
技术摘要:
本说明书一个或多个实施例提供的一种融入场景知识的事例分析方法及相关设备,包括:获取事例的文本信息,通过预训练语言模型对所述文本信息进行处理,生成第一向量,对所述第一向量进行随机遮挡训练生成第二向量;对所述文本信息进行属性分析生成属性向量,将所述属性 全部
背景技术:
事例指有多个分事例组成的一件完整的事,例如:去饭店吃饭是整个事例,包含点 餐、用餐、付钱、离开等多个分事例构成。在一个发生的事例条件下,人类可以很容易推断出 下个分事例或者推断上一个分事例,但是对于机器却很难实现这样的事例推理。 现有技术中,主要求助于联合训练,它通过一个简单的损失函数求和用于整合各 个水平的训练损失,然而这种训练方式极易陷入一个局部最优解。此外,在事例链条中,场 景知识并未很好的应用于事例表示中。
技术实现要素:
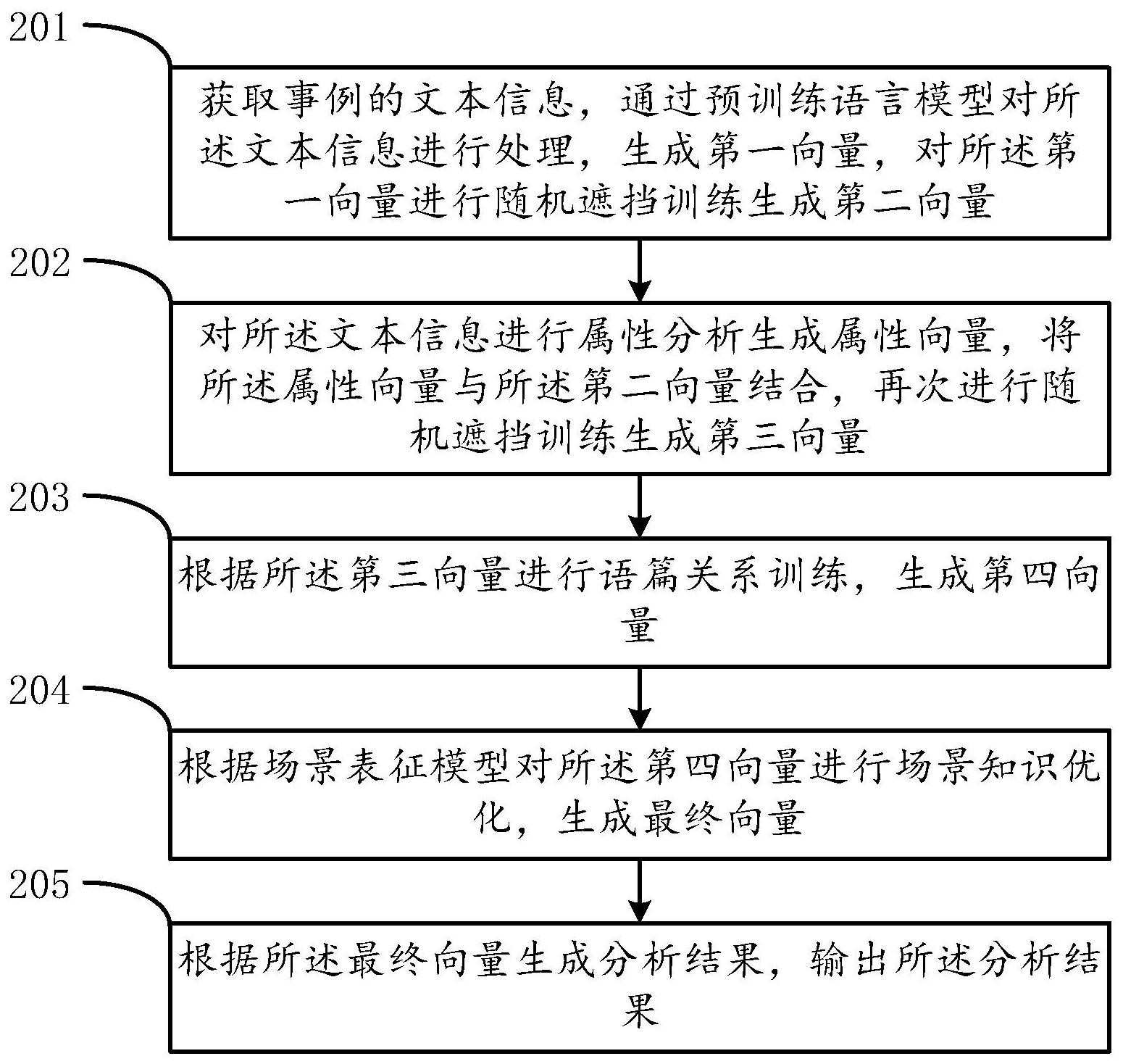
有鉴于此,本说明书一个或多个实施例的目的在于提出一种融入场景知识的事例 分析方法及相关设备。 基于上述目的,本说明书一个或多个实施例提供的一种融入场景知识的事例分析 方法,包括: 获取事例的文本信息,通过预训练语言模型对所述文本信息进行处理,生成第一 向量,对所述第一向量进行随机遮挡训练生成第二向量; 对所述文本信息进行属性分析生成属性向量,将所述属性向量与所述第二向量结 合,再次进行随机遮挡训练生成第三向量; 根据所述第三向量进行语篇关系训练,生成第四向量; 根据场景表征模型对所述第四向量进行场景知识优化,生成最终向量; 根据所述最终向量生成分析结果,输出所述分析结果。 在一些实施方式中,所述获取事例的文本信息,通过预训练语言模型对所述文本 信息进行处理,包括: 基于bert-base-uncased模型,采用Gigaword语料库作为预训练语料库对所述文 本信息进行处理。 在一些实施方式中,所述对所述第一向量进行随机遮挡训练生成第二向量,包括: 在所述第一向量中随机选取词汇向量,并通过遮挡标签进行遮挡,建立遮挡语言 模型,根据公式一进行所述遮挡语言模型最优解计算,得到所述第二向量; 其中,loss1st为遮挡语言模型损失函数,通过训练得到loss1st的最小值确定最优 解, 为单个被遮挡的词,[mask]为一组被遮挡的词, 为被遮挡词 在bert- base-uncased模型下的出现概率,λ为预先定义的权重参数,L(θ1)为设定参数θ1的L2正则化 5 CN 111611409 A 说 明 书 2/17 页 项。 