
技术摘要:
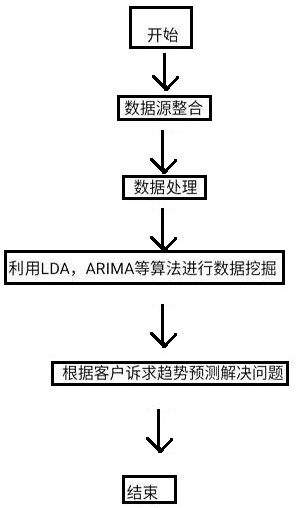
本发明涉及一种客户诉求趋势预警分析方法,通过引用客户工单数据,利用自然语言处理技术,将工单文本中的非结构化信息转换为结构化数据,然后把工单信息具体到工单类型,进而统计各类型工单的数量,以地市为单位统计近年来每个月各类型投诉工单的数量,将其作为训练数 全部
背景技术:
国网公司年度电网投资规模均超过5000亿元,今年以来公司提出要始终坚持“人 民电业为人民”的企业宗旨,如何使宝贵的资金产生最大价值,更好满足4.6亿电力客户对 供电质量的需求,应用客户评价信息支撑电网发展建设是关键之举。 现有电网建设项目主要根据电网速度与规模、安全与质量、效率与效益、经营与政 策等四大类指标安排项目计划,难以控制客户诉求的变化情况,加之客户诉求数据分散在 多个系统中,难以利用海量客户数据支撑电网工作安排。 中国发明专利CN108492033A涉及一种电网客户集中投诉智能预警方法。包括如下 过程:采集针对停电事件、电费事件、计量事件中任何一类的如下运行指标:咨询事件数、故 障报修事件数、意见事件数、投诉事件数、咨询事件变异程度、故障报修事件变异程度、意见 事件变异程度、投诉事件变异程度、一周内超过咨询事件均值的天数、一周内超过故障报修 事件均值的天数、一周内超过意见事件均值的天数、一周内超过投诉事件均值的天数;数据 标准化;使用熵值法计算二级指标的权重;使用层次分析法,计算一级指标的权重;将特定 区域的数据代入,得出结果。本发明可及时发现在相同地域、同一时间区格内,客户因为电 网业务所带来的集中投诉现象,以达到及时发现,迅速传递的目的。 中国发明专利CN106971310A提供了一种客户投诉数量预测方法及装置,用于对预 测包括当前日期的未来n天的电网客户投诉数量进行预测,方法包括:获取当前日期前的预 设时间段m天内各投诉类工单每天的投诉量数据作为基础数据;对基础数据进行时差处理 根据皮尔森相关系数确定各投诉类工单的时差指数;根据确定的时差指数和各投诉类工单 每天的投诉量数据确定各投诉类工单的预测原始数据;对确定的预测原始数据进行主成分 分析确定主成分数据;利用多层神经网络算法对确定的主成分数据进行计算确定预测值 集;对确定的预测值集求平均确定最终预测值作为包括当前日期的未来n天的电网客户投 诉数量。本发明可以有效的进行未来投诉数量的预测,提前预警投诉亦可提醒相关管理人 员,增加客户服务人员,提升应对大范围投诉能力。 中国发明专利CN109447364A公开了一种基于标签的电力客户投诉预测方法,包括 获取电力客户的历史数据并处理;采用机器学习算法训练训练数据,建立预测模型并得到 预测模型的精度;建立多模型加权联合预测模型;多模型加权联合预测模型预测电力客户 的投诉数据;过采样算法扩充进据;组建新的数据训练集,采用机器学习算法该训练新的训 练数据,建立预测模型并得到预测模型的精度;再次建立多模型加权联合预测模型;重复上 述步骤直至精度符合要求;采用得到的最终的多模型加权联合预测模型对电力客户的投诉 进行预测。本发明方法能够准确和快速的对电力系统的客户投诉情况进行预测,而且方法 简单可靠,科学方便。 本发明与以上发明同属于解决客户投诉预测问题的方法,均对客户投诉的趋势进 4 CN 111612230 A 说 明 书 2/8 页 行了研究,从客户投诉的基本内容信息为出发点,以解决客户的问题、更好的为电力客户服 务为最终目标,提供可靠高效的方法。
技术实现要素:
