
技术摘要:
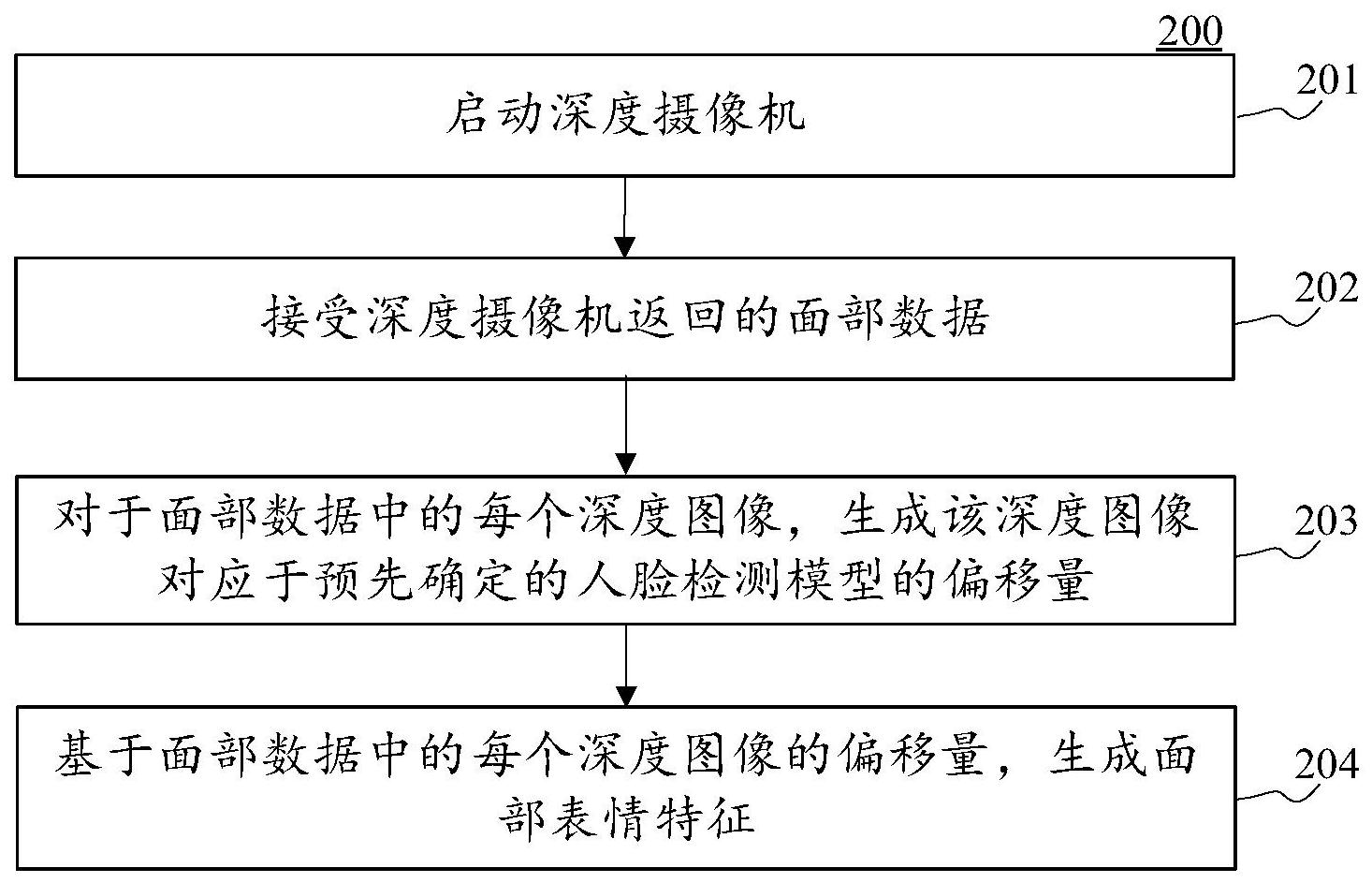
本公开的实施例公开了用于捕捉面部表情特征的方法、终端设备和计算机可读存储介质。该方法的一具体实施方式包括:启动深度摄像机;接受该深度摄像机返回的面部数据;对于面部数据中的每个深度图像,生成该深度图像对应于预先确定的人脸检测模型的偏移量;基于面部数据 全部
背景技术:
包括:启动深度摄像 机;接受该深度摄像机返回的面部数据;对于面 部数据中的每个深度图像,生成该深度图像对应 于预先确定的人脸检测模型的偏移量;基于面部 数据中的每个深度图像的偏移量,生成面部表情 特征。这种方法使用深度摄像机获取面部数据, 能够直接提取所拍摄对象面部的三维特征,同 时,利用预先确定的人脸检测模型确定所拍摄对 象面部数据中每个深度图像的偏移量,方便用户 捕获有效的面部表情特征。 CN 111582121 A CN 111582121 A 权 利 要 求 书 1/2 页 1.一种用于捕捉面部表情特征的方法,包括: 启动深度摄像机; 接受所述深度摄像机返回的面部数据,其中,所述面部数据包括第一数目个深度图像; 对于所述面部数据中的每个深度图像,生成该深度图像对应于预先确定的人脸检测模 型的偏移量; 基于所述面部数据中的每个深度图像的偏移量,生成面部表情特征。 2.根据权利要求1所述的方法,其中,所述深度图像包含了表征所拍摄对象的深度信 息,其中,所述深度信息是指所拍摄对象的三维特征。 3.根据权利要求2所述的方法,其中,所述方法还包括: 基于所述人脸检测模型,生成面部关键区域内的面部关键点集合的初始位置信息集 合,其中,所述面部关键区域包括左眼区域、右眼区域、左眉区域、右眉区域、嘴巴区域、鼻子 区域,以及,所述面部关键点集合的初始位置信息集合包括左眼初始位置信息、右眼初始位 置信息、左眉初始位置信息、右眉初始位置信息、左嘴角的初始位置信息、右嘴角的初始位 置信息、鼻尖的初始位置信息。 4.根据权利要求3所述的方法,其中,所述基于所述人脸检测模型,生成面部关键区域 内的面部关键点集合的初始位置信息集合,包括: 获取标准面部图像,其中,所述标准面部图像是中性人脸图像; 利用所述人脸检测模型,标定所述标准面部图像的初始位置信息集合; 将所述标准面部图像的初始位置信息集合确定为所述面部关键区域内的面部关键点 集合的初始位置信息集合。 5.根据权利要求3所述的方法,其中,所述对于所述面部数据中的每个深度图像,生成 该深度图像对应于预先确定的人脸检测模型的偏移量,包括: 基于所述预先确定的人脸检测模型,获取该深度图像中的面部关键点集合的位置信息 集合; 将所述面部关键点集合的位置信息集合与对应的所述面部关键点集合的初始位置信 息集合进行匹配,得到该深度图像的差值信息; 将所述差值信息确定为所述偏移量。 