
技术摘要:
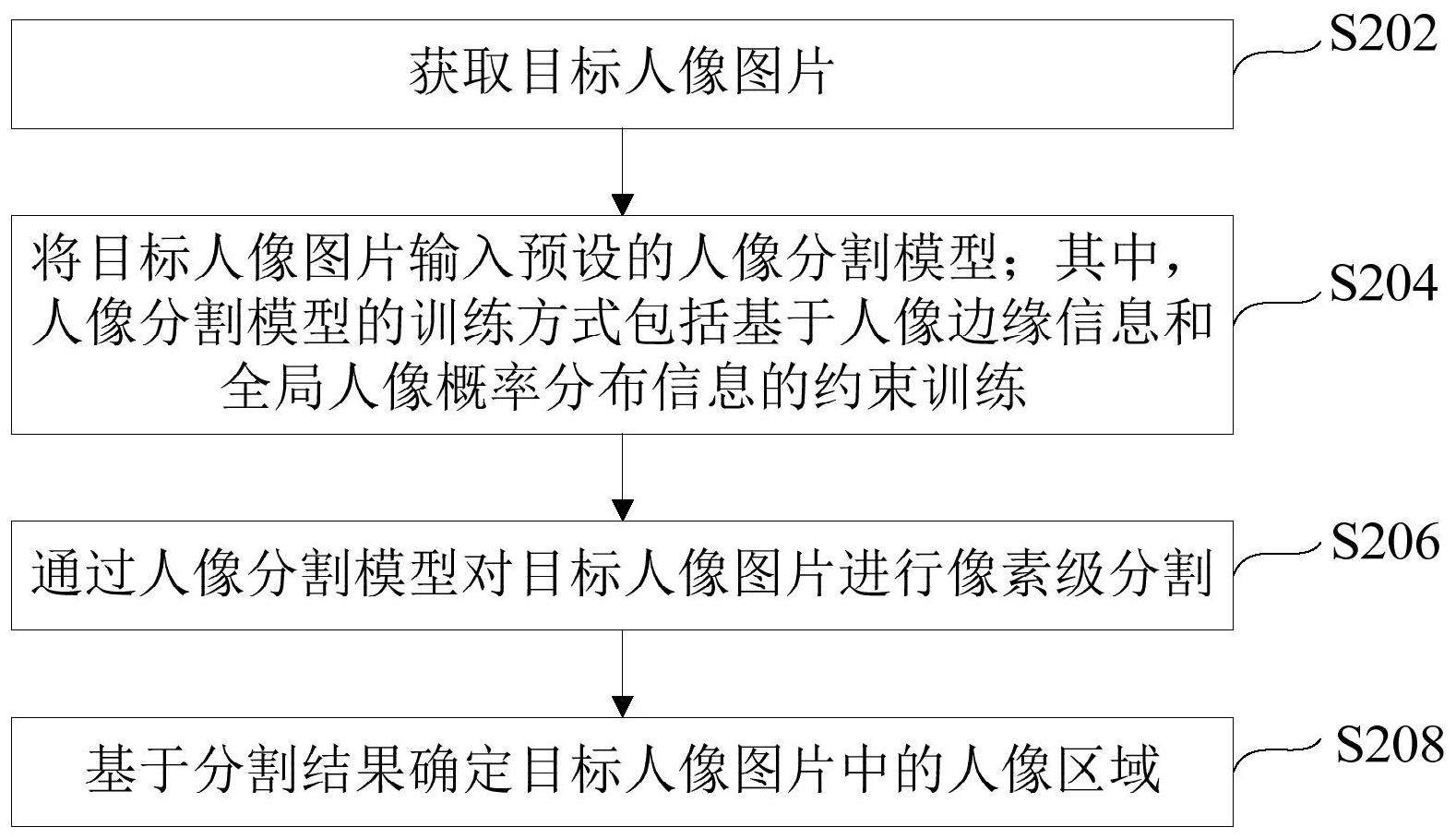
本申请提供了一种人像分割方法、装置及电子设备,该方法包括:获取目标人像图片;将目标人像图片输入预设的人像分割模型;其中,人像分割模型的训练方式包括基于人像边缘信息和全局人像概率分布信息的约束训练;通过人像分割模型对目标人像图片进行像素级分割;基于分 全部
背景技术:
在很多对人像图片有要求的应用场景中,对人像分割的精度要求越来越高。现有 的语义分割技术,都是粗糙地寻找对象在图像中大致像素,侧重点在于找到不同的对象实 例,实现语义层面理解图像的内容信息,无法满足人像整体和边缘精细分割的要求。人视觉 上对头发、耳朵、脸等部位比较敏感,分割不全或边缘不精细时会造成比较负面的观感体 验。
技术实现要素:
有鉴于此,本申请实施例提供一种人像分割方法、装置及电子设备,解决现有技术 中人像分割精度不够的技术问题,提高用户的观感体验。 根据本申请的一个方面,提供一种人像分割方法,所述方法包括:获取目标人像图 片;将所述目标人像图片输入预设的人像分割模型;其中,所述人像分割模型的训练方式包 括基于人像边缘信息和全局人像概率分布信息的约束训练;通过所述人像分割模型对所述 目标人像图片进行像素级分割;基于分割结果确定所述目标人像图片中的人像区域。 在一些实施例中,所述人像分割模型的训练过程,包括:获取人像图片样本集;其 中,所述样本集中的每个人像样本图片均标注有像素标识;所述像素标识用于表征每个像 素对应的人像区域标识或背景区域标识;根据每个人像样本图片标注的所述像素标识,确 定每个人像样本图片对应的人像边缘信息及多个所述人像样本图片对应的全局人像概率 分布信息;所述全局人像概率分布信息包括每个像素属于人像区域的概率值;应用所述人 像图片样本集,并以所述全局人像概率分布信息和每个所述人像样本图片的人像边缘信息 为约束条件,训练预设的深度学习语义分割初始模型,得到人像分割模型。 在一些实施例中,根据每个人像图片标注的所述像素标识,确定每个人像图片对 应的人像边缘信息的步骤,包括:逐一将每个所述人像样本图片作为所述当前人像样本图 片;基于当前人像样本图片的像素标识和边缘检测算子计算当前人像样本图片对应的人像 边缘;将所述当前人像样本图片对应的人像边缘向内扩展预设个数的像素,得到所述当前 人像样本图片的人像边缘区域;将所述人像边缘区域及所述人像边缘区域中每个像素对应 的预设权重,作为所述当前人像样本图片对应的人像边缘信息。 在一些实施例中,根据每个人像样本图片标注的所述像素标识,确定多个所述人 像样本图片对应的全局人像概率分布信息的步骤,包括:统计多个人像样本图片中每个相 同像素位置对应的人像区域标识的数量;将每个相同像素位置对应的人像区域标识的数量 除以所述人像图片的数量,得到每个像素位置对应的概率值;基于每个所述像素位置对应 的概率值,得到多个所述人像图片对应的全局人像概率分布信息。 