
技术摘要:
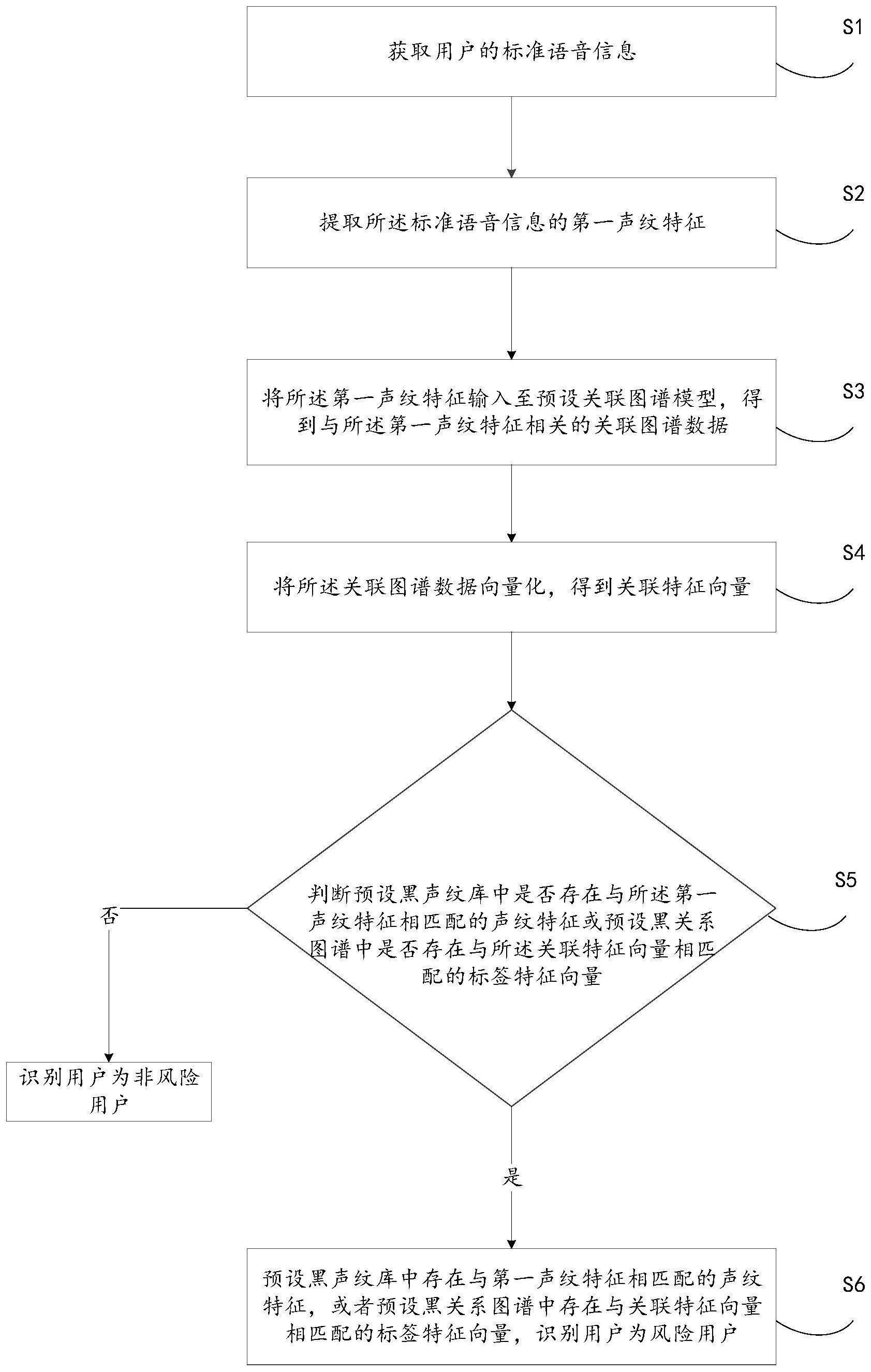
本发明涉及一种人工智能技术,揭露了一种基于声纹特征与关联图谱数据的风险用户识别方法,包括:获取用户的标准语音信息;提取标准语音信息的第一声纹特征;将第一声纹特征输入至预设关联图谱模型,得到与第一声纹特征相关的关联图谱数据;将关联图谱数据向量化,得到 全部
背景技术:
目前信息数据呈现指数型的增加,伴随着信息数据的增加,对用户信息进行安全 性验证从而识别潜在的风险用户具有一定必要性。现有技术中,主要基于单项验证方法对 用户信息进行验证进而识别风险用户,这种方式存在安全漏洞,容易漏检,用户信息容易被 盗用信息者盗用。
技术实现要素:
本发明提供一种基于声纹特征与关联图谱数据的风险用户识别方法、装置、电子 设备及计算机可读存储介质,其主要目的在于降低识别风险用户的漏检率,有利于增强信 息的安全性。 为实现上述目的,本发明提供的一种基于声纹特征与关联图谱数据的风险用户识 别方法,包括: 获取用户的标准语音信息; 提取所述标准语音信息的第一声纹特征; 将所述第一声纹特征输入至预设关联图谱模型,得到与所述第一声纹特征相关的 关联图谱数据; 将所述关联图谱数据向量化,得到关联特征向量; 判断预设黑声纹库中是否存在与所述第一声纹特征相匹配的声纹特征;以及 判断预设黑关系图谱中是否存在与所述关联特征向量相匹配的标签特征向量; 若所述预设黑声纹库中存在与所述第一声纹特征相匹配的声纹特征,或者所述预 设黑关系图谱中存在与所述关联特征向量相匹配的标签特征向量,确定所述用户为风险用 户。 可选地,所述获取用户的标准语音信息包括: 获取所述用户的原始语音信息; 利用模/数转换器对所述原始语音信息进行采样,得到数字语音信号; 对所述数字语音信号进行预加重操作,得到数字滤波语音信号; 对所述数字滤波语音信号进行分帧加窗操作,得到所述标准语音信息。 可选地,所述对所述数字滤波语音信号进行分帧加窗操作包括: 通过目标函数对所述数字滤波语音信号进行分帧加窗操作,所述目标函数为: 4 CN 111552832 A 说 明 书 2/14 页 其中,n为所述数字滤波语音信号的帧数序列,N为所述数字滤波语音信号的总帧 数,w(n)为所述标准语音信息的单帧数据。 可选地,所述提取所述标准语音信息的第一声纹特征,包括: 将所述标准语音信息进行离散傅里叶变换,得到所述标准语音信息的频谱信息; 利用三角滤波器对所述标准语音信息进行三角滤波计算,得到所述标准语音信息 的频率响应值; 对所述频谱信息和所述频率响应值进行对数计算,得到对数能量; 对所述对数能量进行离散余弦计算,得到所述第一声纹特征。 可选地,所述离散傅里叶变换包含的计算函数为: 其中,N为所述数字滤波语音信号的总帧数,n为所述数字滤波语音信号的帧数序 列,w(n)为所述标准语音信息的单帧数据,j为所述傅里叶变换的权值,k为所述数字滤波语 音信号中单帧的声音频率,D为所述频谱信息。 