6.根据权利要求5所述的方法,其中,所述将所述面部关键点集合的位置信息集合与对 应的所述面部关键点集合的初始位置信息集合进行匹配,得到该深度图像的差值信息,包 括: 基于所述面部关键点集合的位置信息集合,利用径向基函数插值,得到插值后的关键 点信息集合M1,其中,径向基函数基于下式生成M1中每个关键点i的插值后的关键点信息 mi,M1是由第一数目个mi组成的关键点信息集合: 其中,mi表示生成的插值后的关键点i的关键点信息,pi表示第i个关键点的位置,i表示 关键点计数,n表示插值后得到的标记点的个数,j表示插值后得到的标记点计数,P是径向 基函数的多项式项,pj表示第j个标记点的位置,P是一个固定的仿射变换,φ表示径向基函 2 CN 111582121 A 权 利 要 求 书 2/2 页 数,λ表示径向基函数的权值矩阵,λj表示插值后得到的第j个标记点对应的径向基函数的 权值矩阵; 基于所述面部关键点集合的初始位置信息集合,利用径向基函数插值,得到插值后的 初始关键点信息集合M2; 将所述关键点信息集合M1和所述初始关键点信息集合M2的差值确定为该深度图像的 差值信息。 7.根据权利要求6所述的方法,其中,所述方法还包括: 保存所述面部数据中的每个深度图像的偏移量,生成所述面部表情特征。 8.一种终端设备,包括: 一个或多个处理器; 存储装置,其上存储有一个或多个程序; 当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实 现如权利要求1-7中任一所述的方法。 9.一种计算机可读存储介质,其上存储有计算机程序,其中,所述程序被处理器执行时 实现如权利要求1-7中任一所述的方法。 3 CN 111582121 A 说 明 书 1/8 页 用于捕捉面部表情特征的方法、终端设备和计算机可读存储 介质 技术领域 本公开实施例涉及运动捕捉和数据表示领域,具体涉及一种面部图像特征捕获和 预处理作用的组合方法、电子设备。
技术实现要素:
随着运动捕捉技术的快速发展,运动捕捉系统在影视、动画制作上被广泛应用。目 前,大多数运动捕捉系统通过跟踪粘帖在表演者面部标识点的方式对面部表情进行捕捉, 这种捕捉方式对表情具有较大的束缚性,标识点极易脱落,降低了表演者对模型表情的精 细化控制。因此,在无任何辅助标识点的条件下,利用运动捕捉技术实现对面部表情的定位 以及捕获面部表情特征,已经成为运动捕捉技术中的热点问题。











