
技术摘要:
一种基于卷积神经网络和时间序列图的司机行为识别方法:采集司机驾驶视频,建立司机行为数据集;基于司机行为数据集,采用卷积神经网络方法,通过网络训练获得司机行为识别模型;采集司机的实时工作视频并按照预设的帧率提取出连续的多帧图像,将多帧图像输入所述司机 全部
背景技术:
在中国经济高速发展的今天,人们对出行的要求越来越高,给城市交通带来了巨 大的压力。而城市交通运营规模不断扩大。在城市交通车辆的安全运营的环节中,司机安全 作业是其中关键的一部分,它直接关系到乘客的安全问题。然而,司机在运营过程中存在着 许多安全隐患。如司机的业务水平、心理素质及身体素质,或者设备的不可靠状态都将会给 乘客带来重大安全问题。 目前,在主要城市的车辆上都配有视频监控设备,此设备将监控司机的视频数据 存入到该装置的存储器内,然后再将存储数据下载到地面设备,进行后期人工处理分析,但 这种人工分析监控录像的方式需要大量的地面视频数据分析人员和设备,劳动强度大,耗 费人力物力且效率低,并且缺乏对司机行为实时预警处理,不能对司机在机车行为过程中 不当行为进行提醒,交通运营管理部门的实际要求无法满足。 随着人工智能的发展,深度学习在图像识别和特征提取方面显示了突出的能力。 深度神经网络算法的成熟也使得它在交通领域的应用研究受到了越来越多的关注。深度神 经网络是由神经元组成,它们可以学习基于逐步分层抽象的复杂模型。并充分发挥了神经 网络的自学习能力,通过训练不断更新权重,以原始数据作为算法输入,通过算法将其逐层 抽象为所需要的特征表示,它避免了人工选择特征,比传统的行为识别方法具有更好的识 别效果。 为解决上述缺陷,许多研究学者运用传统的图像处理技术手工提取特征,这涉及 到繁琐的特征提取和参数调整过程。另外一些学者考虑将深度学习运用到司机行为识别 中,但图像的二维特征往往不能很好的表达视频的三维特征。
技术实现要素:
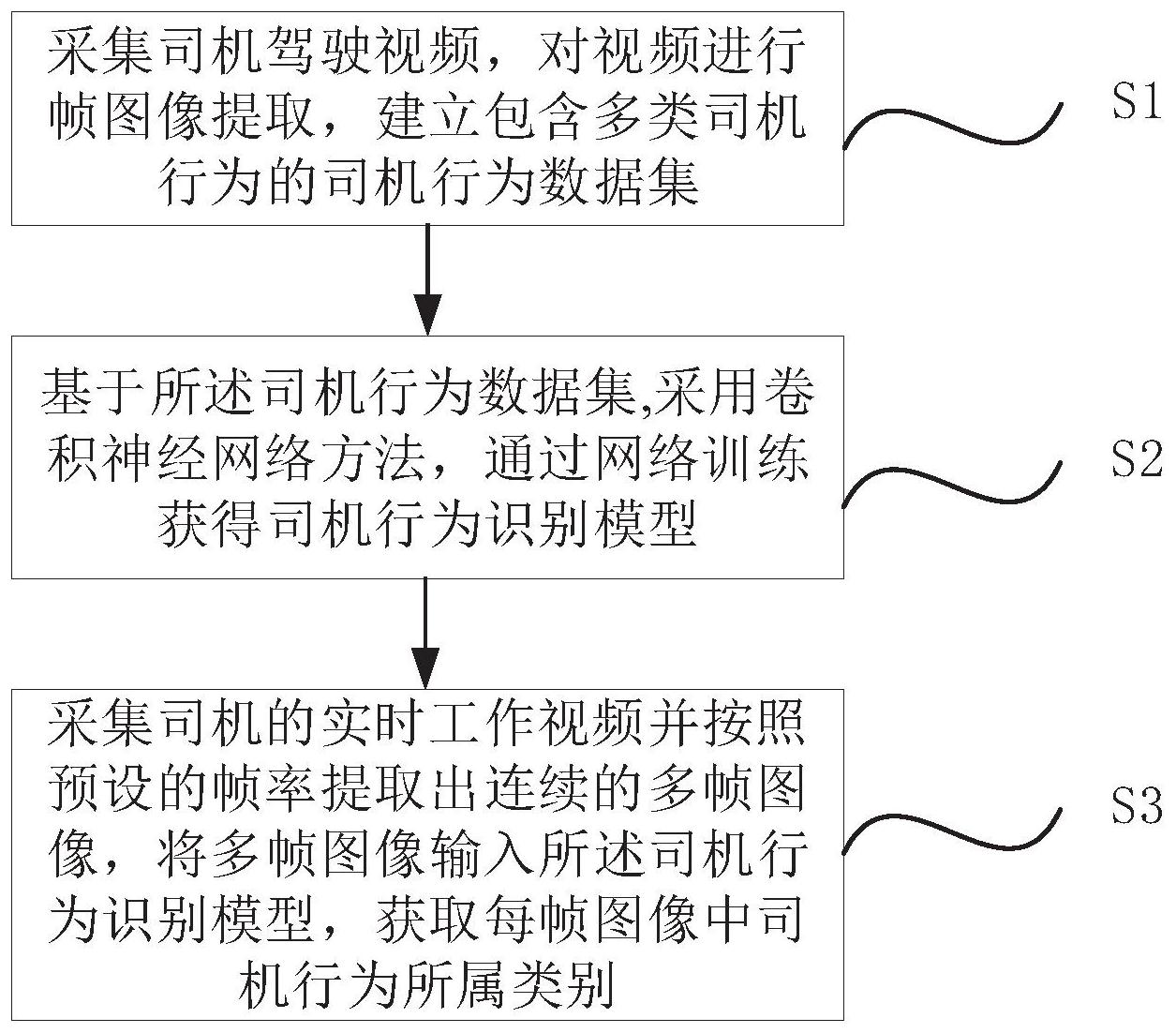
本发明提供了一种基于卷积神经网络和时间序列图的司机行为识别方法。 目的一,能准确识别司机驾驶过程中的几类行为; 目的二,评价司机行为是否规范; 目的三,分析车辆的运行状态。 为了实现上述目的,本发明提供了一种基于卷积神经网络和时间序列图的司机行 为识别方法,包括: (1):采集司机驾驶视频,对视频进行帧图像提取,建立包含多类司机行为的司机 行为数据集; (2):基于所述司机行为数据集,采用卷积神经网络方法,通过训练获得司机行为 识别模型; (3):采集司机的实时工作视频并按照预设的帧率提取出连续的多帧图像,将多帧 5 CN 111553209 A 说 明 书 2/7 页 图像输入所述司机行为识别模型,识别每帧图像中司机行为所属类别。 本发明还包括司机行为是否规范评价步骤,具体包括;(4):以所述帧图像的帧数 为横坐标,每帧图像中司机行为所属类别为纵坐标,绘制司机行为时间序列图;(5):通过时 间序列图获得视频中司机每类行为出现次数以及持续时长,并判断司机行为是否规范。 