
技术摘要:
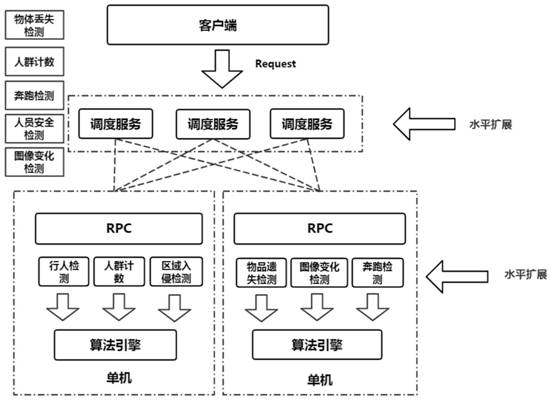
本发明公开了一种深度学习技术的行为智能分析引擎系统及控制方法。该系统包括调度中心和算法集群,算法集群包括多个计算服务器;调度中心通过调用负载均衡调度算法将行为分析任务消息分发到计算服务器;计算服务器包括深度学习GPU显卡计算模块和线程池模块;深度学习GP 全部
背景技术:
随着科技的飞速发展,汽车,网购,电子支付等新兴技术逐渐出现,同时也产生了 很多信息数据。网络,智能手机的普及也成就了大数据时代,在如今这个充满海量数据的时 代,这些数据中包含了大量的视频图像信息,传统方式的人工处理已经出现了人力物力不 足等各种问题,迫切需要用机器去取代人工,发挥机器自身的优势,于是人工智能,深度学 习技术应运而生。 针对高分率的视频图像数据,进行深度学习推理计算需要耗费更多的计算资源, 并且由于用户的不断增长,社区规模的不断扩大,进行深度学习领域的图像处理需要承担 更大的负载。 本发明基于深度学习技术对人进行行为分析,行为分析是指通过分析视频、深度 传感器等数据,利用特定的算法,对行人的行为进行识别、分析的技术。这项技术被广泛应 用在视频分类、人机交互、安防监控等领域。行为识别包含两个研究方向:个体行为识别与 群体行为识别。近年来,深度摄像技术的发展使得人体运动的深度图像序列变得容易获取, 结合高精度的骨架估计算法,能够进一步提取人体骨架运动序列。利用这些运动序列信息, 行为识别性能得到了很大提升,对智能视频监控、智能交通管理及智慧城市建设等具有重 要意义。同时,随着行人智能分析与群体事件感知的需求与日俱增,一系列行为分析与事件 识别算法在深度学习技术的推动下浮于眼前。 从个人,家庭,社区到城市甚至国家,随着智能分析引擎系统服务部署范围的不断 扩大,流量越来越大,单机已无法承担大量流量数据的冲击,所以需要服务使用大量的机器 形成集群,但是传统的方式无法很方便的扩展,造成服务冗余与资源浪费现象。
技术实现要素:
针对现有技术的至少一个缺陷或改进需求,本发明提供了一种深度学习技术的行 为智能分析引擎系统及控制方法,使用分布式通信协议架构和容器技术弹性伸缩保证服务 的稳定和高效,并且可以为每个算法模型配置资源,提高计算资源的利用率。 为实现上述目的,按照本发明的第一方面,提供了一种深度学习技术的行为智能 分析引擎系统,包括调度中心和与所述调度中心通过网络连接的算法集群,所述算法集群 包括多个计算服务器; 所述调度中心用于接收行为分析任务消息,调用负载均衡调度算法将行为分析任 务消息分发到所述计算服务器; 所述计算服务器包括深度学习GPU显卡计算模块和线程池模块; 所述深度学习GPU显卡计算模块用于接收所述调度中心分发的行为分析任务消 4 CN 111614769 A 说 明 书 2/6 页 息,根据行为分析任务消息将对应的算法模型加载到GPU显卡的显存中,执行行为分析任 务; 所述线程池模块用于将不同的行为分析任务进行隔离,为每个算法模型配置资 源。 优选地,所述线程池模块包括算法模型配置文件定义模块; 所述算法模型配置文件定义模块用于预先定义或修改算法模型配置文件,所述算 法模型配置文件中定义了对应的算法模型运行所需要的工作线程数据。 优选地,所述深度学习GPU显卡计算模块包括多个不同类型的GPU显卡; 所述算法模型配置文件定义了对应的算法模型运行的GPU显卡。 优选地,所述行为分析任务消息为JSON格式,所述深度学习GPU显卡计算模块包 括: 解析模块,用于将接收的JSON格式的行为分析任务消息转换为Mat二维矩阵格式; 封装模块,用于将执行行为分析任务后的分析结果封装为JSON格式后返回给调度 中心。 