 技术摘要:
技术摘要: 本发明涉及一种基于自监督的机器翻译译文自动优化的方法和系统,属于机器翻译领域。所述方法包括以下步骤:步骤一、使用大规模平行语料对模型进行训练,使模型学习替换操作;步骤二、使用人工构造的伪数据对模型进行训练,使模型学习插入操作,得到训练好的模型;步骤 全部
背景技术:
机器翻译是利用计算机程序将文字或语音从一种自然语言翻译成另一种自然语
言的技术。机器翻译译文质量在近年来,特别是在神经机器翻译出现后有很大的提高,但其
整体质量与人工译文相比仍有较大差距,机器译文需要进行一定的优化才能作为合格的译
文使用。机器翻译译文的优化技术大概可以分为两种:一种是在原译文的基础上引入其他
翻译结果进行译文的融合优化,如引入多种机器翻译系统的翻译结果;另一种是采用后处
理的思想,修改当前译文的瑕疵,类似人工翻译过程中的译后编辑(Post Editing ,PE),故
称为自动后编辑(Automatic Post Editing,APE)。本专利采取的技术路线是一种自动后编
辑策略。
译后编辑一般由受过专业训练的人类专家进行,但随着翻译任务规模的增加,人
类译后编辑的过程非常昂贵且费时。对于机器翻译来说,其中的翻译错误呈现一定的规律
性,针对这些错误所需的后编辑操作也是有规律可循的,因此人们提出了自动后编辑这一
技术思路。译文自动后编辑往往需要大量的机器翻译结果和译后编辑形成可接受译文,利
用某种学习策略训练建立后编辑模型,实现自动纠正机器翻译译文中出现的错误。
早期的自动后编辑主要是基于规则的方法。Allen和Hogan等人(2000)将自动后编
辑系统定义为一个能自动从包含源语言、机器译文和目标语译文的“三语平行语料库”中自
动的学习后编辑规则的方法。Elming提出了一种基于转换学习的方法(Transformation-
based learning,TBL),自动的从“三语”语料库中学习修改规则,并将其运用于待编辑译
文。
Simard等人(2007)沿用统计机器学习的思想,将自动后编辑看作将“机器语言(译
文)”翻译成“自然语言(人工译文)”的过程。具体技术上就是训练一个基于短语的单语统计
机器翻译系统,将待优化的机器译文视作源语言句子,人工译文视作目标端句子对模型进
行训练。Béchara等人(2011)则再此基础上解决了后编辑短语与源语言之间信息失去联系
的缺陷,提出了基于源语言对齐的模型。在该模型中,Béchara等人引入源语言句子并把它
作为APE的上下文来构建机器翻译系统,源语言和机器翻译结果之间的对齐信息被引入到
统计后编辑模型中。
深度学习出现后,各种神经机器翻译模型也和统计翻译模型一样,被用于解决自
动后编辑问题。Pal等人提出利用双向循环神经网络编码器-解码器模型建立一个单语机器
