法、系统、移动终端及存储介质,旨 在解决现有的语音识别方法中,由于采用降噪器进行背景声降噪所导致的识别准确性低下 的问题。 本发明实施例是这样实现的,一种语音识别方法,所述方法包括: 当用户的终端设备处于开机状态时,对所述终端设备的所处环境进行语音采集, 得到环境语音; 当接收到所述用户针对所述终端设备发送的语音采集指令时,对所述用户进行语 音采集,得到待识别语音; 根据所述环境语音对所述待识别语音进行语音降噪,并对降噪后的所述待识别语 音进行情感分析,得到情感标识; 将所述情感标识和所述待识别语音输入语音识别模型进行语音分析,得到语音文 本。 更进一步的,所述根据所述环境语音对所述待识别语音进行语音降噪的步骤包 括: 获取所述待识别语音的语音采集时间,所述语音采集时间包括起始时间和终止时 间; 根据第一预设截取时间截取所述环境语音在所述起始时间之前的语音信息,得到 第一噪声语音; 根据第二预设截取时间截取所述环境语音在所述终止时间之后的语音信息,得到 第二噪声语音; 将所述第一噪声语音和所述第二噪声语音与所述待识别语音进行语音比对,并根 4 CN 111613223 A 说 明 书 2/11 页 据比对结果对所述待识别语音进行去噪处理。 更进一步的,所述对降噪后的所述待识别语音进行情感分析的步骤包括: 获取所述待识别语音的基频特征、共振峰特征和MFCC特征,并将所述基频特征、所 述共振峰特征和所述MFCC特征进行特征组合,得到特性向量; 将所述特征向量与本地预存储的情感数据库进行匹配,以得到所述情感标识,所 述情感标识为生气、高兴、害怕、悲伤、惊讶或中性。 更进一步的,所述获取所述待识别语音的基频特征、共振峰特征和MFCC特征的步 骤包括: 采用自相关函数法或平均幅度差法分析所述待识别语音中的时域信号,得到所述 基频特征; 采用倒谱法将所述待识别语音中的基音信息和声道信息进行分离,以得到所述共 振峰特征,或采用线性预测分析方法以获取所述待识别语音中的所述共振峰特征; 通过对所述待识别语音进行预加重、分帧、加窗、快速傅里叶变换、谱线能量计算、 滤波器滤波和散余弦变换处理,以得到所述MFCC特征。 更进一步的,所述将所述情感标识和所述待识别语音输入语音识别模型进行语音 分析的步骤之前,所述方法还包括: 对所述用户当前所处环境进行图像采集,得到环境图像,并获取所述环境图像中 的背景图像和设备图像; 根据所述设备图像和所述背景图像获取所述用户当前所处环境的场景标识,并将 所述场景标识、所述情感标识和所述待识别语音输入所述语音识别模型进行语音分析。 更进一步的,所述根据所述环境语音对所述待识别语音进行语音降噪的步骤包 括: 获取所述待识别语音的语音采集时间,所述语音采集时间包括起始时间和终止时 间; 获取所述环境语音中所述起始时间至第一预设时间点之间的语音信息,得到第一 采样语音,并对所述第一采样语音中的音频信息进行变化分析; 获取所述第一采样语音中最大音频变化点所对应的时间点,并将最大音频变化点 所对应的时间点设置为第一截取点; 获取所述环境语音中第二预设时间点至所述终止时间之间的语音信息,得到第二 采样语音,并对所述第二采样语音中的音频信息进行变化分析; 获取所述第二采样语音中最大音频变化点所对应的时间点,并将最大音频变化点 所对应的时间点设置为第二截取点; 获取所述环境语音中所述起始时间至所述第一截取点之间的语音信息,得到第三 噪声语音; 获取所述环境语音中所述第二截取点至所述终止时间之间的语音信息,得到第四 噪声语音; 将所述第三噪声语音和所述第四噪声语音与所述待识别语音进行语音比对,并根 据比对结果对所述待识别语音进行去噪处理。 更进一步的,所述将所述情感标识和所述待识别语音输入语音识别模型进行语音 5 CN 111613223 A 说 明 书 3/11 页 分析的步骤之前,所述方法还包括: 对所述用户当前所处环境进行定位,得到位置信息,并根据所述位置信息查询方 言标识; 将所述方言标识、所述情感标识和所述待识别语音输入所述语音识别模型进行语 音分析。 本发明实施例的另一目的在于提供一种语音识别系统,所述系统包括: 环境语音采集模块,用于当用户的终端设备处于开机状态时,对所述终端设备的 所处环境进行语音采集,得到环境语音; 用户语音采集模块,用于当接收到所述用户针对所述终端设备发送的语音采集指 令时,对所述用户进行语音采集,得到待识别语音; 情感分析模块,用于根据所述环境语音对所述待识别语音进行语音降噪,并对降 噪后的所述待识别语音进行情感分析,得到情感标识; 语音识别模块,用于将所述情感标识和所述待识别语音输入语音识别模型进行语 音分析,得到语音文本。 本发明实施例的另一目的在于提供一种移动终端,包括存储设备以及处理器,所 述存储设备用于存储计算机程序,所述处理器运行所述计算机程序以使所述移动终端执行 上述的语音识别方法。 本发明实施例的另一目的在于提供一种存储介质,其存储有上述的移动终端中所 使用的计算机程序,该计算机程序被处理器执行时实现上述的语音识别方法的步骤。 本发明实施例,通过在接收待识别语音之前进行环境语音的采集,以使能根据采 集到的环境语音对待识别语音进行背景音的降噪,使得针对不同应用场景均能有效的起到 背景音降噪的效果,提高了语音识别的准确性,通过对降噪后的待识别语音进行情感分析 的设计,以使后续语音识别模型能基于情感标识对待识别语音进行分析,进而提高了语音 识别的准确性。 附图说明 图1是本发明第一实施例提供的语音识别方法的流程图; 图2是本发明第二实施例提供的语音识别方法的流程图; 图3是本发明第三实施例提供的语音识别方法的流程图; 图4是本发明第四实施例提供的语音识别方法的流程图; 图5是本发明第五实施例提供的语音识别方法的流程图; 图6是本发明第六实施例提供的语音识别系统的结构示意图; 图7是本发明第七实施例提供的移动终端的结构示意图。











