
技术摘要:
本发明公开了一种基于手机信令数据与POI兴趣点数据的个体行为分析方法,用于解决特殊社会人群的个人出行行为辨识问题。该方法包含个人出行特征提取与出行行为预测两部分:(1)个人出行特征提取:使用手机信令数据,完成个人的出行链提取;基于个人出行链数据,设计出行 全部
背景技术:
近几年来,随着智能手机与4G通信技术的普及,手机已成为大部分人每天随身携 带的设备之一,手机信令数据因此具有数据量大,覆盖用户面广等优点。通过分析手机信令 数据,出行特征,得出人群活动规律、生活习性等较为丰富的语义信息,逐渐成为了轨迹数 据挖掘领域研究的热点。 交通出行对于每个居民的日常生活都十分重要,出行作为一种派生性需求,个体 基于活动,通过安排出行OD(origin-destnation,起止点)、出行时间和出行方式来组织日 常生活。在“交通公平性”的目的和背景下,通过分析低收入等特殊人群的出行模式,解决这 部分人群的日常出行问题显得十分重要。 关于如何分析特殊人群的出行行为这一问题,目前大部分的解决方案是采用调查 问卷的方式,该方法具有数据量低、样本随机性大等缺点。本发明提出了一种基于手机信令 数据与POI兴趣点数据的个人出行行为估计方法,充分利用了手机信令数据覆盖用户面广, 数据量大等优点,较为准确地分析了特殊人群的出行行为。
技术实现要素:
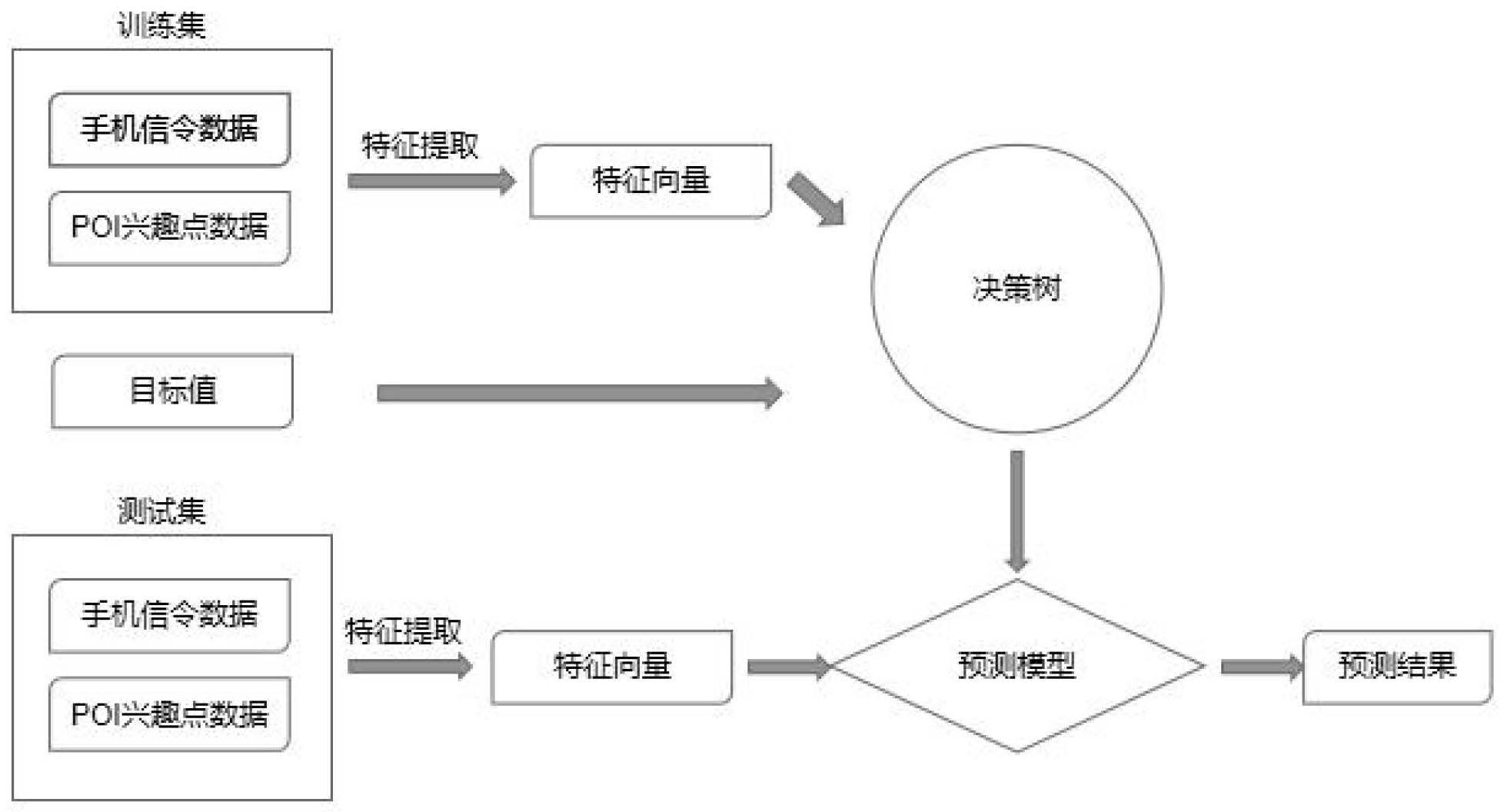
本发明的技术解决问题:解决了使用调查问卷等传统方式获取人群出行行为样本 随机性大、数据量低等问题。提出了基于手机信令数据与POI兴趣点数据的个人出行行为估 计方法,该方法能较为准确地分析用户的出行行为。 本发明的技术解决方案为:一种基于手机信令数据与POI兴趣点的个体行为分析 方法,步骤如下: 步骤1、获取个体手机信令数据,对手机信令数据进行预处理;首先剔除数据格式 错误,数据字段缺失的数据;然后通过时间阈值与空间阈值,完成长距离抖动信令数据的剔 除;最后通过制定活跃用户判别规则,完成优质用户的提取; 步骤2、通过手机信令数据预处理,得到蕴含用户时空信息的信令数据;采用ST- DBSCAN密度聚类算法,完成用户停留态,移动态的识别;生成用户的出行链数据;根据用户 的多天的出行链数据,设立居家时间段与工作时间段,完成用户职住地数据的提取; 步骤3、根据用户的出行链数据与职住地数据,结合周边POI兴趣点数据,POI兴趣 点在地理信息系统中指某个位置点的周边信息,比如银行、商店、加油站等。可以通过调用 互联网地图服务商提供的接口来获取POI信息,结合个体的出行链数据与职住数据,分析个 体的出行行为设计出行特征数据:包括用户离家时间,用户归家时间,用户出行距离,用户 出行次数,用户出行轨迹相似性,用户出行时间,用户居住地数量,用户工作地数量;依据用 户出行特征数据,采用决策树预测方法,完成个体行为的分析。 