翻译系统完成APE任务,与基于短语的统计后编辑模型相比,该方法极大提高了APE的效果。
Junczys-Dowmunt等人和Tebbifakhr等人将Transformer模型引入到自动后编辑
任务中,同样采取了两个编码器和一个解码器的架构;Correia等人利用BERT模型处理自动
后编辑问题,将BERT作为多语言的编码器并对BERT模型进行修改,使其能作为解码器使用,
5
CN 111597778 A 说 明 书 2/11 页
在多个数据集上取得了当前最好的效果。
上述APE模型的共同特性是都是系统依赖的,即对于特定机器翻译系统,利用它所
产生的双语句对进行预训练的APE模型在该系统上有很好的性能,但对于其他翻译系统却
效果骤降。本专利提出一个通用的机器翻译自动后编辑模型,对所有机器翻译系统译文都
具有较好的优化能力。
技术实现要素:
本发明的目的是提出了一种基于自监督的机器翻译译文自动优化的方法和系统,
可以解决机器翻译中的错译与漏译问题,且不受后编辑数据规模的限制,且模型的并行性
高。
一种基于自监督的机器翻译译文自动优化的方法,所述方法包括以下步骤:
步骤一、使用大规模平行语料对模型进行训练,使模型学习替换操作;
步骤二、使用人工构造的伪数据对模型进行训练,使模型学习插入操作,得到训练
好的模型;
步骤三、使用训练好的模型对待优化的译文中的每个词和词间空隙进行候选词预
测,完成替换和插入的后编辑操作。
进一步的,在步骤一中,包括以下步骤:
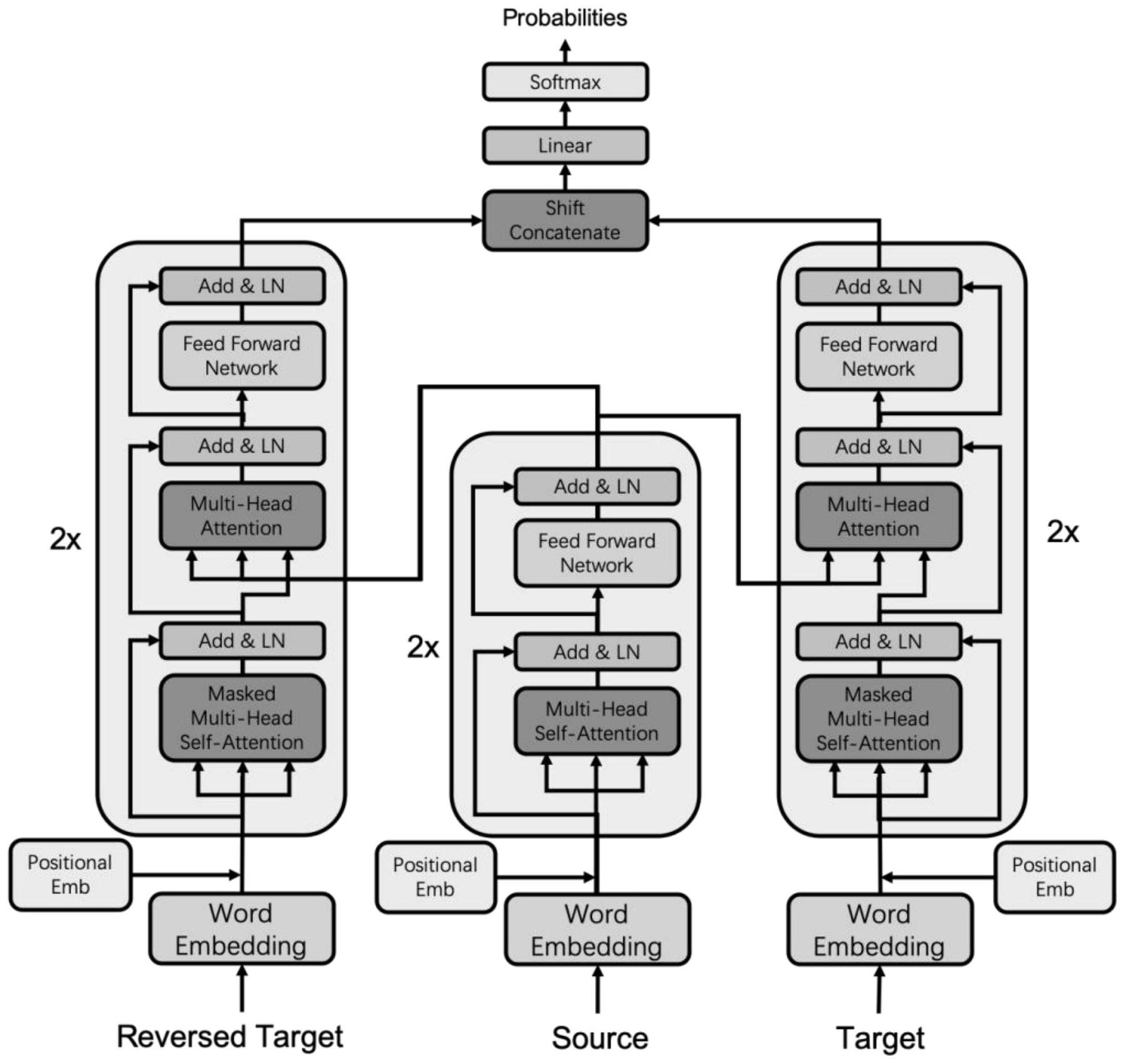
步骤一一、使用编码器对源语言句子S进行编码;
步骤一二、使用正向反向两个解码器对目标端句子T进行编码,将两个解码器的输
出进行移位拼接,将两个解码器的输入词向量进行移位拼接,将两次移位拼接的结果进行
拼接,得到特征向量;
步骤一三、使用特征向量对目标端的每个词进行预测,使用预测的结果与实际的
输入计算损失,进行误差回传,训练网络参数。
进一步的,在步骤二中,包括以下步骤:
步骤二一、构造伪数据:随机删除句子中的词,对句子中词之间的空隙进行标注,
假设经过随机删除后的句子长度为N,则空隙包括句子起始位置和每个词后的位置共N 1
个,针对某个空隙,若其对应某一被删除的词,则空隙标签为该词,否则为标识符
表
示空;
步骤二二、使用伪数据进行模型训练,其中编码器对源语言句子S进行编码,正向
反向两个解码器对目标端句子T进行编码,将正向反向两个解码器的输出进行移位拼接,将
正向反向两个解码器的输入词向量进行移位拼接,将两次移位拼接的结果进行拼接,作为
每个词的向量表示,而词间空隙的表示则由该空隙两端词的表示拼接而成,由此得到每个
空隙的特征向量;
步骤二三、使用特征向量对每个词间空隙进行预测,使用预测的结果与实际的输