在一些实施方式中,所述对所述文本信息进行属性分析生成属性向量,将所述属 性向量与所述第二向量结合,具体为: xi=ef,i ea,i ep,i 公式二 其中,xi为分事例内部具体的词向量,ef ,i为输入的第二向量,ea ,i为属性向量中的 词性向量,ep,i为属性向量中的位置向量; 其中,X为分事例内部全部的词向量,xi∈X,Transformer( )为一个一层的 transformer模型,Hi(i∈{1,2,…,l})为第i层transformer块所得的隐式向量。 在一些实施方式中,所述再次进行随机遮挡训练生成第三向量,包括: 在所述第二向量中随机选取词汇向量,并通过遮挡标签进行遮挡,建立遮挡语言 模型,根据公式四进行所述遮挡语言模型最优解计算,得到所述第三向量; 其中,loss2nd为遮挡语言模型损失函数,通过训练得到loss2nd的最小值确定最优 解, 为单个被遮挡的词,[mask]为一组被遮挡的词,λ为预先定义的权重参数,L(θ2)为设 定参数θ2的L2正则化项; 其中, 为隐式向量Hl和词性a条件下的词概率, 为被遮 挡词的属性概率。 在一些实施方式中,所述根据所述第三向量进行语篇关系训练,生成第四向量,包 括: 基于Event-TransE模型,根据公式六进行Event-TransE模型最优解计算,得到所 述第四向量; 其中,loss3rd为Event-TransE模型损失函数,通过训练得到loss3rd的最小值确定 最优解,T和T*为事例的全部正关系三元组和负关系三元组,t和t*为事例的一个正关系三元 组和负关系三元组,δ为边界参数,λ为预先定义的权重参数,L(θ3)为设定参数θ3的L2正则化 项; 其中,eh,rh,t,et分别为正关系三元组中的头分事例、关系和尾分事例, 分别为负关系三元组中的头分事例、关系和尾分事例,ftranse(x)为以x为输入的TransE函 6 CN 111611409 A 说 明 书 3/17 页 数,运算符 为p阶欧式距离。 在一些实施方式中,所述根据场景表征模型对所述第四向量进行场景知识优化, 生成最终向量,包括: 通过所述第四向量生成分事例链条,根据所述分事例链条的统计性隐式变量的先 验分布和后验概率通过公式八计算证据最低阈值,再根据所述证据最低阈值通过公式九进 行场景表征模型最优解计算,得到所述最终向量; 其中,LELBO(θ4,θ5)为证据最低阈值, 和 分别为分事例链条{e1,e2,…,en}的 先验分布 和后验概率 zi为统计性隐式变量,n为分事例链条{e1,e2,…,en}中分事例 的数量, 为后验概率 和先验分布 之间的Kullback-Leibler差异值, 为 在后验概率 下的期望值; 其中, 为场景表征模型损失函数,通过训练得到 的最小值确定最 优解,λ为预先定义的权重参数,L(θ4,θ5)为设定参数θ4,θ5的L2正则化项。 