
技术摘要:
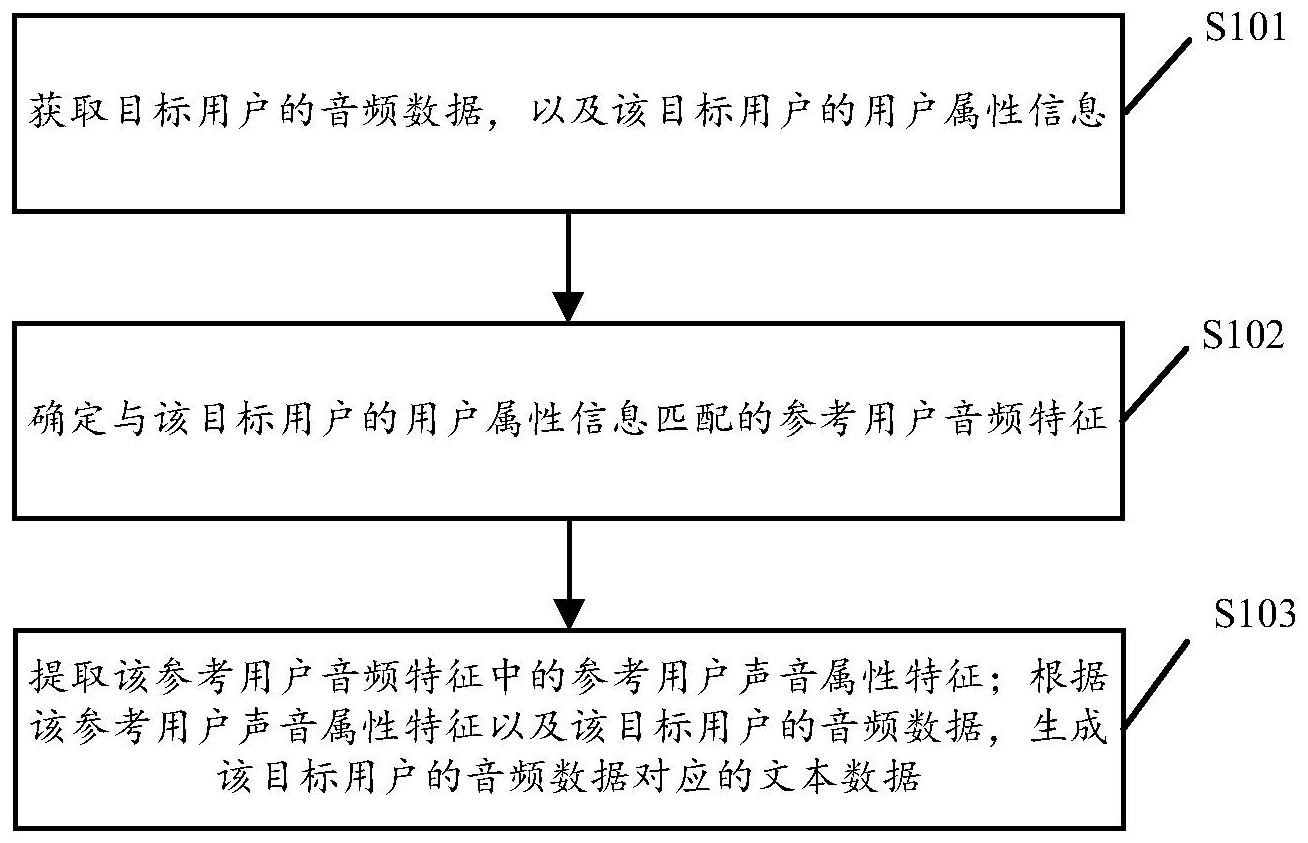
本申请实施例公开了一种音频数据处理方法、装置、存储介质以及设备,属于人工智能‑语音相关的技术领域。其中,该方法包括:获取目标用户的音频数据,以及所述目标用户的用户属性信息;确定与所述目标用户的用户属性信息匹配的参考用户音频特征,所述参考用户音频特征 全部
背景技术:
人工智能软件技术主要包括计算机视觉技术、语音识别技术、自然语言处理技术 以及机器学习/深度学习等几大方向。其中,语音识别技术(也可称之为音频识别技术)是指 一种将音频数据转换为相应的文本数据或操作指令的技术,被广泛应用于机器翻译、语音 搜索、语音输入、语音对话、智能问答等各个领域。目前的音频识别方法主要是通过分析音 频数据的内容,将音频数据转换为文本数据,实践中发现,受地域等因素的影响,存在不同 用户对同一个词或词组的发音不同的情况,导致目前的语音识别方法不能准确的识别出音 频数据对应的文本数据,不能达到预期的音频识别效果。
技术实现要素:
本申请实施例所要解决的技术问题在于,提供一种音频数据处理方法、装置、存储 介质及设备,能够提高识别文本数据的准确度。 本申请实施例一方面提供一种音频数据处理方法,包括: 获取目标用户的音频数据,以及上述目标用户的用户属性信息; 确定与上述目标用户的用户属性信息匹配的参考用户音频特征,上述参考用户音 频特征是对参考用户的历史音频数据进行音频特征提取得到的,上述参考用户的用户属性 信息与上述目标用户的用户属性信息匹配; 提取上述参考用户音频特征中的参考用户声音属性特征;根据上述参考用户声音 属性特征以及上述目标用户的音频数据,生成上述目标用户的音频数据对应的文本数据。 本申请实施例一方面提供一种音频数据处理装置,包括: 获取模块,用于获取目标用户的音频数据,以及上述目标用户的用户属性信息; 确定模块,用于确定与上述目标用户的用户属性信息匹配的参考用户音频特征, 上述参考用户音频特征是对参考用户的历史音频数据进行音频特征提取得到的,上述参考 用户的用户属性信息与上述目标用户的用户属性信息匹配; 识别模块,用于提取上述参考用户音频特征中的参考用户声音属性特征;根据上 述参考用户声音属性特征以及上述目标用户的音频数据,生成上述目标用户的音频数据对 应的文本数据。 可选的,识别模块,具体用于获取目标音频识别模型;采用上述目标音频识别模型 提取上述参考用户音频特征中的参考用户声音属性特征;根据上述参考用户声音属性特征 以及上述目标用户的音频数据,生成上述目标用户的音频数据对应的文本数据。 可选的,上述目标音频识别模型包括感知层、特征提取层、联通层以及识别层;可 选的,识别模块,具体用于: 5 CN 111554300 A 说 明 书 2/18 页 采用上述感知层对上述参考用户音频特征进行属性特征提取,得到上述参考用户 声音属性特征; 采用上述特征提取层对上述目标用户的音频数据进行音频特征提取,得到目标用 户音频特征;上述目标用户音频特征包括目标用户声音属性特征,以及关注于上述音频数 据的音频内容特征; 在上述联通层中,根据上述参考用户声音属性特征,对上述目标用户声音属性特 征进行增强处理,得到增强处理后的声音属性特征; 采用上述识别层对增强处理后的声音属性特征以及上述音频内容特征进行识别, 得到上述目标用户的音频数据对应的文本数据。 