
技术摘要:
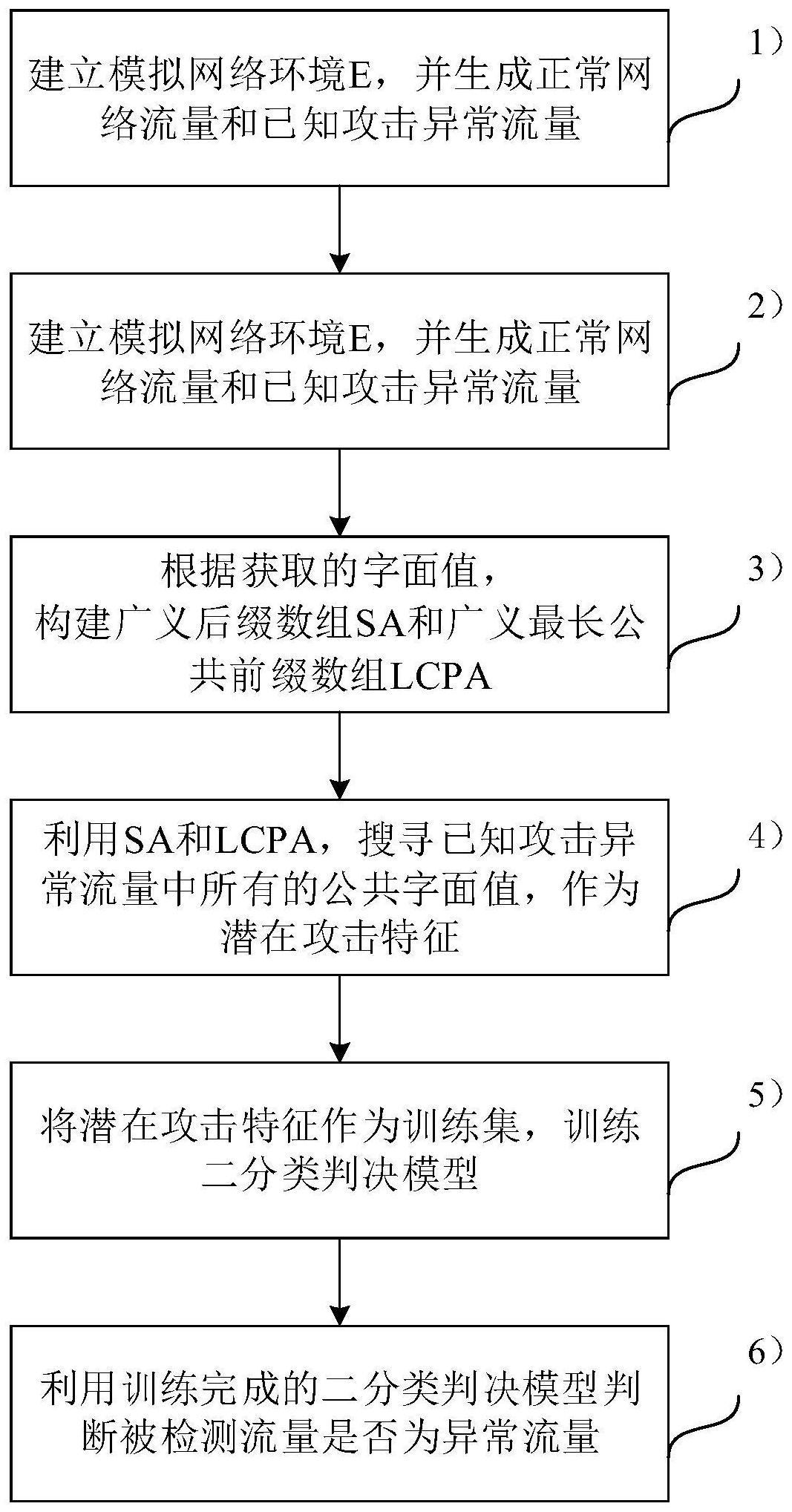
本发明涉及一种采用全文索引的网络攻击入侵检测方法,包括以下步骤:1)建立模拟网络环境E,并生成正常网络流量和已知攻击异常流量;2)分别获取正常网络流量和已知攻击异常流量中各数据包的字面值;3)根据获取的字面值构建广义后缀数组SA和广义最长公共前缀数组LCPA;4) 全部
背景技术:
入侵检测能够提升信息系统对网络攻击的主动防御能力。技术上可分为基于标签 的和基于异常的两类。相比之下,基于标签的入侵检测对已知攻击的检测准确率较高,是构 建当前主流入侵检测系统(Intrusion Detection System,IDS)核心组件的基础。 基于标签的入侵检测技术的基本思路是:判断被检测流量与已知攻击引起的异常 流量是否存在相似或相同特征。一种实现方法是:首先,根据专家经验从已知攻击的异常流 量中提取攻击特征来构建特征库;接着,使用模式匹配算法判断被检测流量是否包含与特 征库相匹配的特征;最后,返回相匹配特征所对应的攻击。另一种实现方法是:首先,使用机 器学习算法学习已知攻击的异常流量特征来构建二分类判定模型;接着,使用二分类判定 模型来判断被检测流量是否为异常流量。 目前,基于标签的入侵检测技术对未知攻击的检测准确率较低,这主要是因为未 知攻击的异常流量包含一些新的攻击特征,这些攻击特征既未被特征库收录,也未被分类 判定模型学习,导致传统模式匹配算法和机器学习算法难以发挥作用。一些研究使用集成 学习和迁移学习来提升二分类判定模型的能力。其中,集成学习首先使用多种机器学习算 法来构建多个独立的二分类判定模型,接着依次使用各个二分类判定模型来判断被检测流 量是否为异常流量,最后综合考虑所有判定模型输出的判断结果来形成最终的判断结果。 迁移学习则是将由二分类判定模型判断为异常的网络流量作为模型的新训练集,从而通过 闭环学习实现模型的迭代更新。从一定意义上来说,集成学习和迁移学习均是从已知攻击 中挖掘出隐藏的攻击特征,这些攻击特征在未知攻击引起的异常流量中呈显性。 但是现有的基于标签的入侵检测技术过于依赖专家经验和统计分析,导致对异常 流量的潜在攻击特征的提取能力不足。因此,如何高效地挖掘异常流量的潜在攻击特征是 一个有待解决的关键问题。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种采用全文索引, 能够有效挖掘异常流量潜在攻击特征的网络攻击入侵检测方法。 