
技术摘要:
本发明公开了一种数据导入方法、装置、计算机设备及存储介质。所述方法包括:获取待导入数据信息;在当前时间达到执行时间时,根据数据源标识从对应的数据表中获取待导入数据,保存在分布式文件系统中,并且从对应的数据表中获取数据结构信息;根据数据类型对数据结构 全部
背景技术:
Druid是Java中开源的数据连接池,是一种开源的,分布式的,支持海量数据实时 分析的开源分布式数据存储系统。Druid通常用于商业智能/OLAP(Online Analytical Processing,联机分析处理)应用程序,以分析大量的实时和历史数据。旨在帮助企业实现 快速处理超大规模的数据,并能够实现快速查询和分析。 目前,官方给出的存储在Druid里的数据的接入方式是:用户根据外部数据源的数 据结构和表结构提前编写一个相配套的配置文件,这个配置文件在Druid中被称为 Ingestion Spec(数据摄取规范),在这个配置文件中指定数据摄入时需要的各种相关参 数,然后调用Druid提供的接口,读取并执行编写好的配置文件,从而实现Druid单个数据资 源的单次数据的摄入。 这种实现方式非常不便,编写配置文件很容易出错,在面对大量数据导入的情况 下,效率很低。
技术实现要素:
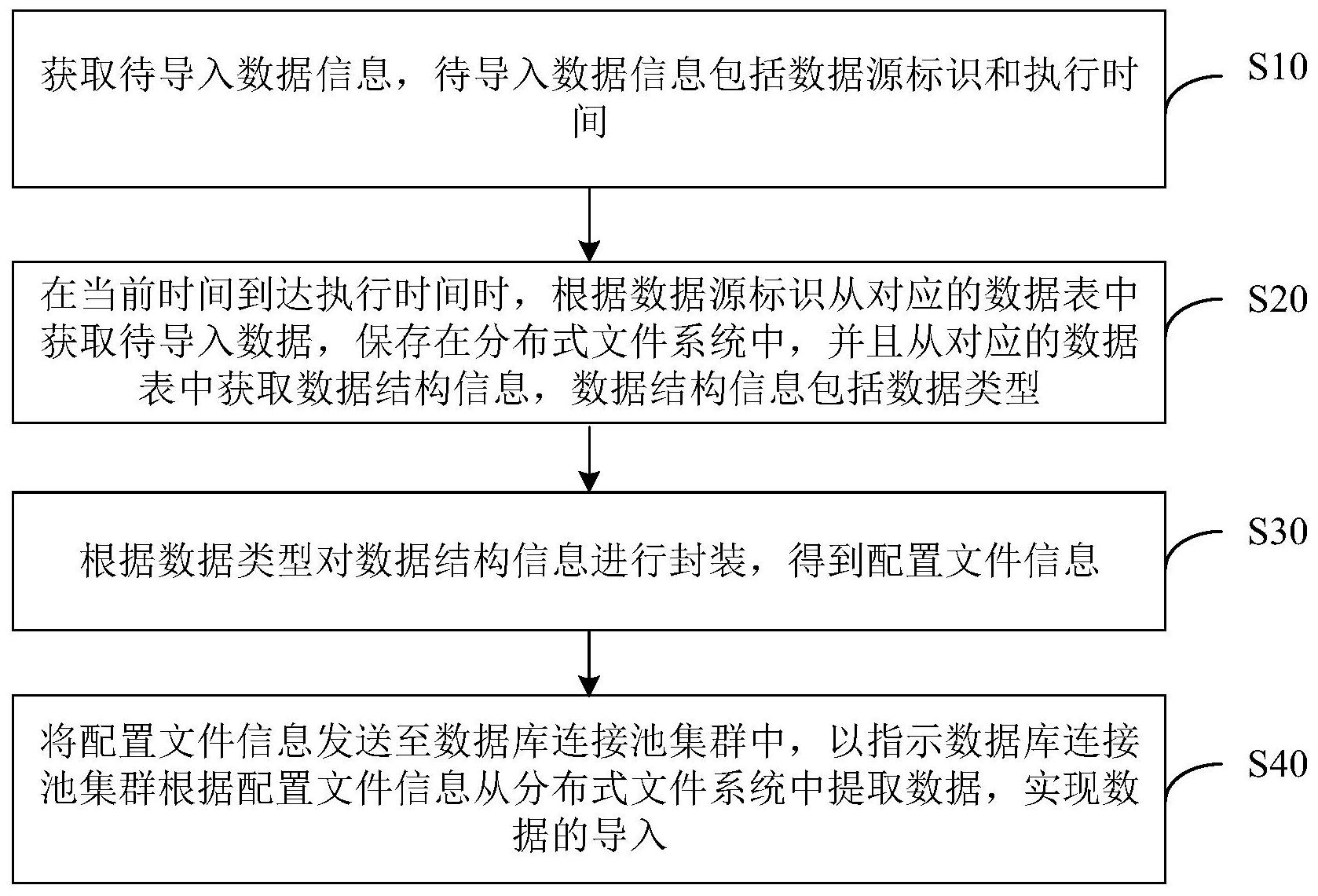
本发明实施例提供一种数据导入方法、装置、计算机设备及存储介质,以解决编写 配置文件很容易出错,在面对大量数据导入的情况下,数据导入效率低下的问题。 一种数据导入方法,包括: 获取待导入数据信息,所述待导入数据信息包括数据源标识和执行时间; 在当前时间达到所述执行时间时,根据所述数据源标识从对应的数据表中获取待 导入数据,保存在分布式文件系统中,并且从对应的数据表中获取数据结构信息,所述数据 结构信息包括数据类型和数据信息; 根据所述数据类型对所述数据结构信息进行封装,得到配置文件信息; 将所述配置文件发送至数据库连接池集群中,以指示所述数据库连接池集群根据 所述配置文件信息从所述分布式文件系统中提取所述待导入数据,实现数据的导入。 一种数据导入装置,包括: 信息获取模块,用于获取待导入数据信息,所述待导入数据信息包括数据源标识 和执行时间; 数据获取模块,用于在当前时间达到所述执行时间时,根据所述数据源标识从对 应的数据表中获取待导入数据,保存在分布式文件系统中,并且从对应的数据表中获取数 据结构信息,所述数据结构信息包括数据类型和数据信息; 信息封装模块,用于根据所述数据类型对所述数据结构信息进行封装,得到配置 文件信息; 4 CN 111581169 A 说 明 书 2/10 页 数据导入模块,用于将所述配置文件发送至数据库连接池集群中,以指示所述数 据库连接池集群根据所述配置文件信息从所述分布式文件系统中提取所述待导入数据,实 现数据的导入。 