基于同一构思,本说明书一个或多个实施例还提供了一种融入场景知识的事例分 析设备,包括: 第一训练模块,获取事例的文本信息,通过预训练语言模型对所述文本信息进行 处理,生成第一向量,对所述第一向量进行随机遮挡训练生成第二向量; 第二训练模块,对所述文本信息进行属性分析生成属性向量,将所述属性向量与 所述第二向量结合,再次进行随机遮挡训练生成第三向量; 第三训练模块,根据所述第三向量进行语篇关系训练,生成第四向量; 第四训练模块,根据场景表征模型对所述第四向量进行场景知识优化,生成最终 向量; 输出模块,根据所述最终向量生成分析结果,输出所述分析结果。 基于同一构思,本说明书一个或多个实施例还提供了一种电子设备,包括存储器、 处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时 实现如上任意一项所述的方法。 基于同一构思,本说明书一个或多个实施例还提供了一种非暂态计算机可读存储 介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令用于使所述计算 机执行如上任一所述方法。 从上面所述可以看出,本说明书一个或多个实施例提供的一种融入场景知识的事 例分析方法及相关设备,包括:获取事例的文本信息,通过预训练语言模型对所述文本信息 进行处理,生成第一向量,对所述第一向量进行随机遮挡训练生成第二向量;对所述文本信 7 CN 111611409 A 说 明 书 4/17 页 息进行属性分析生成属性向量,将所述属性向量与所述第二向量结合,再次进行随机遮挡 训练生成第三向量;根据所述第三向量进行语篇关系训练,生成第四向量;根据场景表征模 型对所述第四向量进行场景知识优化,生成最终向量;根据所述最终向量生成分析结果,输 出所述分析结果。本说明书一个或多个实施例通过多步微调并结合场景知识的方式,使事 例分析及推断的精确度大幅度提高,大幅提高了对事例的表征能力和推理能力。 附图说明 为了更清楚地说明本说明书一个或多个实施例或现有技术中的技术方案,下面将 对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的 附图仅仅是本说明书一个或多个实施例,对于本领域普通技术人员来讲,在不付出创造性 劳动的前提下,还可以根据这些附图获得其他的附图。 图1为本说明书一个或多个实施例提出的整个事例叙述事例链条的示意图; 图2为本说明书一个或多个实施例提出的一种融入场景知识的事例分析方法的流 程示意图; 图3为本说明书一个或多个实施例提出的一种融入场景知识的事例分析设备的结 构示意图; 图4为本说明书一个或多个实施例提出的电子设备结构示意图。