在一些实施例中,应用所述人像图片样本集,并以所述全局人像概率分布信息和 8 CN 111582278 A 说 明 书 2/15 页 每个所述人像样本图片的人像边缘信息为约束条件,训练预设的深度学习语义分割初始模 型的步骤,包括:从所述人像图片样本集中选取人像样本图片组;将所述人像样本图片组输 入所述深度学习语义分割初始模型进行预测,得到所述人像样本图片组中每个人像样本图 片的预测结果;所述预测结果包括每个像素对应的像素预测标识;所述像素预测标识包括 人像区域标识或背景区域标识;对于每个所述人像样本图片,判断所述人像样本图片的预 测结果中是否存在有与所述人像样本图片的像素标识不相同的像素预测标识;如果存在, 将所述像素预测标识对应的像素作为差异像素;基于差异像素、所述人像样本图片的人像 边缘信息及所述全局人像概率分布信息调整所述深度学习语义分割模型的损失函数;基于 调整后的损失函数计算所述人像样本图片对应的损失值;基于所述人像样本图片组中每个 所述人像图片对应的损失值判断所述损失函数是否收敛;如果否,基于每个所述人像图片 对应的损失值调整所述深度学习语义分割模型的参数继续训练;如果是,停止训练。 在一些实施例中,基于差异像素、所述人像样本图片的人像边缘信息及所述全局 人像概率分布信息调整所述深度学习语义分割模型的损失函数的步骤,包括:从所述全局 人像概率分布信息中查找所述差异像素对应的概率值,将所述差异像素对应的概率值作为 全局人像概率分布信息的权重;判断所述差异像素是否在所述人像样本图片对应的人像边 缘信息的人像边缘区域内;如果是,从所述人像边缘信息中查找到所述差异像素在人像边 缘区域内对应的权重;基于所述全局人像概率分布信息的权重、所述差异像素在人像边缘 区域内对应的权重,对所述损失函数进行调整;如果否,则基于所述全局人像概率分布信息 的权重对所述损失函数进行调整。 在一些实施例中,所述损失函数为交叉熵损失函数;基于所述全局人像概率分布 信息的权重、所述差异像素在人像边缘区域内对应的权重,对所述损失函数进行调整的步 骤,包括:通过以下算式对所述损失函数进行调整: CEL’=CEL*(1 W1 W2); 其中,CEL’表示调整后的损失函数;CEL表示交叉熵损失函数;W1表示全局人像概 率分布信息的权重;W2表示差异像素在人像边缘区域内对应的权重; 基于所述全局人像概率分布信息的权重对所述损失函数进行调整的步骤,包括: 通过以下算式对所述损失函数进行调整: CEL’=CEL*(1 W1); 其中,CEL’表示调整后的损失函数;CEL表示交叉熵损失函数;W1表示全局人像概 率分布信息的权重。 在一些实施例中,基于分割结果确定所述目标人像图片中的人像区域的步骤,包 括:对分割后的所述目标人像图片进行单连通域检测;如果检测结果包括一个单连通域,则 将所述单连通域作为所述目标人像图片的人像区域;如果检测结果包括多个单连通域,则 将多个单连通域中面积最大的区域作为所述目标人像图片的人像区域。 在一些实施例中,基于分割结果确定所述目标人像图片的人像区域的步骤之后, 还包括:将所述人像区域之外的区域确定为所述目标人像图片的背景区域;将所述背景区 域中的像素值转换为预设的像素值。 在一些实施例中,所述人像分割模型的训练方式还包括以预设属性为约束的训 练;所述预设属性包括以下:人像方向、人像性别和头发长度属性;所述人像分割模型的训 9 CN 111582278 A 说 明 书 3/15 页 练过程还包括: 获取所述人像图片样本集中每个所述人像样本图片的标签信息;所述标签信息包 括以下:人像方向、人像性别和头发长度属性; 将包含所述标签信息的人像样本图片输入所述深度学习语义分割模型中进行多 任务训练。 