入计算损失,进行误差回传,训练网络参数。
进一步的,在步骤三中,包括以下步骤:
步骤三一、使用编码器对源语言句子S进行编码;
步骤三二、使用正向反向两个解码器对目标端句子T进行编码,将两个解码器的输
出进行移位拼接,将两个解码器的输入词向量进行一位拼接,将两次移位拼接的结果进行
6
CN 111597778 A 说 明 书 3/11 页
拼接,得到特征向量;
步骤三三、使用特征向量对机器译文中每个词和词间空隙进行预测,完成插入和
替换的后编辑操作。
一种基于自监督的机器翻译译文自动优化的系统,基于上述的一种基于自监督的
机器翻译译文自动优化的方法,所述系统包括:
伪数据构造模块,用于模型的训练,使模型学习插入操作;
训练模块,用于对模型进行训练,使模型学习替换操作和插入操作,得到训练好的
模型;
通用系统预测模块,用于使用训练好的模型对待优化的译文中的每个词和词间空
隙进行候选词预测,完成替换和插入的后编辑操作。
进一步的,所述模型采用序列到序列架构,包括一个编码器和正向反向两个解码
器,其中编码器采用Transformer模型的编码器,共两层,每层包括两部分,第一部分为多头
自注意力层,第二部分为前馈神经网络,每个解码器采用Transformer模型的解码器,共两
层,每层由三部分组成,第一部分为多头的自注意力层,第二部分为源端注意力层,第三部
分为前馈神经网络。
进一步的,所述训练模块包括替换操作训练模块和插入操作训练模块,其中,
所述替换操作训练模块:设模型隐层大小为dmodel,序列长度为T,将正反向解码器
输出进行移位拼接得到T×2dmodel大小的向量,将正反向解码器输入词向量进行移位拼接得
到T×2dmodel大小的向量,将两次移位拼接结果进行拼接,得到T×4dmodel大小的特征向量,
使用特征向量与大小为4dmodel×V的输出权重矩阵相乘,得到大小为T×V的向量,进行
softmax计算,得到每个位置在词表上的概率分布,并与实际的词的分布进行交叉熵损失计
算,
其中p(x)表示真实的词分布,q(x)表示预测的词分布;
所述插入操作训练模块:由于要对词之间的空隙进行预测,对于每个空隙,使用其
左右两个词的向量拼接作为表示向量,长度为N的句子,共有N 1个词间空隙(包括句子起始
和结束位置),故得到的词间空隙的向量大小为(T 1)×8dmodel,与大小为8dmodel×V的输出
权重矩阵相乘,得到大小为(T 1)×V的向量,进行softmax函数计算,得到其在词表上的概
率分布,与真实的标签分布计算交叉熵损失。
进一步的,所述通用系统预测模块包括特征抽取模块和后编辑模块,其中,
所述特征抽取模块:输入源语言句子S和机器译文M,编码器编码S,正向反向两个
解码器对M进行编码,得到正向反向两个解码器的输出,每个输出的大小为T×dmodel,将两个
