
技术摘要:
本申请涉及大数据处理技术领域,公开了一种数据管理方法、装置、设备及存储介质,通过根据待存储数据对应的所有用户终端的用户行为标识信息确定待存储数据的拆分单元,并根据所述拆分单元将待存储数据进行拆分之后,根据预设的分库分表算法确定至少两个所述数据单元对 全部
背景技术:
随着互联网和信息技术的发展,服务器中的数据在不同时间段存在波动较大的现 象,这就要求对应的数据库具有较高的可扩展能力和伸缩性。目前,通常通过分库分表存储 的方式来提高数据库的存储能力,但是常见的分库分表方法,以用户为维度进行,由于不同 的用户产生的数据量差异可能很悬殊,导致以用户为维度进行分库分表无法达到数据的均 衡分布,使得分表存储之后的分表数据量还是很大,达不到分库分表的效果。
技术实现要素:
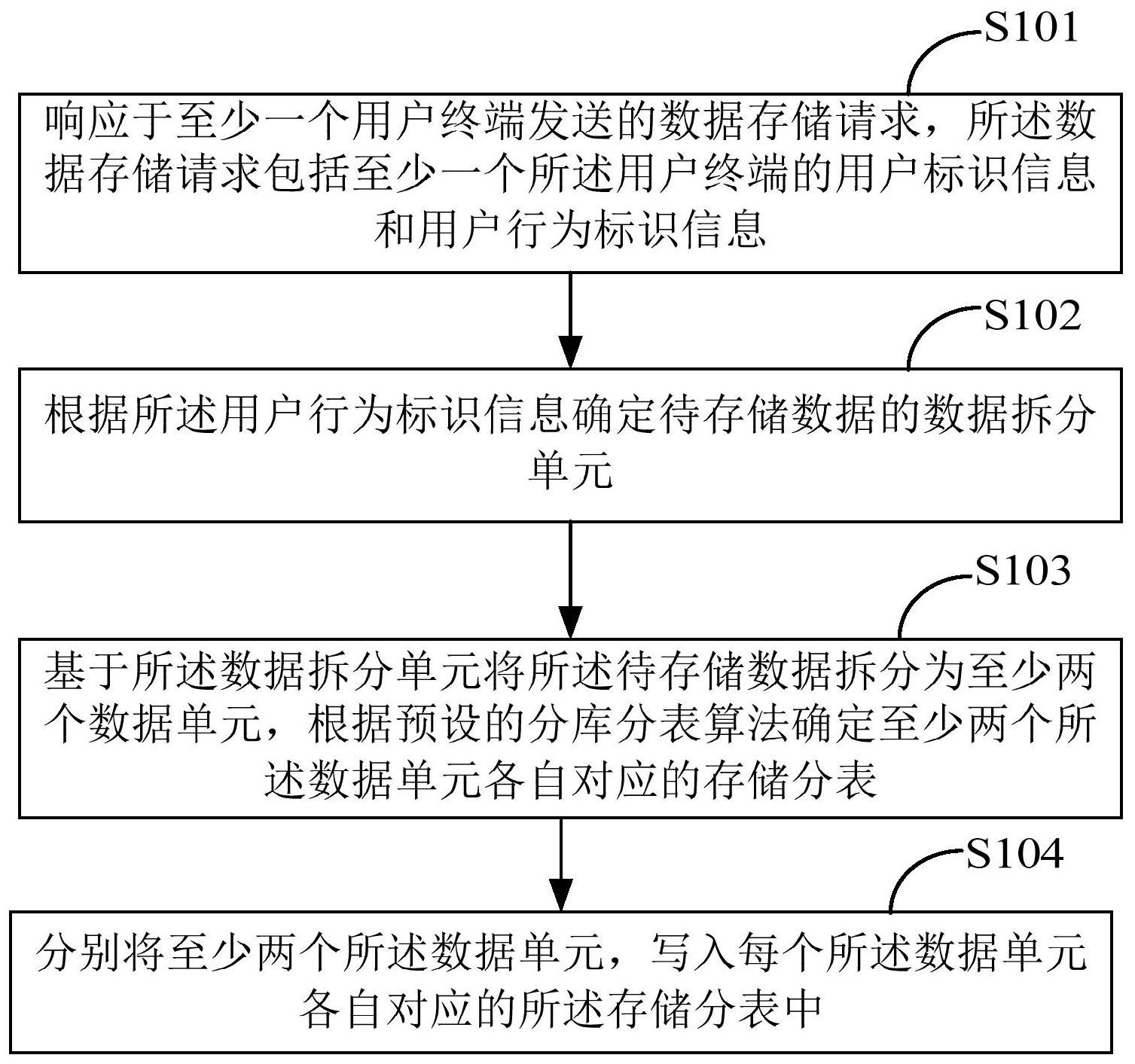
本申请提供了一种数据管理方法、装置、设备及存储介质,通过根据用户行为标识 信息确定待存储数据的数据拆分单元,并根据所述拆分单元将待存储数据进行拆分之后, 根据预设的分库分表算法将数据单元进行分表存储,可以解决数据存储不均衡的问题,提 高数据库的存储能力。 第一方面,本申请提供了一种数据管理方法,包括: 响应于至少一个用户终端发送的数据存储请求,所述数据存储请求包括至少一个 所述用户终端的用户标识信息和用户行为标识信息; 根据所述用户行为标识信息确定待存储数据的数据拆分单元; 基于所述数据拆分单元将所述待存储数据拆分为至少两个数据单元,根据预设的 分库分表算法确定至少两个所述数据单元各自对应的存储分表; 分别将至少两个所述数据单元,写入每个所述数据单元各自对应的所述存储分表 中。 在一可选的实现方式中,所述待存储数据存储于区块链中,所述根据所述用户行 为标识信息确定待存储数据的数据拆分单元,包括: 确定所有所述用户终端对应的用户行为标识信息的数量; 根据所述用户行为标识信息的数量确定待存储数据的数据拆分单元。 在一可选的实现方式中,所述根据预设的分库分表算法确定至少两个所述数据单 元各自对应的存储分表,包括: 针对任一所述数据单元,计算该数据单元包含的用户行为标识信息的哈希值; 从所述哈希值中获取预设数量的数值; 以所述预设数量的数值为分片键值,确定该数据单元对应的存储分表。 在一可选的实现方式中,以所述预设数量的数值为分片键值,确定该数据单元对 应的存储分表,包括: 计算各个所述分片键值对应的存储分库的编号和各个所述分片键值对应的存储 4 CN 111611249 A 说 明 书 2/10 页 分表的编号; 根据各个所述分片键值对应的存储分库的编号和所述存储分表的编号,确定该数 据单元对应的存储分表。 