在一些实施例中,获取所述人像图片样本集中每个所述人像样本图片的标签信息 的步骤,包括:逐一将每个所述人像样本图片作为所述当前人像样本图片;将所述当前人像 样本图片中的人像调整为正向人像;对所述当前人像样本图片中的正向人像进行多个预设 角度的旋转,得到每个所述预设角度对应的人像样本图片和包含有人像方向的标签信息。 在一些实施例中,基于分割结果确定所述目标人像图片的人像区域的步骤之后, 还包括:从分割结果中提取所述目标人像图片对应的标签信息;根据提取到的所述标签信 息中的人像方向判断所述人像区域是否为正向;如果否,将所述人像区域调整为正向。 在一些实施例中,所述方法还包括:判断所述人像区域是否在所述目标人像图片 的中心区域;如果否,对所述人像区域进行居中处理。 在一些实施例中,对所述人像区域进行居中处理的步骤,包括:确定所述人像区域 的人脸中心位置;以所述人脸中心位置为所述目标人像图片的中心位置,扩展和/或裁剪所 述目标人像图片,以使所述人像区域在所述目标人像图片的中心区域。 根据本申请的另一方面,提供一种人像分割装置,包括:图片获取模块,用于获取 目标人像图片;模型预测分割模块,用于将所述目标人像图片输入预设的人像分割模型;其 中,所述人像分割模型的训练方式包括基于人像边缘信息和全局人像概率分布信息的约束 训练;通过所述人像分割模型对所述目标人像图片进行像素级分割;人像区域确定模块,用 于基于分割结果确定所述目标人像图片中的人像区域。 在一些实施例中,所述装置还包括:模型训练模块;所述模型训练模块具体包括: 样本获取模块,用于获取人像图片样本集;其中,所述样本集中的每个人像样本图片均标注 有像素标识;所述像素标识用于表征每个像素对应的人像区域标识或背景区域标识; 信息确定模块,用于根据每个人像样本图片标注的所述像素标识,确定每个人像 样本图片对应的人像边缘信息及多个所述人像样本图片对应的全局人像概率分布信息;所 述全局人像概率分布信息包括每个像素属于人像区域的概率值;约束训练模块,用于应用 所述人像图片样本集,并以所述全局人像概率分布信息和每个所述人像样本图片的人像边 缘信息为约束条件,训练预设的深度学习语义分割初始模型,得到人像分割模型。 在一些实施例中,所述信息确定模块,还用于:逐一将每个所述人像样本图片作为 所述当前人像样本图片;基于当前人像样本图片的像素标识和边缘检测算子计算当前人像 样本图片对应的人像边缘;将所述当前人像样本图片对应的人像边缘向内扩展预设个数的 像素,得到所述当前人像样本图片的人像边缘区域;将所述人像边缘区域及所述人像边缘 区域中每个像素对应的预设权重,作为所述当前人像样本图片对应的人像边缘信息。 在一些实施例中,所述信息确定模块,还用于:统计多个人像样本图片中每个相同 像素位置对应的人像区域标识的数量;将每个相同像素位置对应的人像区域标识的数量除 以所述人像图片的数量,得到每个像素位置对应的概率值;基于每个所述像素位置对应的 概率值,得到多个所述人像图片对应的全局人像概率分布信息。 