
技术摘要:
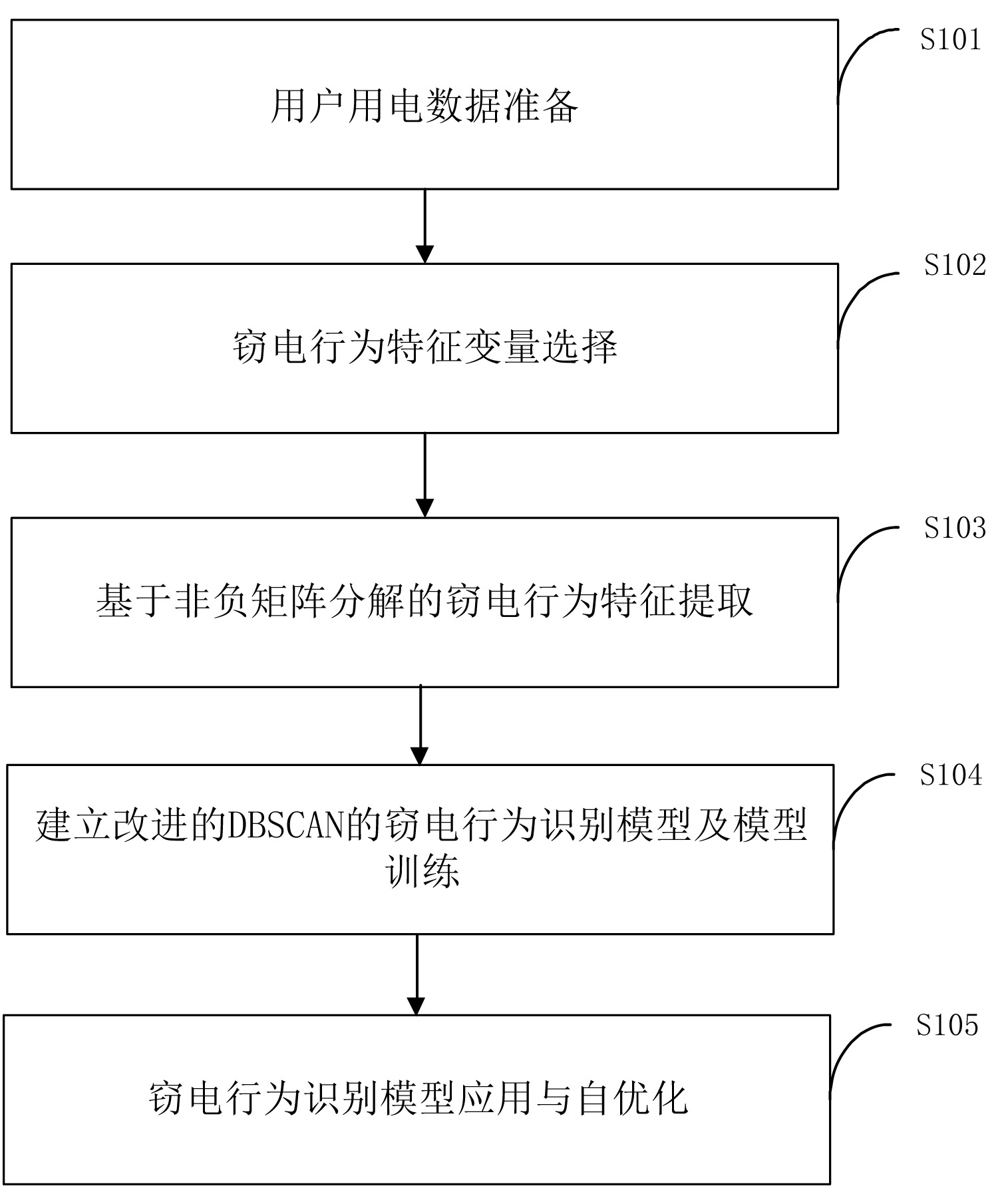
本发明涉及一种基于非负矩阵分解和密度聚类的用户窃电行为识别方法,其包括如下步骤:(1)用户用电数据的准备:包括选择数据源和数据筛选与清洗;(2)窃电行为特征变量选择,得到原始窃电特征集;(3)基于非负矩阵分解的窃电行为特征提取;(4)建立改进的DBSCAN的 全部
背景技术:
窃电行为严重损害了企业和个人的合法权益,扰乱了正常的供用电秩序,阻碍了 电力事业的发展,给安全用电带来了严重威胁,据报道每年全国因窃电损失电费多达上百 亿元,另外因窃电导致事故所造成的间接损失则更为巨大。 现场用电检查人员目前主要采用人工的方式进行检查,包括核查拆箱、拆电能表 等方法,不仅工作量大,且容易造成用户强烈反对,现场工作难度较大。目前用电信息采集 数据分析也是围绕电参量数据展开,目前用电信息采集系统及一体化线损系统中现有异常 数据存在大量误报警和错报警,这些噪声信息影响了分析的有效性,现有研究方法主要为 基于划分思想的K-means算法及其变体,且主要采用单一算法,这类算法不能解决非凸数 据,在面对信息冗余程度高、用电模式复杂的用电数据时容易陷入局部最优,难以获得理想 的检测精度。
技术实现要素:
本发明的目的是提供一种能够基于非负矩阵分解和密度聚类的用户窃电行为识 别方法,相对于传统人工排查窃电行为的查窃方式,提升了查窃工作效率。具体的,本发明 采用的基于改进密度聚类的窃电行为识别模型避免了传统基于划分思想的算法容易受噪 声影响、仅可聚类规则形状、容易陷入局部最优、受算法初始设定值的影响大的缺点,可实 现窃电行为精准识别。应用本发明开展用电检查工作,提高查窃工作开展效率和精准度,有 利于降低国家电费损失,减少国有财产流失。 本发明采用如下技术方案: 一种基于非负矩阵分解和密度聚类的用户窃电行为识别方法,其包括如下步骤: (1)用户用电数据的准备:包括选择数据源和数据筛选与清洗; (2)窃电行为特征变量选择,得到原始窃电特征集; (3)基于非负矩阵分解的窃电行为特征提取; (4)建立改进的DBSCAN的窃电行为识别模型及模型训练; (5)利用窃电行为模型对所有用户进行窃电嫌疑筛选,得到高窃电嫌疑度用户,查 窃人员到现场进行核查确认。 进一步的,所述选择数据源包括从用电信息采集系统、营销业务应用系统中抽取 近三年查实的专变窃电用户用电负荷信息、事件记录及档案信息。 进一步的,所述数据筛选的过程为:对窃电用户原始数据的甄别,去掉由于计量装 置故障导致的误报数据和完整率过低的数据; 所述数据清洗的过程为:对于采集点少量缺失的数据,采用差值法进行补充。 4 CN 111612054 A 说 明 书 2/7 页 进一步的,所述窃电行为特征变量包括基础特征变量、导出特征变量。 进一步的,所述基础特征变量包括: (a)负荷信息:包括用户电流、用户电压、电量、用户功率及功率因数; (b)事件记录信息:开表盖事件、电能表清零事件、恒定电磁场干扰事件、历史违约 用电记录、电能表失压失流事件及负荷开关误动或拒动等事件记录; (c)用电类别等用户档案信息:用户用电地址、用户号、电能表条形码、用电类别、 行业类别、用电台区编号等信息。 