在一可选的实现方式中,计算各个所述分片键值对应的存储分库的编号和各个所 述分片键值对应的存储分表的编号,包括: 分别对各个所述分片键值相对于目标商值取模,得到各个所述分片键值对应的存 储分库的编号,所述目标商值为预设的存储分表总数与预设的存储分库总数的商值; 分别对各个所述分片键值相对于所述预设的存储分表总数取模得到模值; 分别将各个所述分片键值对应的所述模值相对于所述预设的存储分库总数取模, 得到各个所述分片键值对应的存储分表的编号。 在一可选的实现方式中,在分别将至少两个所述数据单元,写入每个所述数据单 元各自对应的所述存储分表进行存储之后,还包括: 基于数据库多源同步技术将不同存储分表中存储的数据实时同步至分布式集成 数据库中; 当接收到针对目标用户终端的用户行为数据查询指令后,基于聚合数据表查询方 法在所述分布式集成数据库中查询所述目标用户终端的用户行为数据。 在一可选的实现方式中,所述基于聚合数据表查询方法在所述分布式集成数据库 中查询所述目标用户的行为数据,包括: 将所述分布式集成数据库中的所有用户终端的用户行为数据标记为主数据源,将 所述目标用户终端的用户数据标记为从数据源; 对所述从数据源做分表配置信息,基于所述分表配置信息读取所述从数据源中的 用户行为数据。 第二方面,本申请提供了一种数据管理装置,包括: 响应模块,用于响应于至少一个用户终端发送的数据存储请求,所述数据存储请 求包括至少一个所述用户终端的用户标识信息和用户行为标识信息; 确定模块,用于根据所述用户行为标识信息确定待存储数据的数据拆分单元; 拆分模块,用于基于所述数据拆分单元将所述待存储数据拆分为至少两个数据单 元,根据预设的分库分表算法确定至少两个所述数据单元各自对应的存储分表; 写入模块,用于分别将至少两个所述数据单元,写入每个所述数据单元各自对应 的所述存储分表中。 在一可选的实现方式中,所述待存储数据存储于区块链中,所述拆分模块,包括: 确定单元,用于确定所有所述用户终端对应的用户行为标识信息的数量; 拆分单元,用于根据所述用户行为标识信息的数量确定待存储数据的数据拆分单 元。 在一可选的实现方式中,所述根据预设的分库分表算法确定至少两个所述数据单 元各自对应的存储分表,包括: 针对任一所述数据单元,计算该数据单元包含的用户行为标识信息的哈希值; 从所述哈希值中获取预设数量的数值; 以所述预设数量的数值为分片键值,确定该数据单元对应的存储分表。 5 CN 111611249 A 说 明 书 3/10 页 在一可选的实现方式中,以所述预设数量的数值为分片键值,确定该数据单元对 应的存储分表,包括: 计算各个所述分片键值对应的存储分库的编号和各个所述分片键值对应的存储 分表的编号; 根据各个所述分片键值对应的存储分库的编号和所述存储分表的编号,确定该数 据单元对应的存储分表。 在一可选的实现方式中,计算各个所述分片键值对应的存储分库的编号和各个所 述分片键值对应的存储分表的编号,包括: 分别对各个所述分片键值相对于目标商值取模,得到各个所述分片键值对应的存 储分库的编号,所述目标商值为预设的存储分表总数与预设的存储分库总数的商值; 分别对各个所述分片键值相对于所述预设的存储分表总数取模得到模值; 分别将各个所述分片键值对应的所述模值相对于所述预设的存储分库总数取模, 得到各个所述分片键值对应的存储分表的编号。 