本发明还包括运行状态分析步骤(6):依据时间序列图得到视频中车辆的运行状 态。 步骤(1),数据集的构建包括: (1a)使用摄像头采集司机的标准工作视频,并在采集过程结束后从所述标准工作 视频中按等间隔的方式均匀提取出图像帧; (1b)对所述图像帧中的司机行为分类,并按照分类顺序分别对每类图像打上标 签,生成司机行为数据集。 步骤(2),司机识别模型的建立包括: (2a)样本准备,将样本分为训练集和测试集; (2b)构建卷积神经网络结构; (2c)将训练集图像导入步骤(2b)建立的卷积神经网络结构中进行训练; (2d)训练完成,得到训练精度高的卷积神经网络,即得到司机行为识别模型。 步骤(2b)中,所述卷积神经网络结构如下: (2b1)以Alexnet结构为基础,网络包括五个Convolutional层(卷积层)、三个 MaxPooling层(最大池化层)、三个Dense层(全连接层); (2b2)所述Convolutional层提取原始图像的基本特征,如颜色、纹理、形状等;所 述MaxPooling层采用最大池化的方法,对前一层进行最大采样,滑窗大小为3×3,步长为2; 所述Dense层将经过Convolutional层和MaxPooling层的特征表示映射到数据样本的标记 层。网络计算出前一层的输出向量和连接权重向量的内积,然后再加上偏置,经过激活函数 的运算后会得到整个网络的一个输出状态;所述激活函数公式如下: 其中,J×I为卷积核的宽和高的大小尺寸,M×N为输入图像的宽和高大小,xm,n表 示在输入图片中(m,n)位置处的像素值,ym′,n′则代表其对应的计算结果;w为权重,表示对应 特征x的影响大小;f为激活函数,对内积进行非线性的变换;b为偏置,其作用为选择分界 线。 (2b3)第一层为96个卷积核大小为11×11的Convolutional层,步长为4;第二、四、 八层是MaxPooling层;第三、五至七层是4个Convolutional层,卷积核大小为3×3,步长为 1,卷积核的个数分别为96、384、384、256个;第九至十一层是Dense层,输出4096维信息,得 到分类概率结果。 步骤(2c)中,卷积神经网络的训练方法: (2c1)将图像帧输入卷积神经网络中,在卷积神经网络中,首先Convolutional层 对输入层进行卷积运算和激活操作,以提取输入层的行为空间特征;所述激活函数采用 RELU函数,公式如下所示: 6 CN 111553209 A 说 明 书 3/7 页 f(x)=max(0,x) 其中,x是输入向量;RELU函数对输入向量进行单侧抑制。 (2c2)通过MaxPooling层对Convolutional层的行为空间特征进行池化操作,用于 压缩数据和参数的数量,减小过拟合; (2c3)根据(2b)的网络结构,对卷积神经网络逐层重复(2c1)、(2c2)两个步骤,重 复多次,直至Dense层,Dense层将尺寸为36*36*256的输入数据进行全连接运算,通过RELU 激活函数与Dropout运算生成维度为4096的输出向量;所述全连接层的输出向量经softmax 函数计算得到最后的预测值,使用交叉熵损失,函数计算所述预测值与真实值的损失函数 值,并最小化损失函数值; (2c4)通过随机梯度下降法不断调整网络权重和偏置,重新计算损失函数值,直至 损失函数值趋于稳定或到达设定的迭代次数,获得分类后的图片特征。 本发明具体使用了SGD随机梯度下降法。 步骤(3)中,司机识别模型识别司机行为所属类别: (3a)将司机视频按等间隔5帧的方式进行帧序列提取,将所述连续监控图像输入 所述司机行为识别模型; (3b)模型输出是概率数组,概率数组中的每一个元素值分别表示对应行为的概 率,其中分别表示属于六类行为的概率。识别结果的计算公式为: Result=argmax(Ri),i=1,2,3,... 其中,i是图像的帧的数目,并且Ri是每个图像的概率数组,argmax函数是找到对 应于概率数组中的最大概率的标签,并将标签作为分类结果。 步骤(4)所述绘制司机行为时间序列图: (4a)连续的图像必须是一个时间序列,每帧图像的识别结果计算公式如下: Result=argmax(Ri),i=1,2,3,... 其中i表示帧数,Ri是每个图像的概率数组,Result表示行为分类结果。 (4b)本发明以帧数i为横坐标,以得到的行为分类结果Result为纵坐标,构造时间 序列图; 步骤(5)获取司机行为情况: (5a)计算时间序列图中每个Result值持续出现的次数, suma=enumerate(i|Result=a),a=0,1,2,3,4,5 (5b)计算每次行为的持续时长,计算公式如下: L为每次行为的总帧数,FPS指每秒传输帧数 (5c)根据Result值对应的行为类别,得到一段视频内司机每类行为发生的次数以 及每次的持续时长; (5d)判断时间序列图中司机一系列行为操作是否符合司机作业标准化操作手册 中司机的操作顺序,以此结果判断司机行为是否规范。 步骤(6)所述获取车辆运行情况包括以下步骤: (6a)分析车辆停止时的司机行为,将司机行为开始的起始帧数为fa,终结帧数为 fb,停站间隔时间计算为: 7 CN 111553209 A 说 明 书 4/7 页 FPS指每秒传输帧数 (6b)车辆下一次停靠站台时所在的帧数为fc,车辆运行时间公式计算为: 依据所述车辆运行时间公式即可得到车辆运行时间。 本发明提出的一种基于卷积神经网络和时间序列图的司机行为识别方法,能准确 识别司机驾驶过程中的几类行为和车辆运行状态,并评价司机行为是否规范。将本发明进 行市场应用推广,可转化为一个智能识别司机的驾驶行为的预警系统,实现视频自动化检 索,提高分析司机行为的效率,从而提高行车安全。 附图说明 为了更清楚地说明本发明