本发明的目的可以通过以下技术方案来实现: 一种采用全文索引的网络攻击入侵检测方法,包括以下步骤: 1)建立模拟网络环境E,并生成正常网络流量和已知攻击异常流量; 2)分别获取正常网络流量和已知攻击异常流量中各数据包的字面值; 3)根据获取的字面值构建广义后缀数组SA和广义最长公共前缀数组LCPA; 4)利用广义后缀数组SA和广义最长公共前缀数组LCPA,搜寻已知攻击异常流量中 4 CN 111556014 A 说 明 书 2/6 页 所有的公共字面值,作为潜在攻击特征; 5)将潜在攻击特征作为训练集,训练二分类判决模型; 6)利用训练完成的二分类判决模型判断被检测流量是否为异常流量。 所述的步骤2)具体包括: 201)将正常网络流量的数据包和已知攻击异常流量的数据包结合,构成包含多个 字符串的流量集合S={S0,S1,S2,...,Sn},所述的流量集合S内的元素S0对应正常网络流量 的字面值,所述的流量集合S内的元素S1~Sn对应各已知攻击异常流量的字面值; 202)将流量集合S内的各元素分别切分为多个子串,得到子串集合E,所述的子串 集合E中的各子串对应一个完整数据包的字面值; 203)将子串集合E内的每个子串切分为多个分段,得到分段集合F={F0 ,F1 , F2,...,Fm},所述的分段集合F中的各元素对应一个完整数据包字段的字面值。 所述的步骤3)具体包括: 301)构造分段字符串F’,所述的分段字符串F’中包含分段集合F中所有分段对应 的字面值; 302)将分段字符串F’作为输入,利用后缀数组算法和最长公共前缀数组算法,构 建广义后缀数组SA和广义最长公共前缀数组LCPA。 所述的分段字符串F’的表达式为: F’=F0HF1HF2H...FmH 其中,F0,F1,F2,...,Fm为分段集合F中各分段的字符,H为按字典序小于分段集合F 中任意字符的一个字符。 所述的广义后缀数组SA记录按字典序排列的分段集合F中的所有后缀,该数组中 的元素SA[i]的值为第i 1小的后缀在分段字符串F’中的起始地址; 所述的广义最长公共前缀数组LCPA记录广义后缀数组SA中相邻后缀的最长公共 前缀的长度,该数组中的元素LCPA[i]的值为分段字符串F’中起始地址分别为SA[i]和SA [i-1]的两个后缀的最长公共前缀的长度。 