10 CN 111582278 A 说 明 书 4/15 页 在一些实施例中,所述约束训练模块,还用于:从所述人像图片样本集中选取人像 样本图片组;将所述人像样本图片组输入所述深度学习语义分割初始模型进行预测,得到 所述人像样本图片组中每个人像样本图片的预测结果;所述预测结果包括每个像素对应的 像素预测标识;所述像素预测标识包括人像区域标识或背景区域标识;对于每个所述人像 样本图片,判断所述人像样本图片的预测结果中是否存在有与所述人像样本图片的像素标 识不相同的像素预测标识;如果存在,将所述像素预测标识对应的像素作为差异像素;基于 差异像素、所述人像样本图片的人像边缘信息及所述全局人像概率分布信息调整所述深度 学习语义分割模型的损失函数;基于调整后的损失函数计算所述人像样本图片对应的损失 值;基于所述人像样本图片组中每个所述人像图片对应的损失值判断所述损失函数是否收 敛;如果否,基于每个所述人像图片对应的损失值调整所述深度学习语义分割模型的参数 继续训练;如果是,停止训练。 在一些实施例中,所述约束训练模块,还用于:从所述全局人像概率分布信息中查 找所述差异像素对应的概率值,将所述差异像素对应的概率值作为全局人像概率分布信息 的权重;判断所述差异像素是否在所述人像样本图片对应的人像边缘信息的人像边缘区域 内;如果是,从所述人像边缘信息中查找到所述差异像素在人像边缘区域内对应的权重;基 于所述全局人像概率分布信息的权重、所述差异像素在人像边缘区域内对应的权重,对所 述损失函数进行调整;如果否,则基于所述全局人像概率分布信息的权重对所述损失函数 进行调整。 在一些实施例中,所述损失函数为交叉熵损失函数;所述约束训练模块,还用于: 通过以下算式对所述损失函数进行调整: CEL’=CEL*(1 W1 W2); 其中,CEL’表示调整后的损失函数;CEL表示交叉熵损失函数;W1表示全局人像概 率分布信息的权重;W2表示差异像素在人像边缘区域内对应的权重; 基于所述全局人像概率分布信息的权重对所述损失函数进行调整的步骤,包括: 通过以下算式对所述损失函数进行调整: CEL’=CEL*(1 W1); 其中,CEL’表示调整后的损失函数;CEL表示交叉熵损失函数;W1表示全局人像概 率分布信息的权重。 在一些实施例中,所述人像区域确定模块包括:单连通域检测模块,用于对分割后 的所述目标人像图片进行单连通域检测;如果检测结果包括一个单连通域,则将所述单连 通域作为所述目标人像图片的人像区域;如果检测结果包括多个单连通域,则将多个单连 通域中面积最大的区域作为所述目标人像图片的人像区域。 在一些实施例中,所述装置还包括:背景区域调整模块,用于将所述人像区域之外 的区域确定为所述目标人像图片的背景区域;将所述背景区域中的像素值转换为预设的像 素值。 在一些实施例中,所述人像分割模型的训练方式还包括以预设属性为约束的训 练;所述预设属性至少包括以下之一:人像方向、人像性别和头发长度属性;所述模型训练 模块还包括:标签信息获取模块,用于获取所述人像图片样本集中每个所述人像样本图片 的标签信息;所述标签信息至少包括以下之一:人像方向、人像性别和头发长度属性;多任 11 CN 111582278 A 说 明 书 5/15 页 务训练模块,用于将包含所述标签信息的人像样本图片输入所述深度学习语义分割模型中 进行多任务训练。 