6 CN 111582948 A 说 明 书 2/8 页 进一步的,所述步骤(1)中长距离抖动信令数据的剔除具体实现过程如下: 对于某一用户一段时间内产生的手机信令数据序列:cellDatai-1(lngi-1,lati-1, timei-1),cellDatai(lngi,lati,timei) , cellDatai 1(lngi 1,lati 1,timei 1) ...,其中cellData表示信令数据,lng表示该 信令数据产生时的位置的经度,lat表示该信令产生的位置的纬度,time表示该信令发生的 时间;i表示信令的序号;剔除条件如下: Dis(cellDatai-1,cellDatai)>Dthread∩ Dis(cellDatai,cellDatai 1)>Dthread∩ Spd(cellDatai-1,cellDatai)>Sthread∩ Spd(cellDatai,cellDatai 1)>Sthread 其中,Dis(cellDatai-1 ,cellDatai)表示信令i-1与信令i之间的产生的位置点之 间的距离,Spd(cellDatai-1,cellDatai)表示用户产生信令i-1与产生信令i之间的移动速 度;Dthread表示距离阈值,Sthread表示速度阈值;结合城市人群出行规律,Dthread取 3000m,Sthread取180km/h;将符合条件的信令i删除; 进一步的,所述步骤(1)中优质用户的提取过程如下: 所述优质用户的定义为: (1.1)用户产生的一天内产生的信令数量大于80条; (1.2)用户在0点-7点间产生过3条以上的信令; (1.3)用户在8点-18点间每小时产生过1条以上的信令; (1.4)用户在19点-24点间产生过3条以上的信令; 同时满足上述四个条件的用户为优质用户,使用优质用户产生的信令数据进行后 续分析。 进一步的,所述步骤(2)具体实现过程如下: 对于某个用户产生的信令数据序列格式为:...cellDatai-1(lngi-1 ,lati-1 , timei-1),cellDatai(lngi ,lati ,timei) ,cellDatai 1(lngi 1 ,lati 1 ,timei 1) ...;其中 cellData表示信令数据,lng表示该信令数据产生时的位置的经度,lat表示该信令产生的 位置的纬度,time表示该信令发生的时间; 为提取用户的出行链,处理过程中的相关定义如下: 停留点:stopPoint(startTime,endTime,lng,lat),其中startTime表示停留开始 时间,endTime表示停留结束时间,lng表示停留点位置的经度,lat表示停留点位置的纬度; 移动点:movePoint(time,lng,lat),其中time表示移动时间,lng表示移动点位置 的经度; 出行链:tripChain(stopPointi,movePointi...movePointn,stopPointi 1...),出 行链由用户的停留点stopPoint与移动点movePoint按时间发生顺序构成。 