解码器的输出的最后一个位置的向量删除,得到两个大小为(T-1)×dmodel的向量,再将这两
个向量进行移位拼接,得到大小为T×2dmodel的向量。为了使模型获取到原始词向量的信息,
将两个编码器的输入也进行如上的移位拼接操作,得到大小为T×2dmodel的向量。最后将两
次移位拼接的向量进行拼接,得到大小为T×4dmodel的向量,作为每个词的特征向量使用;
所述后编辑模块:使用模型对译文中的词和词间空隙进行预测,对于替换词预测,
将特征向量与大小为4dmodel×V的输出权重矩阵相乘,得到大小为T×V的向量,对其进行
7
CN 111597778 A 说 明 书 4/11 页
softmax函数计算,得到每个位置在词表上的概率分布,取概率值最大的词,若该词与机器
译文中的词相同则不修改译文,若不同则将译文中对应位置的词替换为模型预测的词,完
成替换操作;
对于词间空隙的预测,使用其左右两个词的向量拼接作为表示向量,长度为N的句
子,共有N 1个词间空隙(包括句子起始和结束位置),故得到的词间空隙的向量大小为(T
1)×8dmodel,与大小为8dmodel×V的输出权重矩阵相乘,得到大小为(T 1)×V的向量,进行
softmax函数计算,得到其在词表上的概率分布,取概率最大的词,若预测得到标识符<
blank>则表示不插入词,若为其他词则表示该位置应插入模型预测的词,完成插入操作。
本发明的主要优点是:本发明的一种基于自监督的机器翻译译文自动优化的方法
和系统,可以解决机器翻译中的错译与漏译问题。模型首先使用大规模的平行语料进行训
练,训练目标为对目标端句子中的每个词进行预测,这样可以使模型学会对错误翻译的词
进行改正。然后模型使用人工构造的伪数据进行训练,训练目标为对目标端句子中的词与
词之间的空隙进行预测,判断空隙处是否需要插入词,这样可以使模型学会对漏译的情况
进行改正。且本发明的发明的优点在于不受后编辑数据规模的限制,而是直接从大规模平
行语料中学习知识,实现对译文中的每个词和词隙进行编辑。此外模型的并行性较高,编辑
操作之间不存在时序上的先后顺序,在预测速度上优于传统的基于自回归的
(autoregressive)的自动后编辑模型。同时本专利突破了传统基于深度学习的APE技术系
统依赖的缺陷,在不同机器翻译系统上具备相同的性能,是一种通用的机器翻译自动后编
辑方法。
附图说明
图1为本发明所述的一种基于自监督的机器翻译译文自动优化的方法的模型架构
图;
图2为本发明所述的一种基于自监督的机器翻译译文自动优化的方法的模型示意
图;
图3为本发明所述的一种基于自监督的机器翻译译文自动优化的系统的架构图;
图4为训练模块的流程图;
图5为预测模块流程图。