可选地,所述判断预设黑声纹库中是否存在与所述第一声纹特征相匹配的声纹特 征包括: 通过相似度函数分别计算所述第一声纹特征与预设黑声纹库中多个声纹特征的 第一相似度; 若存在大于第一相似度阈值的第一相似度,确定所述预设黑声纹库中存在与所述 第一声纹特征相匹配的声纹特征。 可选地,所述相似度函数为: 其中,x表示所述第一声纹特征,yi表示所述预设黑声纹库中声纹特征,n表示所述 预设黑声纹库中声纹特征的数量,sim(x,yi)表示所述第一相似度。 为了解决上述问题,本发明还提供一种基于声纹特征与关联图谱数据的风险用户 识别装置,所述装置包括: 语音信息获取模块,用于获取用户的标准语音信息; 声纹特征提取模块,用于提取所述标准语音信息的第一声纹特征; 图谱数据获取模块,用于将所述第一声纹特征输入至预设关联图谱模型,得到与 所述第一声纹特征相关的关联图谱数据; 向量转换模块,用于将所述关联图谱数据向量化,得到关联特征向量; 判断模块,用于判断预设黑声纹库中是否存在与所述第一声纹特征相匹配的声纹 特征; 所述判断模块,还用于判断预设黑关系图谱中是否存在与所述关联特征向量相匹 配的标签特征向量; 确定模块,用于若所述预设黑声纹库中存在与所述第一声纹特征相匹配的声纹特 5 CN 111552832 A 说 明 书 3/14 页 征,或者所述预设黑关系图谱中存在与所述关联特征向量相匹配的标签特征向量,确定所 述用户为风险用户。 为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括: 存储器,存储至少一个指令;及 处理器,执行所述存储器中存储的指令以实现上述中任意一项所述的基于声纹特 征与关联图谱数据的风险用户识别方法。 为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存 储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现上述 中任意一项所述的基于声纹特征与关联图谱数据的风险用户识别方法。 本发明实施例中,获取用户的标准语音信息;提取所述标准语音信息的第一声纹 特征;将所述第一声纹特征输入至预设关联图谱模型,得到与所述第一声纹特征相关的关 联图谱数据;将所述关联图谱数据向量化,得到关联特征向量;判断预设黑声纹库中是否存 在与所述第一声纹特征相匹配的声纹特征;以及判断预设黑关系图谱中是否存在与所述关 联特征向量相匹配的标签特征向量;若所述预设黑声纹库中存在与所述第一声纹特征相匹 配的声纹特征,或者所述预设黑关系图谱中存在与所述关联特征向量相匹配的标签特征向 量,确定所述用户为风险用户。通过两种渠道的双项验证,实现了降低识别风险用户的漏检 率,进而增强信息的安全性的目的。 附图说明 图1为本发明一实施例提供的基于声纹特征与关联图谱数据的风险用户识别方法 的流程示意图; 图2为本发明一实施例提供的基于声纹特征与关联图谱数据的风险用户识别装置 的模块示意图; 图3为本发明一实施例提供的实现基于声纹特征与关联图谱数据的风险用户识别 方法的电子设备的内部结构示意图; 本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。