进一步的,步骤(2)中,通过对信令数据采用ST-DBSCAN算法生成用户的停留点及 出行链数据; 用户处于停留状态在数据层面上表示为多条时间,空间上相近的信令集合,采用 ST-DBSCAN算法对信令数据在时间层面上与空间层面上进行聚类,算法相关定义如下:ε-邻 域:点p的ε-邻域是指以点p为圆心、ε为半径的区域。 7 CN 111582948 A 说 明 书 3/8 页 核心点:点p被称为核心点当且仅当点p的ε-邻域内的时序前驱和后继点的时间跨 度超过最短时间跨度阈值MinTimeSpan。 直接时间密度可达:点q由核心点p直接时间密度可达当且仅当点q在点p的ε-邻域 内并且点q是点p的时序直接前驱或后继点,或是p直接时间密度可达点的时序直接前驱或 后继点; 时间密度可达:点q由点p时间密度可达当且仅当存在一条路径p1,p2,…,pn,其中 p1=p,pn=q,对任意点pi 1都由pi直接时间密度可达。 ST-DBSCAN算法按以下流程执行: 步骤(2.1)载入用户位置序列D,把D中的点按时间先后顺序排序,并把所有的点标 记为未被访问unvisited; 步骤(2 .2)从排序后的序列中选择第一个未被访问的点p,标记为已被访问 visited;判断点p是否是核心点;如果点p是核心点,则创建一个新的簇C,把点p加入簇C;如 果点p不是核心点,则把点p标记为移动点;如果点p是核心点,创建一个集合N保存点p的所 有时间密度可达点; 步骤(2.3)对于N中的任意一个未被访问的点q:如果点q当前不属于任何簇,把点q 加入簇C中;如果点q是核心点,把点q的所有时间密度可达点加入集合N中; 步骤(2.4)重复步骤(2.3)直到集合N中所有的点都被访问; 步骤(2.5)重复步骤(2.2),直到所有的点都被访问; 进一步的,步骤(2)中, 停留点蕴含的语义信息比较匮乏,仅能表示用户的停留、移动状态。人群在停留时 都从事某项活动,例如工作、休息、娱乐等等。一般人群一天中的大量时间都花费在工作与 居家休息这两项活动中,因此根据停留点的时间段为停留点赋予居家、工作属性; 结合日常通勤规律,定义居家时间段为0点-7点、19点-24点;工作时间段为7点-19 点。 停留点属性算法如下: 步骤(2.1a)、从用户出行链中读取一个停留点SP,并计算其与工作时间段的交集 时长; 步骤(2.2a)、如果停留点SP与工作时段的交集时长大于3小时并且交集时长占停 留点SP停留时段的50%以上,将停留点SP标记为工作地; 步骤(2.3a)、否则计算停留点SP与居住时间段的交集时长,如果停留点SP与居住 时段的交集时长大于2小时并且交集时长占停留点SP停留时段的50%以上,将停留点SP标 记为居住地; 若步骤(2.2a)和步骤(2.3a)的条件均不满足,将停留点SP标记为其他; 重复步骤(2.1a),直到所有的停留点均被访问。 