在一可选的实现方式中,还包括: 同步模块,用于基于数据库多源同步技术将不同存储分表中存储的数据实时同步 至分布式集成数据库中; 查询模块,用于在当接收到针对目标用户终端的用户行为数据查询指令后,基于 聚合数据表查询方法在所述分布式集成数据库中查询所述目标用户终端的用户行为数据。 在一可选的实现方式中,所述同步模块,包括: 标记单元,用于将所述分布式集成数据库中的所有用户终端的用户行为数据标记 为主数据源,将所述目标用户终端的用户行为数据标记为从数据源; 读取单元,用于对所述从数据源做分表配置信息,基于所述分表配置信息读取所 述从数据源中的用户行为数据。 第三方面,本申请提供了一种数据管理设备,其特征在于,包括:存储器、处理器以 及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算 机程序时实现如上第一方面或第一方面任一可选实施例所述的方法。 第四方面,本申请提供了一种计算机可读存储介质,上述计算机可读存储介质存 储有计算机程序,上述计算机程序被处理器执行时实现如上述第一方面或第一方面任一可 选实施例所述的方法。 第五方面,本申请提供了一种计算机程序产品,上述计算机程序产品包括计算机 程序,上述计算机程序被一个或多个处理器执行时实现如上述第一方面或第一方面任一可 选实施例的方法。 本申请第一方面提供的数据管理方法,通过根据待存储数据对应的所有用户终端 的用户行为标识信息确定待存储数据的拆分单元,并根据所述拆分单元将待存储数据进行 拆分之后,根据预设的分库分表算法确定至少两个所述数据单元对应的存储分表;分别将 至少两个所述数据单元,写入每个所述数据单元各自对应的所述存储分表进行存储。通过 上述区别技术特征本申请实现了数据的均衡存储,提高了数据库的存储能力。 可以理解的是,上述第二方面至第五方面的有益效果可以参见上述第一方面中的 相关描述,在此不再赘述。 6 CN 111611249 A 说 明 书 4/10 页 附图说明 为了更清楚地说明本申请实施例中的技术方案,下面将对实施例或现有技术描述 中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些 实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附 图获得其他的附图。 图1是本申请第一实施例提供的数据管理方法的示意流程图; 图2是图1中S102的具体实现流程图; 图3是本申请第二实施例提供的数据管理方法的示意流程图; 图4是图3中S306的具体实现流程图; 图5是本申请第三实施例提供的数据管理装置的示意图; 图6是本申请第四实施例提供的数据管理装置的结构示意图。