本发明的目的是提供一种客户诉求趋势预警分析方法,解决当前难以有效感知客 户诉求的变化趋势及监测的问题,构建客户诉求趋势预警分析方法,实现工单数量精准把 控,提前预警投诉高峰时段,辅助电网人员合理安排工作。 本发明的技术方案: 一种客户诉求趋势预警分析方法,通过引用客户工单数据,利用自然语言处理技 术,将工单文本中的非结构化信息转换为结构化数据,然后把工单信息具体到工单类型,进 而统计各类型工单的数量,以地市为单位统计近3-10年来每个月各类型投诉工单的数量, 将其作为训练数据并采用时间序列模型分别进行预测,所述时间序列模型进行季节解构, 得出各地市未来一两个月的各类型工单数量以及未来一段时间内的各类型工单的变化趋 势,进行分析,得出各地区未来的客户诉求数量及变化趋势,将分析结果推送至大数据交互 平台或用采系统,并将筛选结果存储于用电信息大数据分析平台的数据库服务器,将结果 展示给各级供电单位的监控终端。 进一步的,所述自然语言处理技术为NLP或LDA技术; 所述时间序列模型为AR、ARIMA或MA时间序列模型; 所述各级供电单位包括省、市、县、所各级供电单位。 进一步的,所述客户工单数据对海量客户的诉求内容情感偏好以及主题内容,进 行分析汇总,利用转换好的结构化数据参与计算,反映地区情况。 进一步的,所述工单的变化趋势反映各地区客户投诉的情况,与预测结果进行呼 应。 进一步的,NLP技术中的情感分析,数据语料的分词结果,进行情感指数分析,给出 用户工单的情感偏好得分,得出客户诉求的优先处理级别,进而辅助工单类型确定。 进一步的,LDA技术中的主题模型根据分词结果计算某些词对于文档的重要性,同 时在其他文档中出现相比于本文档少,具有区分能力,将关键词合并到原数据集即可得到 客户工单的主题,以便进行下一步的计算。 进一步的,所述的AR时间序列模型为自回归时间序列模型,利用前期数值与后期 数值的相关关系,相关关系为自相关,建立包含前期数值和后期数值的回归方程,达到预测 的目的;我们将白噪声理解成时间序列数值的随机波动,这些随机波动的总和等于0,AR是 线性时间序列分析模型中较为简洁的模型,模型的最高阶大于0,随机干扰序列为零均值白 噪声序列且当期的随机干扰与过去的序列值无关。 进一步的,所述MA时间序列模型为移动平均模型时间序列模型,某个时间点的指 标数值等于白噪声序列的加权和,如果回归方程中,白噪声只有两项,那么该移动平均过程 为2阶移动平均过程MA(2);比较自回归过程和移动平均过程可知,移动平均过程作为自回 归过程的补充,解决自回归方差中白噪声的求解问题。 进一步的,所述ARIMA时间序列模型为差分自回归移动平均模型时间序列模型,以 ARMA模型为基础,结合了两个模型的特点,在ARMA模型中,自回归过程负责量化当前数据与 5 CN 111612230 A 说 明 书 3/8 页 前期数据之间的关系,移动平均过程负责解决随机变动项的求解问题。 进一步的,所述季节解构采用时间序列加法模型,时间序列加法模型是利用X-11 滑动平均的方法,将原始时间序列分解为季节分量,周期循环分量,不规则分量和趋势分 量;其形式包括加法模型、乘法模型、对数加法模型和伪加法模型,将时间序列的数据进行 精细化分解。 与现有技术相比,本发明优点如下: 本发明整个分析过程无需人工干预,节约了大量的人力资源,同时还提高了分析 结果的准确性,提升了用户体验,无需额外设备投资,使资金价值最大化,达到了降本增效 的目的。 本发明首次引进PMS系统、95598客服等工单数据,开展了多系统客户诉求间的数 据融合,破解专业间的数据孤岛,建立了各地区的历史客户诉求档案信息,具有较强的复用 性及扩展性。 本发明在处理客户诉求工单数据时,使用了基于NLP的文本分类技术,对客户的受 理内容进行了深度挖掘,相比现有工单分类体系可获取更详细的客户诉求关键词信息,准 确抓住客户反映关键信息,提升了工单分类的全面性和准确性。 本发明在ARIMA时间序列模型构建时,解决了传统时间序列模型不能够用于齐次 非平稳时间序列的分析的情况,即面对多样化的工单数据,使得模型泛化能力大大提升。 附图说明 图1为本发明的工作流程图; 图2为本发明的实施框架图。