进一步的,所述步骤(3)具体实现过程如下: 基于个人出行链与职住点及POI兴趣点数据,设计出行特征如下: 离家时间:leaveHomeTime,指用户第一次离开居住地的时间; 居住地数量:homeCpunt,指用户的居住地数量; 工作地数量:workCount,指用户的工作地数量; 8 CN 111582948 A 说 明 书 4/8 页 回家时间:returnHomeTime,指用户最后一次返回居住地的时间; 出行距离:t r i p D i s ,指用户一天当中的移动距离,具体计算公式为: 其中dis表示两个相邻停留点间的距离,n为停留 点的数量; 出行时间:tripTime,指用户一天当中处于移动状态的时间,具体计算公式为: 出行次数:tripfreq,指用户一天的移动次数,具体为用户当天的停留点数量减1; 出行轨迹相似性:routeSimilar,指用户多天内的出行轨迹的相似程度;将一天划 分为24个小时,根据用户的出行链信息计算用户在每个时段的停留位置;采用最长公共子 序列LCSS算法计算用户的出行轨迹相似性; 进一步的,基于个人出行链与职住点及POI兴趣点数据,设计POI特征如下: POI特征为:从互联网地图上爬取POI兴趣点数据,根据数据类别将其分为5类:科 教文化、住宅区、工业园区、商业楼宇、其他; POI数据的格式如下:POI(kind ,lng ,lat),其中kind表示POI类别,lng表示该POI 位置的经度,lat表示该POI位置的纬度;定义居家时间段为0点-7点、19点-24点;工作时间 段为7点-19点;定义如下特征: PoiHomeTimei i∈{1,2,3,4,5}:表示用户一天内在第i个类别的POI区域内停留 时长占居家时间段的比例; PoiWorkTimei i∈{1,2,3,4,5}:表示用户一天内在第i个类别的POI区域内停留 时长占工作时间段的比例; 采用人工标注的方式,将人群的出行行为分为4类,分别为高校学生的出行行为、 工厂工人的出行行为、一般通勤者的出行行为、其他人员的出行行为;使用标注好的训练集 进行决策树预测模型的构建,选取部分没有标注的用户的信令数据,计算其出行特征,完成 特征向量的构建;使用训练好的预测模型输出用户出行行为的分析结果,得到出行行为为 高校学生、工厂工人、一般通勤者、其他人员出行行为中的一种。 有益效果: 关于如何分析特殊人群的出行行为这一问题,目前大部分的解决方案是采用调查 问卷的方式,该方法具有数据量低、样本随机性大等缺点。本发明提出了一种基于手机信令 数据与POI兴趣点数据的个人出行行为估计方法,充分利用了手机信令数据覆盖用户面广, 数据量大等优点,较为准确地分析了特殊人群的出行行为。 附图说明: 图1:本发明提出的出行行为预测模型图; 图2:本发明时空密度聚类算法(ST-DBSCAN)流程图; 图3:本发明停留点属性识别流程图。 9 CN 111582948 A 说 明 书 5/8 页