可选的,识别模块,具体用于获取上述目标用户声音属性特征的特征启始标识以 及特征结束标识; 在上述联通层中,在上述特征启始标识所在的位置之前拼接上述参考用户声音属 性特征,在上述特征结束标识所在的位置之后拼接上述参考用户声音属性特征,得到增强 处理后的声音属性特征。 可选的,上述装置还包括: 调整模块,用于获取语言模型,以及音频识别模型,上述语言模型具有预测文本数 据的能力,上述语言模型是通过样本本文数据训练得到的,上述语言模型的结构与上述音 频识别模型的结构匹配; 采用上述语言模型的参数对上述音频识别模型的参数进行初始化处理; 获取样本用户的音频数据,上述样本用户的音频数据的标注文本数据,以及与上 述样本用户的用户属性信息匹配的参考样本用户音频特征; 采用上述样本用户的音频数据、上述样本用户的音频数据的标注文本数据、以及 上述参考样本用户音频特征对初始化后的音频识别模型进行调整; 将调整后的音频识别模型确定为上述目标音频识别模型。 可选的,调整模块,具体用于采用上述语言模型的参数,对上述音频识别模型的识 别层的参数进行初始化处理,得到初始化后的音频识别模型;上述语言模型的结构与上述 音频识别模型的识别层的结构相同。 可选的,调整模块,具体采用上述初始化后的音频识别模型对上述样本用户的音 频数据以及上述参考样本用户音频特征进行识别,得到上述样本用户的音频数据对应的预 测文本数据; 根据上述预测文本数据以及上述标注文本数据,确定上述初始化后的音频识别模 型的识别损失值; 若上述识别损失值不满足收敛条件,则根据上述损失值对上述初始化后的音频识 别模型进行调整,得到调整后的音频识别模型。 可选的,确定模块,具体用于获取候选用户集合,以及上述候选用户集合中的候选 用户的用户属性信息; 将上述候选用户集合中用户属性信息,与上述目标用户的用户属性信息匹配的候 选用户作为参考用户; 获取上述参考用户的历史音频数据,对上述参考用户的历史音频数据进行音频特 6 CN 111554300 A 说 明 书 3/18 页 征提取,得到候选用户音频特征; 对上述候选用户音频特征进行融合,得到上述参考用户音频特征。 可选的,上述候选用户的用户属性信息包括上述候选用户所属的位置,上述目标 用户的用户属性信息包括上述目标用户所属的位置; 可选的,确定模块,具体用于获取上述候选用户集合中的候选用户所属的位置,与 上述目标用户所属的位置之间的位置关系; 将上述候选用户集合中位置关系为从属关系或等同关系的候选用户,作为上述参 考用户。 可选的,上述候选用户的用户属性信息包括上述候选用户的年龄,上述目标用户 的用户属性信息包括上述目标用户的年龄; 可选的,确定模块,具体用于获取上述候选用户集合中的候选用户的年龄,与上述 目标用户的年龄之间的年龄差值; 将上述候选用户集合中年龄差值小于年龄阈值的候选用户,作为上述参考用户。 可选的,确定模块,具体用于获取上述候选用户音频特征之间的相似度; 从上述候选用户音频特征中筛选出相似度大于相似度阈值的候选用户音频特征; 对筛选所得到的候选用户音频特征进行平均化处理,得到上述参考用户音频特 征。 