在一些实施例中,所述标签信息获取模块,还用于:逐一将每个所述人像样本图片 作为所述当前人像样本图片;将所述当前人像样本图片中的人像调整为正向人像;对所述 当前人像样本图片中的正向人像进行多个预设角度的旋转,得到每个所述预设角度对应的 人像样本图片和包含有人像方向的标签信息。 在一些实施例中,所述装置还包括:人像区域调整模块,用于从分割结果中提取所 述目标人像图片对应的标签信息;根据提取到的所述标签信息中的人像方向判断所述人像 区域是否为正向;如果否,将所述人像区域调整为正向。 在一些实施例中,所述装置还包括:居中处理模块,用于判断所述人像区域是否在 所述目标人像图片的中心区域;如果否,对所述人像区域进行居中处理。 在一些实施例中,所述居中处理模块,还用于:确定所述人像区域的人脸中心位 置;以所述人脸中心位置为所述目标人像图片的中心位置,扩展和/或裁剪所述目标人像图 片,以使所述人像区域在所述目标人像图片的中心区域。 根据本申请的另一个方面,提供一种电子设备,包括:处理器、存储介质和总线,所 述存储介质存储有所述处理器可执行的机器可读指令,当电子设备运行时,所述处理器与 所述存储介质之间通过总线通信,所述处理器执行所述机器可读指令,以执行时执行如上 述人像分割方法中的一个或多个方法的步骤。 根据本申请的另一个方面,提供一种计算机可读存储介质,该计算机可读存储介 质上存储有计算机程序,该计算机程序被处理器运行时执行如上述人像分割方法中的一个 或多个方法的步骤。 上述任一方面所述的人像分割方法和装置中,首先获取目标人像图片;然后将该 目标人像图片输入预设的人像分割模型中,通过该人像分割模型对目标人像图片进行像素 级分割;最后基于分割结果确定该目标人像图片中的人像区域。由于上述人像分割模型的 训练方式为基于人像边缘信息和全局人像概率分布信息的约束训练,可以提高人像分割模 型在像素级分割的精准度,即通过基于人像边缘信息和全局人像概率分布信息的约束训练 得到的人像分割模型,对目标人像图片进行像素级分割,可以将目标人像图片中的人像和 背景进行精确的分割,提高图片的分割准确性。 为使本申请实施例的上述目的、特征和优点能更明显易懂,下面将结合实施例,并 配合所附附图,作详细说明。 附图说明 为了更清楚地说明本申请实施例的技术方案,下面将对实施例中所需要使用的附 图作简单地介绍,应当理解,以下附图仅示出了本申请的某些实施例,因此不应被看作是对 范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这 些附图获得其他相关的附图。 图1示出了本申请实施例所提供的一种人像分割系统的框图; 图2示出了本申请实施例所提供的一种人像分割方法的流程图; 图3示出了本申请实施例所提供的一种人像分割方法中模型训练过程示意图; 12 CN 111582278 A 说 明 书 6/15 页 图4示出了本申请实施例所提供的一种人像样本图片和像素标识示意图; 图5示出了本申请实施例所提供的一种全局人像概率分布信息示意图; 图6示出了本申请实施例所提供的一种人像样本图片分割前后及单连通域检测示 意图; 图7示出了本申请实施例所提供的一种模型训练示意图; 图8示出了本申请实施例所提供的一种人像分割装置的结构示意图; 图9示出了本申请实施例所提供的另一种人像分割装置的结构示意图; 图10示出了本申请实施例所提供的一种电子设备的示意图。