所述的步骤4)具体包括: 401)从左至右访问广义最长公共前缀数组LCPA中未被访问的元素,选取该数组中 满足预设条件的区间LCPA[i,j]; 402)查询分段字符串F’中,起始地址分别为SA[i-1]~SA[j]的后缀所属的分段; 403)判断该分段是否在所有已知攻击异常流量数据包中出现,且不在正常流量数 据包中出现,若是,则该分段为已知攻击异常流量中的公共字面值; 404)判断广义最长公共前缀数组LCPA中是否还有未被访问的元素,若是,则返回 执行步骤401),若否,则完整获取已知攻击异常流量中所有的公共字面值,执行步骤5)。 所述的满足预设条件的区间LCPA[i,j]具体为: 区间LCPA[i,j]中的最小值大于等于设定阈值K,且LCPA[i-1]和LCPA[j 1]均小于 设定阈值K;所述的设定阈值K为整数。 所述的步骤403)具体包括: 403-1)获取步骤402)中查询到分段的分段编号,记录在第一集合M1中; 403-2)查询第一集合M1中各分段所属的子串,并将子串编号记录在第二集合M2中; 5 CN 111556014 A 说 明 书 3/6 页 403-3)查询第二集合M2中各子串所属的字符串,并将字符串编号记录在第三集合 M3中; 403-4)判断第三集合M3是否等于{1,2,...n},若是,则该分段为已知攻击异常流 量中的公共字面值。 所述的步骤1)中,生成已知攻击异常流量的攻击为同类型攻击的不同变种。 所述的模拟网络环境E中的时间切分为等长的时间片。 与现有技术相比,本发明具有以下优点: 1)更高的检出率:本发明通过搜寻在已知同类型攻击的不同变种中均有出现的公 共字面值特征,作为潜在攻击特征提取出来,并将该潜在攻击特征作为训练集训练基于机 器学习的网络攻击入侵检测二分类算法,能够有效挖掘异常流量潜在攻击特征,提高机器 学习算法二分类判定模型对异常流量检出率; 2)更高的执行效率:传统的模式匹配算法和机器学习算法提取特征的过程具有较 高的时空复杂度,本发明方法在执行过程中的性能瓶颈在于广义后缀数组和广义最长公共 前缀数组的构造过程,该构造过程的时空复杂度线性正比于输入的规模且常数因子较小, 有更高的执行效率; 3)更好的数据通用性:传统的模式匹配算法和机器学习算法难以处理高维度数 据,需要在特征提取前对数据进行筛选,得益于理论上较优的时空复杂度,所述方法可处理 高维数据,可结合时间序列分析技术,更快更全地找出横跨多个数据包、多个会话的潜在攻 击特征。 附图说明 图1为本发明方法的流程示意图; 图2为本发明方法的具体实现流程图;