优选地,包括扩展模块,用于修改系统配置文件以支持所述调度中心和所述算法 集群扩展。 优选地,所述行为分析任务消息包括请求算法类型字段,所述深度学习GPU显卡计 算模块包括消息队列处理模块,用于根据请求算法类型字段分别为不同请求算法类型的所 述行为分析任务消息开启消息队列。 按照本发明的第二方面,提供了一种深度学习技术的行为智能分析引擎控制方 法,包括步骤: 接收行为分析任务消息,调用负载均衡调度算法将行为分析任务消息分发到计算 服务器; 在计算服务器中接收分发的行为分析任务消息,根据行为分析任务消息将对应的 算法模型加载到GPU显卡的显存中,执行行为分析任务; 将不同的行为分析任务进行隔离,为每个算法模型配置资源。 按照本发明的第三方面,提供了一种计算机可读存储介质,其上存储有计算机程 序,所述计算机程序被处理器执行时实现上述任一项方法。 总体而言,本发明与现有技术相比,具有有益效果: (1)本发明充分利用具有高效率通信的ZMQ通信框架,实现了服务系统中的核心通 信模块,并使用容器技术实现了分析服务的强移植性、便携性、稳定性,具体来说包括: (1.1)支持横向扩展,通过增加机器数量,建立集群环境,借助ZMQ消息通信框架提 供的负载均衡算法,便可大大提高智能分析引擎处理数据的吞吐量,进而满足高并发场景 的需要。 (1 .2)随着请求不断增加,系统压力增大,这时可以添加更多的节点到集群中,借 助更多的机器来实现负载均衡。此外,系统资源可以重新分配,以更好地支持一个动态扩展 的系统。各个节点负责完成不同的分析计算任务,多个节点通过协作,完成请求回应。 (1 .3)本发明采用无控制中心的多代理结构,每个算法集群都是独立的算法引擎 模块,尽量降低各个模块的相关性,实现模块解耦,真正实现了分布式计算的思想。 5 CN 111614769 A 说 明 书 3/6 页 (1.4)通过将一个或多个路由端节点连接起来,构成系统的调度中心,在路由端收 到请求后使用轮询算法,分发不同的行为分析任务到不同的分析计算节点,实现负载均衡。 并且可以通过修改Docker Compose文件服务配置选项ZMQ_ADDR参数,增加更多的分析计算 节点到算法集群中,增加系统的并发能力,减轻负载,避免由于请求压力过大,导致消息阻 塞排队延迟增加。 (1 .5)本发明采用Docker集群部署,部署便捷快速,运维方便,程序可以二十四小 时无间断运行,遇见突发事件,会在较短时间内进行重启。 (2)使用多线程方式基于Caffe模型实现推理计算,支持每一种算法自定义选择使 用更多的线程提高计算速度,避开Caffe不支持多线程的缺点,在空间和时间两者实现了可 配置化,根据不同算法的计算开销和显存开销,经权衡后,可以通过更改配置参数,对占据 空间大耗时短的算法选择更少的线程数,对占据空间小耗时长的算法选择更多的线程数。 (3)使用单服务器多GPU卡的配置参数,支持每一种算法自定义选择使用自定义的 GPU显卡,可根据不同显卡的计算能力匹配不同的应用场景。 (4)在执行人脸识别等任务时,需要根据接收到的人脸图像去数据库中搜索相似 度高的图片,本发明使用向量式数据库存储人脸等目标的特征信息,较传统使用CPU资源进 行搜索使用GPU资源矩阵式搜索最相似的特征,可以大幅度提高搜索效率,同时也解放CPU 资源,从而大大降低机器的CPU负载,CPU不再是计算的瓶颈。 附图说明 图1是本发明实施例的行为智能分析引擎系统的框架示意图; 图2是本发明实施例的行为智能分析引擎控制方法的示意图; 图3是本发明实施例的负载均衡示意图; 图4是本发明实施例的消息队列处理示意图; 图5是本发明实施例的执行行为智能分析任务的流程示意图; 图6是本发明实施例的行为智能分析引擎系统的扩展示意图。