一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理 器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述数据导入方法的步 骤。 一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计 算机程序被处理器执行时实现上述数据导入方法的步骤。 上述数据导入方法、装置、计算机设备及存储介质中,通过获取待导入数据信息, 待导入信息包括数据源标识和执行时间;在当前时间达到执行时间时,根据数据源标识从 对应的数据表中获取待导入数据,保存在分布式文件系统中,并且从对应的数据表中获取 数据结构信息,数据结构信息包括数据类型和数据信息;根据数据类型对数据结构信息进 行封装,得到配置文件信息;将配置文件发送至数据库连接池集群中,以指示数据库连接池 集群根据配置文件从分布式文件系统中提取待导入数据,实现数据的导入。能够快速实现 数据自动化批量导入,同时,支持不同数据格式的导入,数据导入过程无需人工干预,避免 了手工编写配置文件而引发的各种错误,整个过程大大提高了生产效率,且使用成本非常 低。 附图说明 为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例的描述中所 需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施 例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图 获得其他的附图。 图1是本发明一实施例中数据导入方法的一应用环境示意图; 图2是本发明一实施例中数据导入方法的一流程图; 图3是本发明一实施例中数据导入方法的一流程图; 图4是本发明一实施例中数据导入方法的步骤S20的一流程图; 图5是本发明一实施例中数据导入方法的步骤S30的一流程图; 图6是本发明一实施例中数据导入方法的步骤S40的一流程图; 图7是本发明一实施例中数据导入装置的一原理框图; 图8是本发明一实施例中计算机设备的一示意图。