进一步的,所述导出特征变量包括:负荷突变日、突变日前后负荷电流均值比、采 集点缺失、突变日前后负荷不平衡度、功率计算与召测误差、日负荷功率方差等、负荷季节 特性、负荷温度敏感性、负荷稳定性、负荷增长率、负荷峰谷特性、负荷周休特性。 进一步的,所述窃电行为特征变量选择还包括,将非数值化数据进行结构转换,其 方法为:对用户用电类型、季节特性、温度敏感性、负荷稳定性、负荷增长率、峰谷特性、周休 特性进行数据结构转换,具体包括: (I)将所述用电类别分为工业、商业、居民、农业排灌、农业生产、临时用电6种; 将所述温度特性分为高温敏感、低温敏感、不敏感3种; 将所述用电稳定性分为非常高、比较高、一般、较低4种; 将所述负荷增长率分为快速上涨、上涨、持平、降低、快速降低5种; 将所述采集点缺失分为无缺失、缺失较少、缺失较多3种; (II)对所述非数值化数据,按照分类顺序从左到右依次编号。 进一步的,所述步骤(3)的具体过程为: (A)以步骤(2)原始窃电特征集构建的原始窃电特征矩阵V; (B)将原始窃电特征矩阵V分解为低秩的窃电特征基矩阵W和系数矩阵H; 其过程为:初始化W、H矩阵为非负随机矩阵;按下式对W、H进行同步迭代运算; (C)用低秩的窃电特征基矩阵W代替原始窃电特征集,实现窃电特征提取,并将提 取的窃电特征作为特征变量构建用户样本数据集。 进一步的,所述MinPts≥dim 1,其中dim表示待聚类用户样本数据的维度,且 MinPts≥3。 进一步的,所述步骤(4)中,利用遗传算法对DBSCAN聚类算法的半径(eps)和密度 阈值(MinPts)进行优化,并将步骤(3)得到的用户样本数据集作为训练样本输入优化后的 DBSCAN聚类模型,得到各用户样本对所属聚类中心的隶属度,根据隶属度大小判断用户样 本的离群度,并与预设的离群度阈值比较,输出用户是否窃电的结果。 进一步的,所述步骤(4)中,以已查实的窃电用户样本数据输入至基于DBSCAN窃电 识别模型,验证窃电识别模型是否可分出至准确的类别,并分析原因,调整遗传算法初始参 数使模型识别窃电效果最佳。 5 CN 111612054 A 说 明 书 3/7 页 本发明的有益效果在于: 1、本发明可以广泛应用到国网公司下属各网省公司反窃电工作中,利用大数据技 术对全部管理辖区快速“扫描”代替人工排查,大幅度减少窃电用户识别时间,提高反窃电 工作开展效率。 2、本发明采用的密度聚类法可以对任意形状的稠密数据集进行聚类,相对的,K- means之类的聚类算法一般只适用于凸数据集,因此本发明所述的窃电行为识别更加精准, 不会错分不规则分布的同类窃电行为,提高了窃电行为识别准确度。 3、本发明采用的遗传算法优化的密度聚类法解决了聚类半径和聚类密度阈值难 以选取的问题,相对的,K-means之类的聚类算法初始值对聚类结果有很大影响。 附图说明 图1为本发明的流程示意图。