本申请一方面提供了一种计算机设备,包括:处理器及存储器; 处理器,适于实现一条或多条指令;以及, 计算机存储介质,上述计算机存储介质存储有一条或多条指令,上述一条或多条 指令适于由上述处理器加载并执行如下步骤: 获取目标用户的音频数据,以及上述目标用户的用户属性信息; 确定与上述目标用户的用户属性信息匹配的参考用户音频特征,上述参考用户音 频特征是对参考用户的历史音频数据进行音频特征提取得到的,上述参考用户的用户属性 信息与上述目标用户的用户属性信息匹配; 提取上述参考用户音频特征中的参考用户声音属性特征;根据上述参考用户声音 属性特征以及上述目标用户的音频数据,生成上述目标用户的音频数据对应的文本数据。 本申请实施例一方面提供了一种计算机可读存储介质,上述计算机可读存储介质 存储有一条或多条指令,上述一条或多条指令适于由处理器加载并执行如下步骤: 获取目标用户的音频数据,以及上述目标用户的用户属性信息; 确定与上述目标用户的用户属性信息匹配的参考用户音频特征,上述参考用户音 频特征是对参考用户的历史音频数据进行音频特征提取得到的,上述参考用户的用户属性 信息与上述目标用户的用户属性信息匹配; 提取上述参考用户音频特征中的参考用户声音属性特征;根据上述参考用户声音 属性特征以及上述目标用户的音频数据,生成上述目标用户的音频数据对应的文本数据。 本申请中,计算机设备可以获取目标用户的音频数据,以及目标用户的用户属性 信息,确定与该目标用户的用户属性信息匹配的参考用户音频特征,提取该参考用户音频 特征中的参考用户声音属性特征。由于参考用户的用户属性信息与目标用户的用户属性信 息匹配,即参考用户声音属性特征与目标用户声音属性特征之间具有相似性,也即参考用 7 CN 111554300 A 说 明 书 4/18 页 户声音属性特征可用于描述目标用户针对音频数据的发音特征,以及文本数据的表达形 式;同时,由于目标用户的音频数据所提供的信息量太少,难以根据目标用户的音频数据中 获取到准确的目标用户声音属性特征。因此,可根据参考用户声音属性特征以及目标用户 的音频数据,生成目标用户的音频数据对应的文本数据,通过在音频数据中引入参考用户 声音属性特征,有利于体现目标用户个性化的发音特征,并体现目标用户的个性化的文本 数据表达形式,提高识别文本数据的准确度。 附图说明 为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现 有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本 申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以 根据这些附图获得其他的附图。 图1是本申请提供的一种音频数据处理系统的架构示意图; 图2是本申请提供的一种音频数据处理系统中各个设备的交互过程的场景示意 图; 图3是本申请实施例提供的一种音频数据处理方法的流程示意图; 图4是本申请提供的一种获取参考用户音频特征的场景示意图; 图5是本申请提供的一种获取参考用户音频特征的流程示意图; 图6是本申请提供的一种获取目标音频识别模型的流程示意图; 图7是本申请提供的一种调整音频识别模型的场景示意图; 图8是本申请提供的一种采用目标音频识别模型识别文本数据的场景示意图; 图9是本申请实施例提供的一种音频数据处理装置的结构示意图; 图10是本申请实施例提供的一种计算机设备的结构示意图。











